







pytorch 深度学习目标检测算法yolov5训练电动车闯红灯检测数据集 建立基于深度学习Yolov5电动车闯红灯检测识别
文章目录
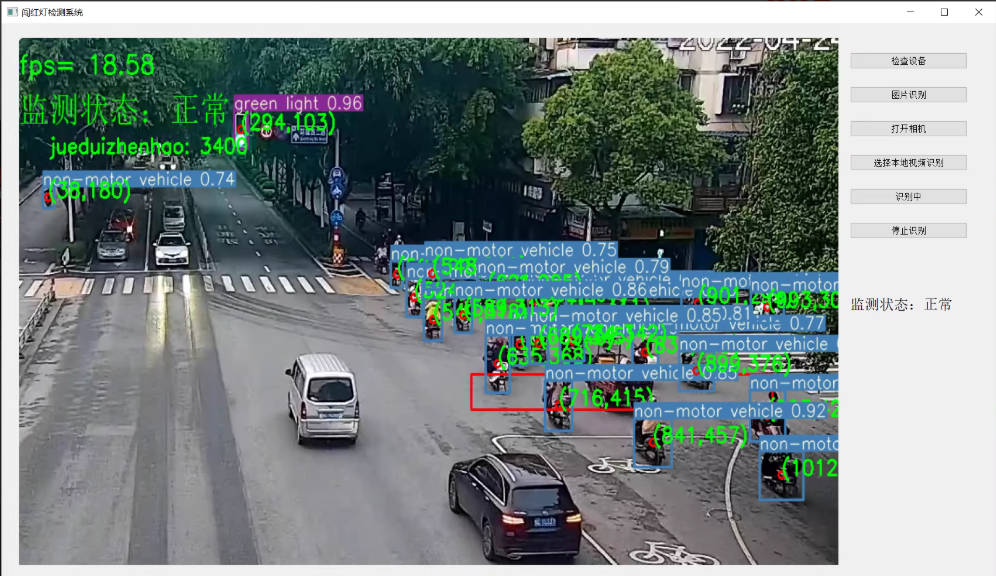
yolov5电动车闯红灯检测, 可检测 红灯 绿灯 电动车三类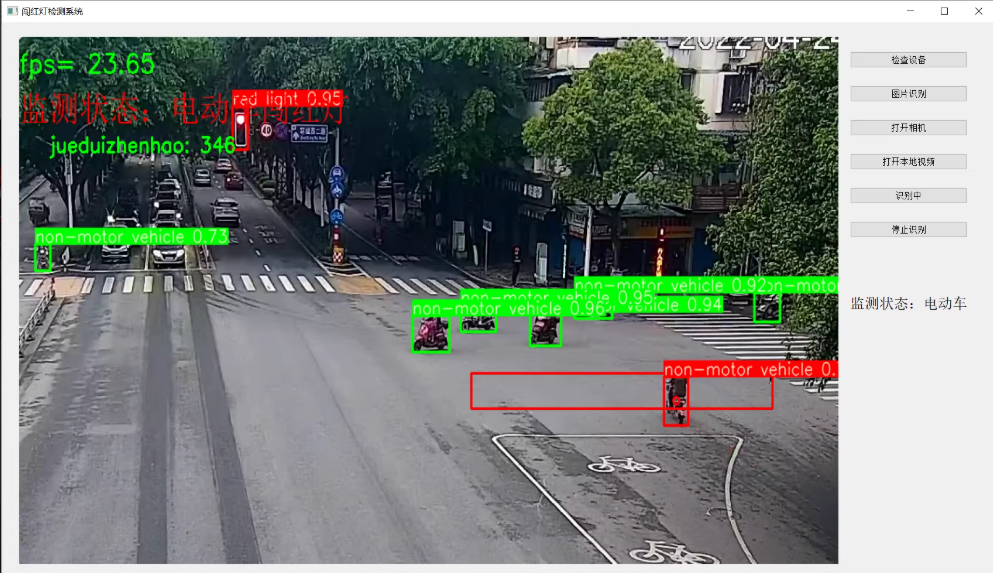
1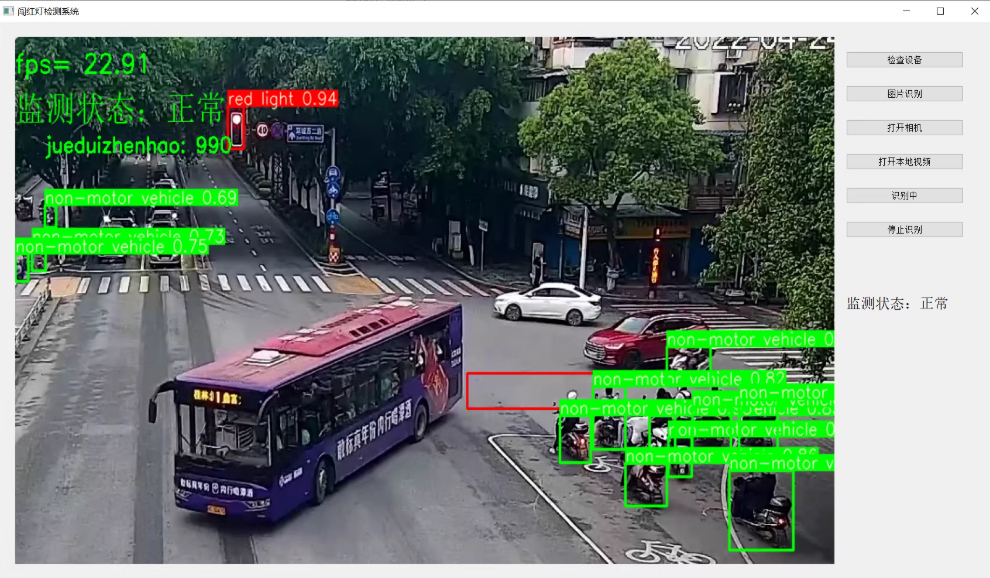

基于YOLOv5的电动车闯红灯检测系统涉及多个步骤,包括数据准备、环境搭建、模型训练、超参数配置、模型推理、批量推理以及性能评估。以下是详细的实现步骤和代码示例。
1. 数据准备
数据集结构
确保你的数据集结构如下:
traffic_dataset/
├── images/
│ ├── train/
│ └── val/
└── labels/
├── train/
└── val/
数据标注
每个图像文件对应一个.txt文件,格式为YOLO适用的标注格式,每行包含类别ID和边界框信息(归一化后的中心点坐标和宽高)。
例如:
0 0.5 0.5 0.2 0.2
1 0.7 0.3 0.1 0.1
数据划分
将数据集按比例划分为训练集和验证集(例如9:1)。
import os
import random
from shutil import copyfile
# 定义数据集路径
dataset_path = 'traffic_dataset'
images_path = os.path.join(dataset_path, 'images')
labels_path = os.path.join(dataset_path, 'labels')
# 创建目录
os.makedirs(images_path, exist_ok=True)
os.makedirs(labels_path, exist_ok=True)
# 获取所有图像文件
image_files = [f for f in os.listdir(dataset_path) if f.endswith('.jpg') or f.endswith('.png')]
random.shuffle(image_files)
# 按比例划分训练集和验证集
train_ratio = 0.9
train_size = int(len(image_files) * train_ratio)
train_images = image_files[:train_size]
val_images = image_files[train_size:]
# 复制文件到对应的目录
for img_file in train_images:
label_file = img_file.replace('.jpg', '.txt').replace('.png', '.txt')
copyfile(os.path.join(dataset_path, img_file), os.path.join(images_path, 'train', img_file))
copyfile(os.path.join(dataset_path, label_file), os.path.join(labels_path, 'train', label_file))
for img_file in val_images:
label_file = img_file.replace('.jpg', '.txt').replace('.png', '.txt')
copyfile(os.path.join(dataset_path, img_file), os.path.join(images_path, 'val', img_file))
copyfile(os.path.join(dataset_path, label_file), os.path.join(labels_path, 'val', label_file))
2. 环境搭建
安装依赖
# 创建并激活虚拟环境
conda create -n traffic_detection python=3.8
conda activate traffic_detection
# 安装YOLOv5和相关库
pip install torch torchvision
git clone https://github.com/ultralytics/yolov5.git
cd yolov5
pip install -r requirements.txt
3. 数据配置
在traffic_dataset/目录下创建一个名为data.yaml的数据配置文件,内容如下:
train: ./images/train/
val: ./images/val/
nc: 3
names: ['red_light', 'green_light', 'non_motor_vehicle']
4. 模型训练
使用YOLOv5进行训练
cd yolov5
python train.py --img 640 --batch 16 --epochs 100 --data ../traffic_dataset/data.yaml --weights yolov5s.pt
5. 配置超参数
在训练过程中,可以通过修改yolov5/data/hyps/hyp.scratch.yaml文件来设置超参数。以下是一些常见的超参数及其说明:
lr0: 初始学习率,默认值通常为0.01。lrf: 最终学习率因子,默认值通常为0.01。momentum: 动量,默认值通常为0.937。weight_decay: 权重衰减,默认值通常为0.0005。
6. 模型推理
单张图片推理
from yolov5.models.experimental import attempt_load
from yolov5.utils.datasets import LoadImages
from yolov5.utils.general import non_max_suppression, scale_coords
from yolov5.utils.torch_utils import select_device
import cv2
import torch
def infer_image(weights, img_path):
device = select_device('')
model = attempt_load(weights, map_location=device)
dataset = LoadImages(img_path)
for path, img, im0s, vid_cap in dataset:
img = torch.from_numpy(img).to(device)
img = img.float() / 255.0
if img.ndimension() == 3:
img = img.unsqueeze(0)
pred = model(img, augment=False)[0]
pred = non_max_suppression(pred, conf_thres=0.25, iou_thres=0.45)
for det in pred:
if len(det):
det[:, :4] = scale_coords(img.shape[2:], det[:, :4], im0s.shape).round()
for *xyxy, conf, cls in reversed(det):
label = f'{model.names[int(cls)]} {conf:.2f}'
plot_one_box(xyxy, im0s, label=label, color=(0, 255, 0), line_thickness=3)
cv2.imshow('Traffic Detection', im0s)
cv2.waitKey(0)
cv2.destroyAllWindows()
if __name__ == "__main__":
weights = 'runs/train/exp/weights/best.pt'
img_path = 'path/to/test_image.jpg'
infer_image(weights, img_path)
7. 批量推理
import os
def batch_infer_images(weights, directory):
for filename in os.listdir(directory):
if filename.endswith(".jpg") or filename.endswith(".png"):
image_path = os.path.join(directory, filename)
annotated_frame = infer_image(weights, image_path)
cv2.imwrite(f"output_{filename}", annotated_frame)
if __name__ == "__main__":
weights = 'runs/train/exp/weights/best.pt'
directory = 'path/to/images'
batch_infer_images(weights, directory)
8. 性能评估
mAP计算
YOLOv5自带评估功能,可以在验证集上计算mAP。
cd yolov5
python val.py --img 640 --batch 16 --data ../traffic_dataset/data.yaml --weights runs/train/exp/weights/best.pt
自定义评估脚本
如果你想要更详细的评估指标,比如针对特定类别的准确率和召回率,可以编写自定义脚本。
from sklearn.metrics import precision_recall_fscore_support
def evaluate_model(model, dataset):
all_preds = []
all_labels = []
for images, labels in dataset:
preds = model(images)
pred_classes = [int(pred.cls[0]) for pred in preds]
true_classes = labels.numpy().flatten()
all_preds.extend(pred_classes)
all_labels.extend(true_classes)
precision, recall, f1, _ = precision_recall_fscore_support(all_labels, all_preds, average='weighted')
print(f'Precision: {precision:.2f}, Recall: {recall:.2f}, F1 Score: {f1:.2f}')
# 示例:评估模型性能
evaluate_model(model, val_dataset)
以上就是关于如何在YOLOv5基础上构建电动车闯红灯检测系统的完整指南,包括数据准备、环境搭建、模型训练、超参数配置、模型推理、批量推理以及性能评估代码。根据实际需求调整上述代码段,关键代码示例,仅供参考。


















 391
391

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









