








GC10-DET钢材缺陷数据集,并提供使用YOLOv8进行训练的详细步骤和代码。
数据集介绍
- 数据集概述
数据集名称:GC10-DET钢材缺陷数据集
图像数量:2293张图像
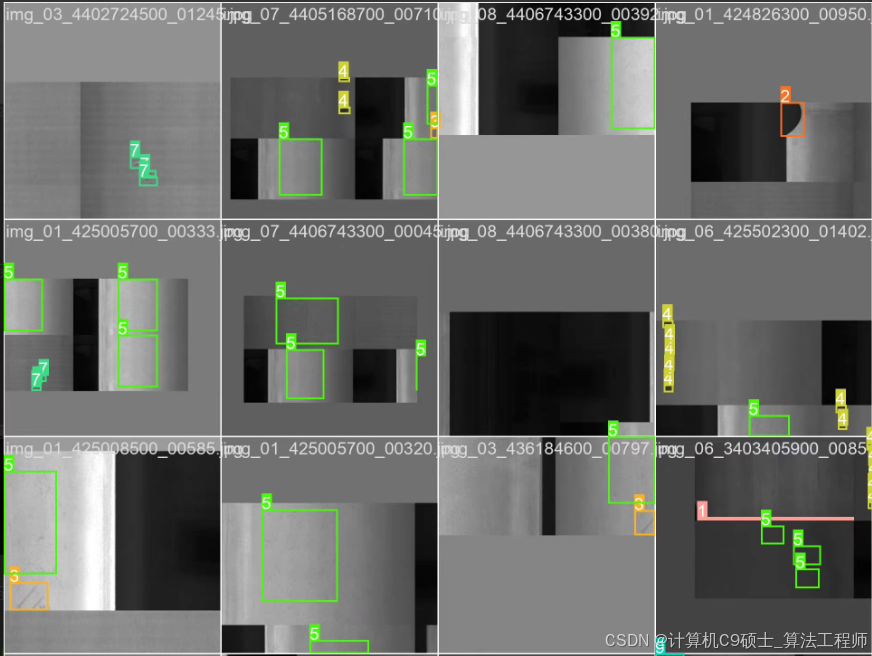
瑕疵类型:10种,包括冲孔(Pu)、焊缝(Wl)、新月形缝隙(Cg)、水斑(Ws)、油斑(Os)、丝斑(Ss)、夹杂物(In)、轧坑(Rp)、折痕(Cr)、腰部折痕(Wf)
数据格式:包含VOC和YOLO两种格式
数据集划分:已划分好训练集、验证集和测试集 - 数据集结构
假设你的数据集已经按照以下结构组织:
深色版本
gc10_det_dataset/
├── images/
│ ├── trai
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1841
1841

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









