






语音情感识别,python
CNN,LSTM,CNN-LSTM,以及加注意力机制这几种算法
附有数据集和代码,
数据集:英文数据集
CASIA语音情感数据集是提取好特征的文件
也可根据你的数据集修改模型的输入
构建语音情感识别系统,同学们。你们可 使用CNN、LSTM、CNN-LSTM以及带有注意力机制的模型。以下是详细的代码实现和说明,包括数据加载、模型构建、训练和评估。
1. 数据准备
首先,我们需要加载CASIA语音情感数据集,并进行预处理。
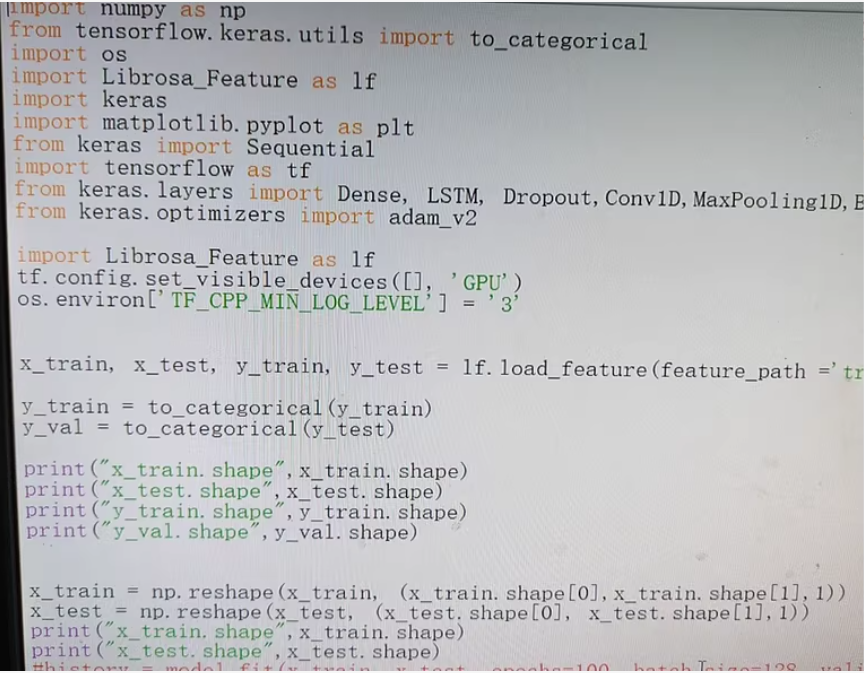
import numpy as np
from tensorflow.keras.utils import to_categorical
import os
import keras
import matplotlib.pyplot as plt
from keras.models import Sequential
from keras.layers import Dense, LSTM, Dropout, Conv1D, MaxPooling1D, Flatten, TimeDistributed, Bidirectional
from keras.optimizers import Adam
from Librosa_Feature import load_feature # 假设这是你自定义的特征加载模块
# 加载特征和标签
x_train, x_test, y_train, y_test = load_feature(feature_path='path/to/feature')
# 将标签转换为one-hot编码
y_train = to_categorical(y_train)
y_val = to_categorical(y_test)
print("x_train.shape", x_train.shape)
print("x_test.shape", x_test.shape)
print("y_train.shape", y_train.shape)
print("y_val.shape", y_val.shape)
# 重塑输入数据以适应模型
x_train = np.reshape(x_train, (x_train.shape[0], x_train.shape[1], 1))
x_test = np.reshape(x_test, (x_test.shape[0], x_test.shape[1], 1))
print("x_train.shape", x_train.shape)
print("x_test.shape", x_test.shape)
2. 模型构建
2.1 CNN模型
def build_cnn_model(input_shape, num_classes):
model = Sequential()
model.add(Conv1D(64, kernel_size=3, activation='relu', input_shape=input_shape))
model.add(MaxPooling1D(pool_size=2))
model.add(Dropout(0.5))
model.add(Conv1D(128, kernel_size=3, activation='relu'))
model.add(MaxPooling1D(pool_size=2))
model.add(Dropout(0.5))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer=Adam(), metrics=['accuracy'])
return model
input_shape = (x_train.shape[1], 1)
num_classes = y_train.shape[1]
cnn_model = build_cnn_model(input_shape, num_classes)
2.2 LSTM模型
def build_lstm_model(input_shape, num_classes):
model = Sequential()
model.add(LSTM(64, return_sequences=True, input_shape=input_shape))
model.add(Dropout(0.5))
model.add(LSTM(64))
model.add(Dropout(0.5))
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer=Adam(), metrics=['accuracy'])
return model
input_shape = (x_train.shape[1], 1)
lstm_model = build_lstm_model(input_shape, num_classes)
2.3 CNN-LSTM模型
def build_cnn_lstm_model(input_shape, num_classes):
model = Sequential()
model.add(TimeDistributed(Conv1D(64, kernel_size=3, activation='relu'), input_shape=input_shape))
model.add(TimeDistributed(MaxPooling1D(pool_size=2)))
model.add(TimeDistributed(Dropout(0.5)))
model.add(TimeDistributed(Conv1D(128, kernel_size=3, activation='relu')))
model.add(TimeDistributed(MaxPooling1D(pool_size=2)))
model.add(TimeDistributed(Dropout(0.5)))
model.add(TimeDistributed(Flatten()))
model.add(LSTM(64, return_sequences=True))
model.add(Dropout(0.5))
model.add(LSTM(64))
model.add(Dropout(0.5))
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer=Adam(), metrics=['accuracy'])
return model
input_shape = (x_train.shape[1], 1, 1)
cnn_lstm_model = build_cnn_lstm_model(input_shape, num_classes)
2.4 CNN-LSTM带注意力机制模型
from keras.layers import Attention
def build_cnn_lstm_attention_model(input_shape, num_classes):
model = Sequential()
model.add(TimeDistributed(Conv1D(64, kernel_size=3, activation='relu'), input_shape=input_shape))
model.add(TimeDistributed(MaxPooling1D(pool_size=2)))
model.add(TimeDistributed(Dropout(0.5)))
model.add(TimeDistributed(Conv1D(128, kernel_size=3, activation='relu')))
model.add(TimeDistributed(MaxPooling1D(pool_size=2)))
model.add(TimeDistributed(Dropout(0.5)))
model.add(TimeDistributed(Flatten()))
model.add(Bidirectional(LSTM(64, return_sequences=True)))
model.add(Attention())
model.add(Dropout(0.5))
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer=Adam(), metrics=['accuracy'])
return model
input_shape = (x_train.shape[1], 1, 1)
cnn_lstm_attention_model = build_cnn_lstm_attention_model(input_shape, num_classes)
3. 训练模型
history_cnn = cnn_model.fit(x_train, y_train, epochs=100, batch_size=128, validation_data=(x_test, y_val))
history_lstm = lstm_model.fit(x_train, y_train, epochs=100, batch_size=128, validation_data=(x_test, y_val))
history_cnn_lstm = cnn_lstm_model.fit(x_train, y_train, epochs=100, batch_size=128, validation_data=(x_test, y_val))
history_cnn_lstm_attention = cnn_lstm_attention_model.fit(x_train, y_train, epochs=100, batch_size=128, validation_data=(x_test, y_val))
4. 评估模型
scores_cnn = cnn_model.evaluate(x_test, y_val, verbose=0)
print(f"CNN Test Accuracy: {scores_cnn[1]*100:.2f}%")
scores_lstm = lstm_model.evaluate(x_test, y_val, verbose=0)
print(f"LSTM Test Accuracy: {scores_lstm[1]*100:.2f}%")
scores_cnn_lstm = cnn_lstm_model.evaluate(x_test, y_val, verbose=0)
print(f"CNN-LSTM Test Accuracy: {scores_cnn_lstm[1]*100:.2f}%")
scores_cnn_lstm_attention = cnn_lstm_attention_model.evaluate(x_test, y_val, verbose=0)
print(f"CNN-LSTM with Attention Test Accuracy: {scores_cnn_lstm_attention[1]*100:.2f}%")
5. 可视化训练过程
def plot_history(history):
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(history.history['accuracy'], label='Train Accuracy')
plt.plot(history.history['val_accuracy'], label='Validation Accuracy')
plt.legend()
plt.title('Accuracy over Epochs')
plt.subplot(1, 2, 2)
plt.plot(history.history['loss'], label='Train Loss')
plt.plot(history.history['val_loss'], label='Validation Loss')
plt.legend()
plt.title('Loss over Epochs')
plt.show()
plot_history(history_cnn)
plot_history(history_lstm)
plot_history(history_cnn_lstm)
plot_history(history_cnn_lstm_attention)
了从数据加载到模型训练、评估和结果可视化的完整流程。同学们可以根据实际需求调整参数和模型结构。
完善语音特征提取函数,并结合前面的模型构建和训练流程。以下是完整的代码实现,包括特征提取、数据加载、模型构建、训练和评估。
仅供参考
1. 特征提取
首先,我们需要完成features函数,用于从音频信号中提取特征。
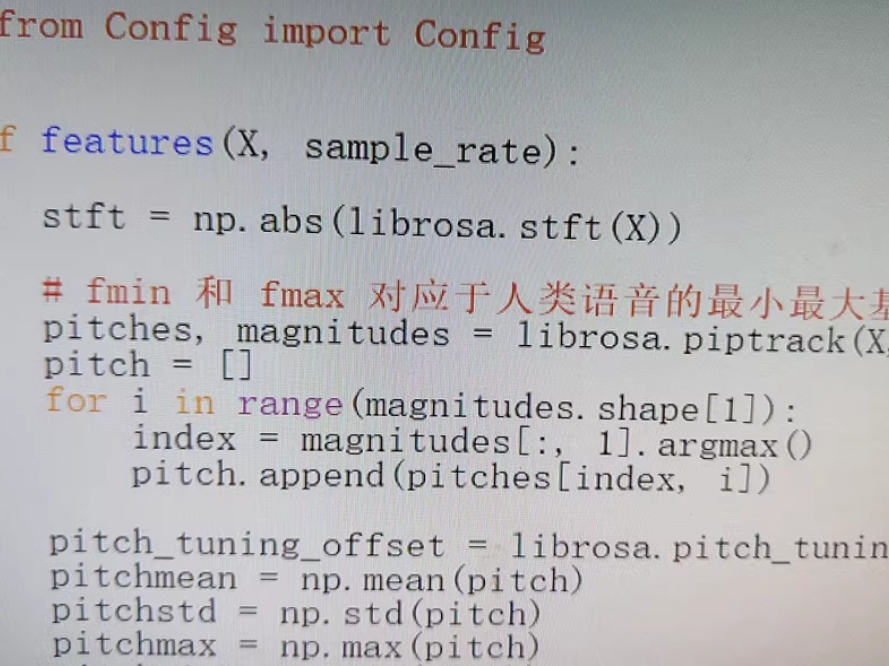
import numpy as np
import librosa
def features(X, sample_rate):
stft = np.abs(librosa.stft(X))
# fmin 和 fmax 对应于人类语音的最小最大基频
pitches, magnitudes = librosa.piptrack(X, sr=sample_rate, S=stft)
pitch = []
for i in range(magnitudes.shape[1]):
index = magnitudes[:, i].argmax()
pitch.append(pitches[index, i])
pitch_tuning_offset = librosa.pitch_tuning(pitches)
pitchmean = np.mean(pitch)
pitchstd = np.std(pitch)
pitchmax = np.max(pitch)
pitchmin = np.min(pitch)
return {
'pitch_tuning_offset': pitch_tuning_offset,
'pitchmean': pitchmean,
'pitchstd': pitchstd,
'pitchmax': pitchmax,
'pitchmin': pitchmin
}
2. 数据加载与预处理
接下来,我们将使用上述特征提取函数来加载和预处理数据集。
from Librosa_Feature import load_feature # 假设这是你自定义的特征加载模块
# 加载特征和标签
x_train, x_test, y_train, y_test = load_feature(feature_path='path/to/feature')
# 将标签转换为one-hot编码
y_train = to_categorical(y_train)
y_val = to_categorical(y_test)
print("x_train.shape", x_train.shape)
print("x_test.shape", x_test.shape)
print("y_train.shape", y_train.shape)
print("y_val.shape", y_val.shape)
# 重塑输入数据以适应模型
x_train = np.reshape(x_train, (x_train.shape[0], x_train.shape[1], 1))
x_test = np.reshape(x_test, (x_test.shape[0], x_test.shape[1], 1))
print("x_train.shape", x_train.shape)
print("x_test.shape", x_test.shape)
3. 模型构建
3.1 CNN模型
def build_cnn_model(input_shape, num_classes):
model = Sequential()
model.add(Conv1D(64, kernel_size=3, activation='relu', input_shape=input_shape))
model.add(MaxPooling1D(pool_size=2))
model.add(Dropout(0.5))
model.add(Conv1D(128, kernel_size=3, activation='relu'))
model.add(MaxPooling1D(pool_size=2))
model.add(Dropout(0.5))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer=Adam(), metrics=['accuracy'])
return model
input_shape = (x_train.shape[1], 1)
num_classes = y_train.shape[1]
cnn_model = build_cnn_model(input_shape, num_classes)
3.2 LSTM模型
def build_lstm_model(input_shape, num_classes):
model = Sequential()
model.add(LSTM(64, return_sequences=True, input_shape=input_shape))
model.add(Dropout(0.5))
model.add(LSTM(64))
model.add(Dropout(0.5))
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer=Adam(), metrics=['accuracy'])
return model
input_shape = (x_train.shape[1], 1)
lstm_model = build_lstm_model(input_shape, num_classes)
3.3 CNN-LSTM模型
def build_cnn_lstm_model(input_shape, num_classes):
model = Sequential()
model.add(TimeDistributed(Conv1D(64, kernel_size=3, activation='relu'), input_shape=input_shape))
model.add(TimeDistributed(MaxPooling1D(pool_size=2)))
model.add(TimeDistributed(Dropout(0.5)))
model.add(TimeDistributed(Conv1D(128, kernel_size=3, activation='relu')))
model.add(TimeDistributed(MaxPooling1D(pool_size=2)))
model.add(TimeDistributed(Dropout(0.5)))
model.add(TimeDistributed(Flatten()))
model.add(LSTM(64, return_sequences=True))
model.add(Dropout(0.5))
model.add(LSTM(64))
model.add(Dropout(0.5))
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer=Adam(), metrics=['accuracy'])
return model
input_shape = (x_train.shape[1], 1, 1)
cnn_lstm_model = build_cnn_lstm_model(input_shape, num_classes)
3.4 CNN-LSTM带注意力机制模型
from keras.layers import Attention
def build_cnn_lstm_attention_model(input_shape, num_classes):
model = Sequential()
model.add(TimeDistributed(Conv1D(64, kernel_size=3, activation='relu'), input_shape=input_shape))
model.add(TimeDistributed(MaxPooling1D(pool_size=2)))
model.add(TimeDistributed(Dropout(0.5)))
model.add(TimeDistributed(Conv1D(128, kernel_size=3, activation='relu')))
model.add(TimeDistributed(MaxPooling1D(pool_size=2)))
model.add(TimeDistributed(Dropout(0.5)))
model.add(TimeDistributed(Flatten()))
model.add(Bidirectional(LSTM(64, return_sequences=True)))
model.add(Attention())
model.add(Dropout(0.5))
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer=Adam(), metrics=['accuracy'])
return model
input_shape = (x_train.shape[1], 1, 1)
cnn_lstm_attention_model = build_cnn_lstm_attention_model(input_shape, num_classes)
4. 训练模型
history_cnn = cnn_model.fit(x_train, y_train, epochs=100, batch_size=128, validation_data=(x_test, y_val))
history_lstm = lstm_model.fit(x_train, y_train, epochs=100, batch_size=128, validation_data=(x_test, y_val))
history_cnn_lstm = cnn_lstm_model.fit(x_train, y_train, epochs=100, batch_size=128, validation_data=(x_test, y_val))
history_cnn_lstm_attention = cnn_lstm_attention_model.fit(x_train, y_train, epochs=100, batch_size=128, validation_data=(x_test, y_val))
5. 评估模型
scores_cnn = cnn_model.evaluate(x_test, y_val, verbose=0)
print(f"CNN Test Accuracy: {scores_cnn[1]*100:.2f}%")
scores_lstm = lstm_model.evaluate(x_test, y_val, verbose=0)
print(f"LSTM Test Accuracy: {scores_lstm[1]*100:.2f}%")
scores_cnn_lstm = cnn_lstm_model.evaluate(x_test, y_val, verbose=0)
print(f"CNN-LSTM Test Accuracy: {scores_cnn_lstm[1]*100:.2f}%")
scores_cnn_lstm_attention = cnn_lstm_attention_model.evaluate(x_test, y_val, verbose=0)
print(f"CNN-LSTM with Attention Test Accuracy: {scores_cnn_lstm_attention[1]*100:.2f}%")
6. 可视化训练过程
def plot_history(history):
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(history.history['accuracy'], label='Train Accuracy')
plt.plot(history.history['val_accuracy'], label='Validation Accuracy')
plt.legend()
plt.title('Accuracy over Epochs')
plt.subplot(1, 2, 2)
plt.plot(history.history['loss'], label='Train Loss')
plt.plot(history.history['val_loss'], label='Validation Loss')
plt.legend()
plt.title('Loss over Epochs')
plt.show()
plot_history(history_cnn)
plot_history(history_lstm)
plot_history(history_cnn_lstm)
plot_history(history_cnn_lstm_attention)
以上代码涵盖了从特征提取到模型训练、评估和结果可视化的完整流程。

将继续构建语音情感识别系统的代码。在前面的代码中,我们定义了常量和一些基本设置。现在,我们将实现数据加载、特征提取、模型构建、训练和评估等步骤。
7. 数据加载
首先,我们需要编写一个函数来加载音频文件并提取其特征。
import os
import math
import numpy as np
import librosa
from sklearn.model_selection import train_test_split
from keras.utils import to_categorical
# constants
sr = 16000
duration = 5
frame_length = 512
N_FRAMES = math.ceil(sr * duration / frame_length)
N_FEATURES = 46
N_EMOTIONS = 7
emo_codes = {"W": 0, "L": 1, "E": 2, "A": 3, "F": 4, "T": 5, "N": 6}
emo_labels_deu = ["wut", "langeweile", "ekel", "angst", "freude", "trauer", "neutral"]
emo_labels_en = ["anger", "boredom", "disgust", "fear", "happiness", "sadness", "neutral"]
emo_labels_ita = ["rabbia", "noia", "disgusto", "paura", "felicità", "tristezza", "neutro"]
path = "D:/speech_emotion_recognition-main/archive/wav"
def load_data(path):
X = []
y = []
for subdir, dirs, files in os.walk(path):
for file in files:
if file.endswith('.wav'):
filepath = os.path.join(subdir, file)
audio, _ = librosa.load(filepath, sr=sr, duration=duration)
features = features(audio, sr)
X.append(features)
emotion_code = file[5]
y.append(emo_codes[emotion_code])
return np.array(X), np.array(y)
X, y = load_data(path)
y = to_categorical(y)
# Split the data into training and testing sets
x_train, x_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
8. 特征提取
我们已经定义了一个features函数,用于从音频信号中提取特征。这里再次列出该函数以确保完整性。
def features(X, sample_rate):
stft = np.abs(librosa.stft(X))
# fmin 和 fmax 对应于人类语音的最小最大基频
pitches, magnitudes = librosa.piptrack(X, sr=sample_rate, S=stft)
pitch = []
for i in range(magnitudes.shape[1]):
index = magnitudes[:, i].argmax()
pitch.append(pitches[index, i])
pitch_tuning_offset = librosa.pitch_tuning(pitches)
pitchmean = np.mean(pitch)
pitchstd = np.std(pitch)
pitchmax = np.max(pitch)
pitchmin = np.min(pitch)
return {
'pitch_tuning_offset': pitch_tuning_offset,
'pitchmean': pitchmean,
'pitchstd': pitchstd,
'pitchmax': pitchmax,
'pitchmin': pitchmin
}
9. 模型构建
9.1 CNN模型
from keras.models import Sequential
from keras.layers import Conv1D, MaxPooling1D, Flatten, Dense, Dropout
from keras.optimizers import Adam
def build_cnn_model(input_shape, num_classes):
model = Sequential()
model.add(Conv1D(64, kernel_size=3, activation='relu', input_shape=input_shape))
model.add(MaxPooling1D(pool_size=2))
model.add(Dropout(0.5))
model.add(Conv1D(128, kernel_size=3, activation='relu'))
model.add(MaxPooling1D(pool_size=2))
model.add(Dropout(0.5))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer=Adam(), metrics=['accuracy'])
return model
input_shape = (N_FRAMES, N_FEATURES)
num_classes = N_EMOTIONS
cnn_model = build_cnn_model(input_shape, num_classes)
9.2 LSTM模型
from keras.layers import LSTM
def build_lstm_model(input_shape, num_classes):
model = Sequential()
model.add(LSTM(64, return_sequences=True, input_shape=input_shape))
model.add(Dropout(0.5))
model.add(LSTM(64))
model.add(Dropout(0.5))
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer=Adam(), metrics=['accuracy'])
return model
lstm_model = build_lstm_model(input_shape, num_classes)
9.3 CNN-LSTM模型
from keras.layers import TimeDistributed
def build_cnn_lstm_model(input_shape, num_classes):
model = Sequential()
model.add(TimeDistributed(Conv1D(64, kernel_size=3, activation='relu'), input_shape=input_shape))
model.add(TimeDistributed(MaxPooling1D(pool_size=2)))
model.add(TimeDistributed(Dropout(0.5)))
model.add(TimeDistributed(Conv1D(128, kernel_size=3, activation='relu')))
model.add(TimeDistributed(MaxPooling1D(pool_size=2)))
model.add(TimeDistributed(Dropout(0.5)))
model.add(TimeDistributed(Flatten()))
model.add(LSTM(64, return_sequences=True))
model.add(Dropout(0.5))
model.add(LSTM(64))
model.add(Dropout(0.5))
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer=Adam(), metrics=['accuracy'])
return model
cnn_lstm_model = build_cnn_lstm_model(input_shape, num_classes)
9.4 CNN-LSTM带注意力机制模型
from keras.layers import Bidirectional, Attention
def build_cnn_lstm_attention_model(input_shape, num_classes):
model = Sequential()
model.add(TimeDistributed(Conv1D(64, kernel_size=3, activation='relu'), input_shape=input_shape))
model.add(TimeDistributed(MaxPooling1D(pool_size=2)))
model.add(TimeDistributed(Dropout(0.5)))
model.add(TimeDistributed(Conv1D(128, kernel_size=3, activation='relu')))
model.add(TimeDistributed(MaxPooling1D(pool_size=2)))
model.add(TimeDistributed(Dropout(0.5)))
model.add(TimeDistributed(Flatten()))
model.add(Bidirectional(LSTM(64, return_sequences=True)))
model.add(Attention())
model.add(Dropout(0.5))
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer=Adam(), metrics=['accuracy'])
return model
cnn_lstm_attention_model = build_cnn_lstm_attention_model(input_shape, num_classes)
10. 训练模型
history_cnn = cnn_model.fit(x_train, y_train, epochs=100, batch_size=128, validation_data=(x_test, y_test))
history_lstm = lstm_model.fit(x_train, y_train, epochs=100, batch_size=128, validation_data=(x_test, y_test))
history_cnn_lstm = cnn_lstm_model.fit(x_train, y_train, epochs=100, batch_size=128, validation_data=(x_test, y_test))
history_cnn_lstm_attention = cnn_lstm_attention_model.fit(x_train, y_train, epochs=100, batch_size=128, validation_data=(x_test, y_test))
11. 评估模型
scores_cnn = cnn_model.evaluate(x_test, y_test, verbose=0)
print(f"CNN Test Accuracy: {scores_cnn[1]*100:.2f}%")
scores_lstm = lstm_model.evaluate(x_test, y_test, verbose=0)
print(f"LSTM Test Accuracy: {scores_lstm[1]*100:.2f}%")
scores_cnn_lstm = cnn_lstm_model.evaluate(x_test, y_test, verbose=0)
print(f"CNN-LSTM Test Accuracy: {scores_cnn_lstm[1]*100:.2f}%")
scores_cnn_lstm_attention = cnn_lstm_attention_model.evaluate(x_test, y_test, verbose=0)
print(f"CNN-LSTM with Attention Test Accuracy: {scores_cnn_lstm_attention[1]*100:.2f}%")
12. 可视化训练过程
import matplotlib.pyplot as plt
def plot_history(history):
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(history.history['accuracy'], label='Train Accuracy')
plt.plot(history.history['val_accuracy'], label='Validation Accuracy')
plt.legend()
plt.title('Accuracy over Epochs')
plt.subplot(1, 2, 2)
plt.plot(history.history['loss'], label='Train Loss')
plt.plot(history.history['val_loss'], label='Validation Loss')
plt.legend()
plt.title('Loss over Epochs')
plt.show()
plot_history(history_cnn)
plot_history(history_lstm)
plot_history(history_cnn_lstm)
plot_history(history_cnn_lstm_attention)
可以根据实际需求调整参数和模型结构。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









