






2025深度学习发论文&模型涨点之——多模态 Embedding
多模态Embedding技术通过构建统一语义空间,将文本、图像、音频、视频等异构模态信息映射为稠密低维向量,为解决跨模态检索、生成与推理任务提供了基础性框架。从早期基于矩阵分解的浅层模型,到以Transformer架构为核心的深度跨模态预训练范式,这一领域经历了从手工特征工程到端到端语义建模的范式跃迁。
我整理了一些多模态 Embedding【论文+代码】合集,需要的同学公人人人号【AI创新工场】发525自取。
论文精选
论文1:
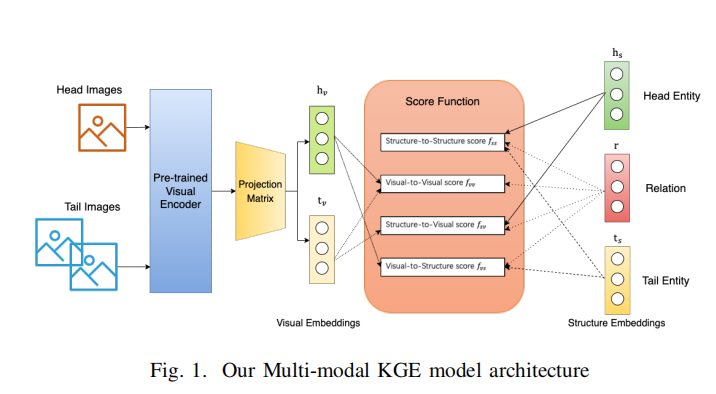
Modality-Aware Negative Sampling for Multi-modal Knowledge Graph Embedding
多模态知识图谱嵌入中的模态感知负采样
方法
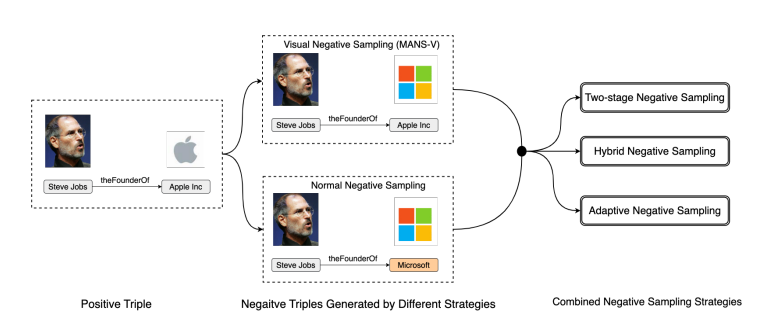
视觉负采样(MANS-V):提出了一种模态级负采样策略,仅对视觉特征进行负采样,以实现结构嵌入和视觉嵌入之间的对齐。
两阶段负采样(MANS-T):将训练过程分为两个阶段,先使用MANS-V对齐模态,再使用普通负采样进行三元组合理性判别。
混合负采样(MANS-H):在每个训练周期中同时使用MANS-V和普通负采样,通过采样比例β₂控制两者的混合比例。
自适应负采样(MANS-A):根据训练数据的多模态分数和单模态分数自适应调整MANS-V的采样比例β₃,无需手动调参。
创新点
模态对齐:MANS-V通过仅对视觉特征进行负采样,实现了结构嵌入和视觉嵌入之间的对齐,这是多模态知识图谱嵌入中的一个重要创新。
性能提升:在FB15K数据集上,MANS-A在Hit@1指标上相对于基线方法(如EANS)从0.318提升到0.353,相对提升了9.9%。
效率提升:MANS方法在训练速度上接近普通负采样,比一些复杂的基线方法(如NSCaching和EANS)更高效。
语义信息学习:通过t-SNE可视化,MANS方法训练的嵌入能够更清晰地区分结构嵌入和视觉嵌入,表明模型学习到了更丰富的语义信息。
论文2:
Concept Visualization: Explaining the CLIP Multi-modal Embedding Using WordNet
利用WordNet解释CLIP多模态嵌入的概念可视化
方法
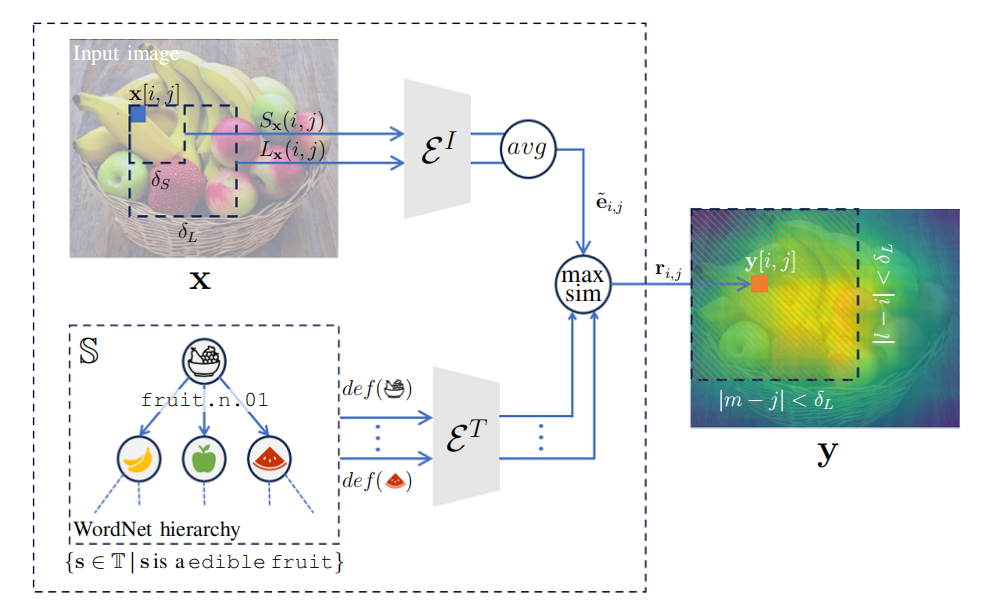
词义相似度度量:设计了一种基于CLIP空间的词义与图像之间的相似度度量方法,利用WordNet中的词义定义进行嵌入。
多尺度嵌入与空间聚合:通过在图像的不同尺度上计算嵌入,并对局部相似度分数进行空间聚合,生成针对任何WordNet同义词集的显著性图。
显著性图生成:通过计算图像块与WordNet定义的嵌入之间的相似度,生成能够解释任何语义概念的显著性图。
创新点
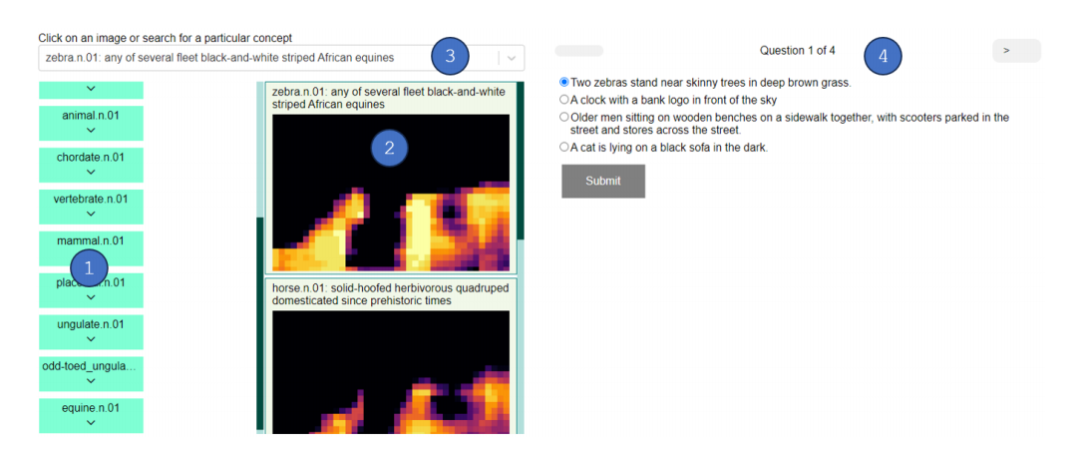
概念解释:能够为任何语义概念生成显著性图,包括模型未训练过的概念,这是以往显著性图方法所无法实现的。
性能验证:在OOD检测实验中,提出的最大秩相似度(max rank sim)作为OOD分数的性能优于其他方法,如最大对数分数(MLS)和孤立森林(IF)。
用户研究:通过用户研究验证了ConVis能够帮助用户理解CLIP对图像的语义理解,用户仅通过显著性图猜测图像描述的准确率达到了76.4%,显著高于随机猜测的25%。
论文3:
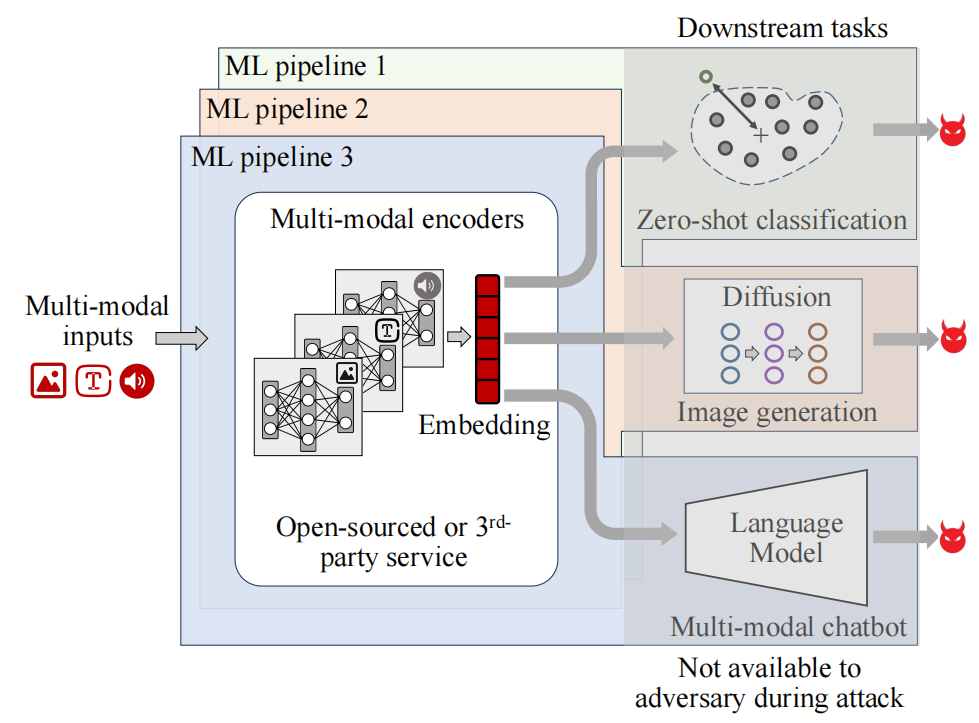
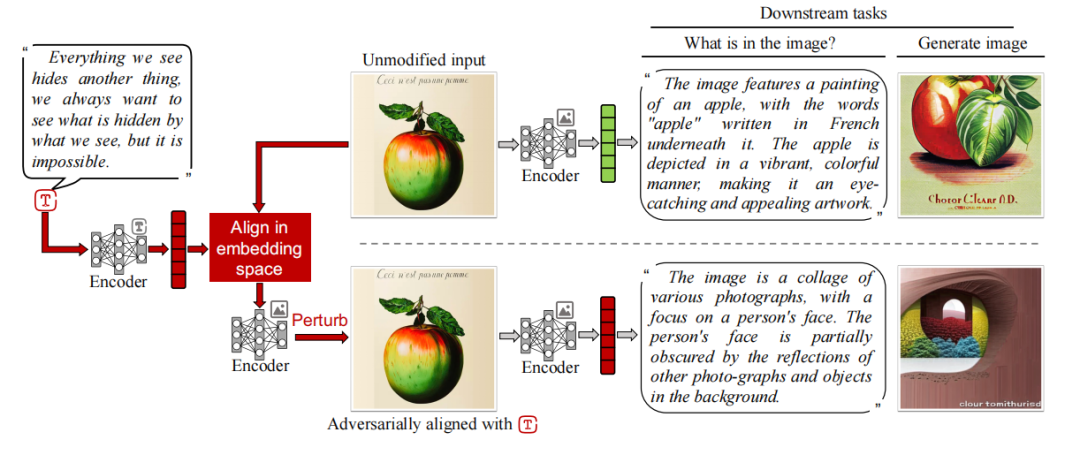
Adversarial Illusions in Multi-Modal Embeddings
多模态嵌入中的对抗性幻觉
方法
白盒攻击:利用目标编码器的梯度信息,通过优化目标函数直接生成对抗性幻觉。
迁移攻击:使用其他开放源代码的编码器作为代理模型,生成对抗性幻觉并将其迁移到目标编码器。
查询攻击:仅通过查询目标编码器的API,利用梯度无关的优化方法生成对抗性幻觉。
混合攻击:结合查询攻击和迁移攻击,先使用代理模型生成幻觉,再通过查询优化使其更接近目标。
创新点
跨模态幻觉:首次展示了可以通过对抗性扰动将一种模态的输入与另一种模态的任意目标对齐,这种幻觉可以误导多种下游任务。
任务无关性:攻击是任务无关的,能够影响所有基于多模态嵌入的下游任务,即使这些任务在攻击时未知。
黑盒攻击:成功对亚马逊的商业黑盒嵌入Titan进行了对抗性对齐攻击,这是首次实现此类攻击。
防御规避:展示了对抗性幻觉可以绕过基于特征蒸馏(如JPEG压缩)和基于增强一致性的异常检测等防御措施。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









