






2025深度学习发论文&模型涨点之——频域+注意力机制
频域分析与注意力机制的协同创新已成为多模态信号处理与计算机视觉领域的前沿研究方向。频域方法(如傅里叶变换、小波变换、图频域分解)通过将信号映射到频谱空间,为模型提供了全局性、抗噪性的特征表征能力;而注意力机制则通过动态权重分配,实现了对关键特征的聚焦与长程依赖建模。二者的结合在理论上形成了互补优势:频域变换缓解了注意力机制在全局建模时的计算复杂度问题,而注意力机制则弥补了传统频域方法缺乏内容自适应性的缺陷。
我整理了一些频域+注意力机制【论文+代码】合集,需要的同学公人人人号【AI创新工场】发525自取。
论文精选
论文1:
[ICLR] TIMEMIXER++: A GENERAL TIME SERIES PATTERN MACHINE FOR UNIVERSAL PREDICTIVE ANALYSIS
TIMEMIXER++:一种用于通用预测分析的时间序列模式机
方法
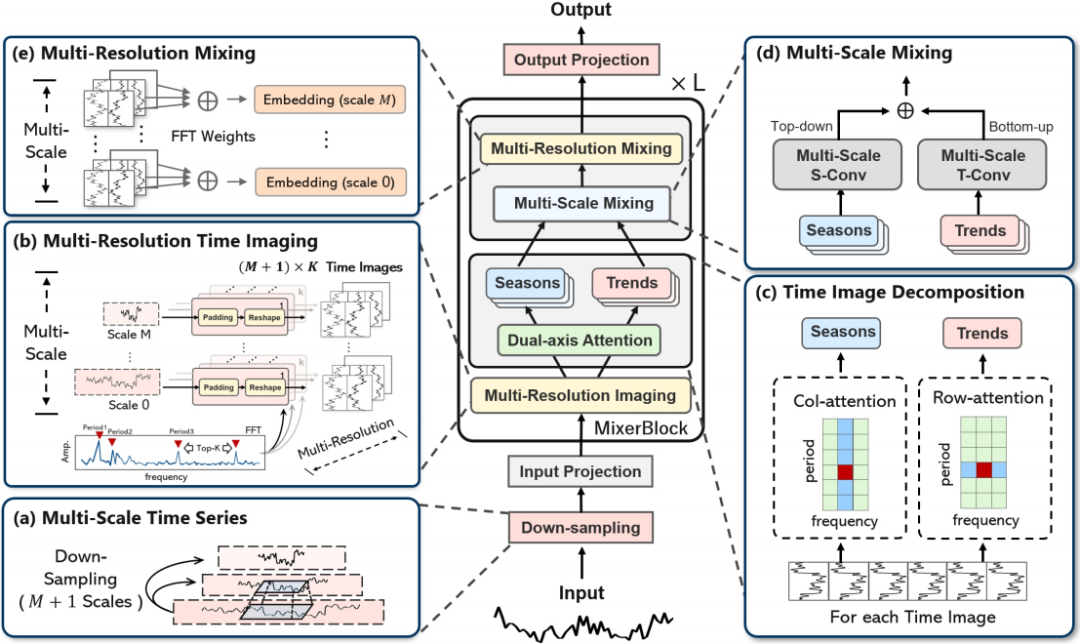
多分辨率时间成像(MRTI):将多尺度时间序列转换为多分辨率时间图像,捕捉时间域和频率域的模式。
时间图像分解(TID):利用双轴注意力机制从时间图像中分离季节性和趋势模式。
多尺度混合(MCM):通过层次化聚合在不同尺度上整合季节性和趋势模式。
多分辨率混合(MRM):自适应地整合不同分辨率下的表示,以提取全面的时间序列模式。
输入投影和输出投影:通过通道混合和嵌入将多尺度时间序列投影到深度模式空间,并通过多个预测头对不同尺度的输出进行集成。
创新点
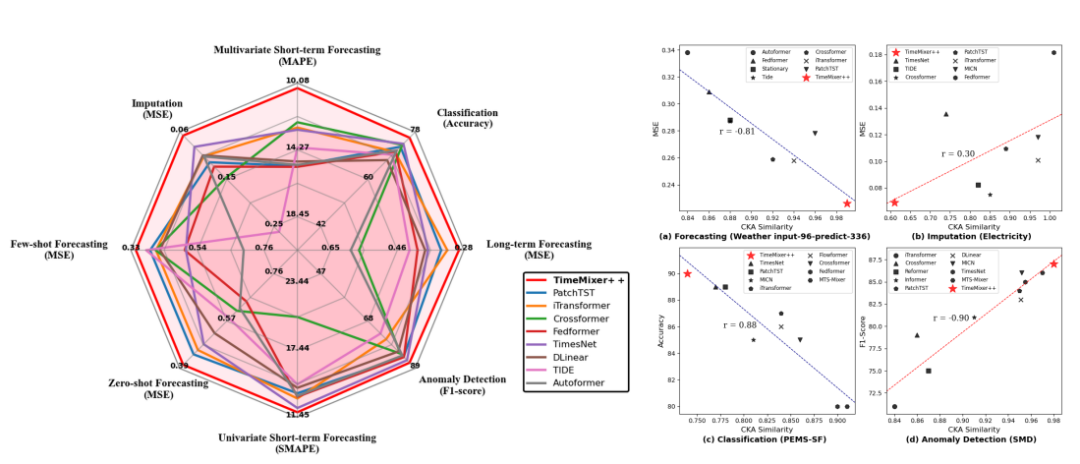
多尺度和多周期性时间序列处理:TIMEMIXER++能够同时处理多尺度和多周期性的时间序列数据,有效捕捉不同时间尺度上的复杂动态。例如,在处理具有小时波动的日数据和反映长期趋势及季节周期的年数据时,能够分别提取出对应的模式。
多分辨率时间成像:通过将时间序列转换为多分辨率时间图像,TIMEMIXER++能够在时间和频率域中同时进行模式提取,这使得模型能够更全面地捕捉时间序列中的复杂模式,从而在各种任务中实现更准确的预测。
双轴注意力机制:在时间图像分解中,TIMEMIXER++利用双轴注意力机制,分别在列(时间轴)和行(频率轴)上进行注意力计算,有效分离季节性和趋势模式,从而更准确地捕捉时间序列中的周期性和趋势性变化。
论文2:
[CVPR] Modality-agnostic Domain Generalizable Medical Image Segmentation by Multi-Frequency in Multi-Scale Attention
多模态鲁棒的医学图像分割:基于多频率多尺度注意力的域泛化方法
方法
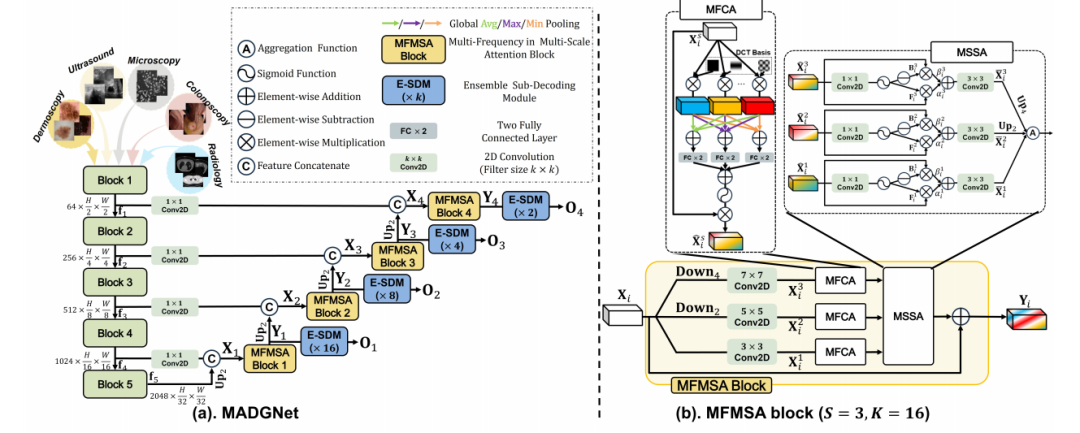
多频率多尺度注意力块(MFMSA):通过结合多频率和多尺度特征,优化空间特征提取过程,特别是在捕获边界特征方面,为组织轮廓和解剖结构提供信息线索。
多频率通道注意力(MFCA):使用二维离散余弦变换(2D DCT)生成通道注意力图,通过提取频率统计信息来增强特征表示。
多尺度空间注意力(MSSA):从每个尺度中提取区分性的边界特征,并将它们聚合起来,以增强对不同尺度下边界信息的捕捉能力。
集成子解码模块(ESDM):在多任务学习和深度监督中,通过集成方式减轻由于大幅上采样导致的信息丢失问题,从而提高模型对详细边界和结构的预测能力。
创新点
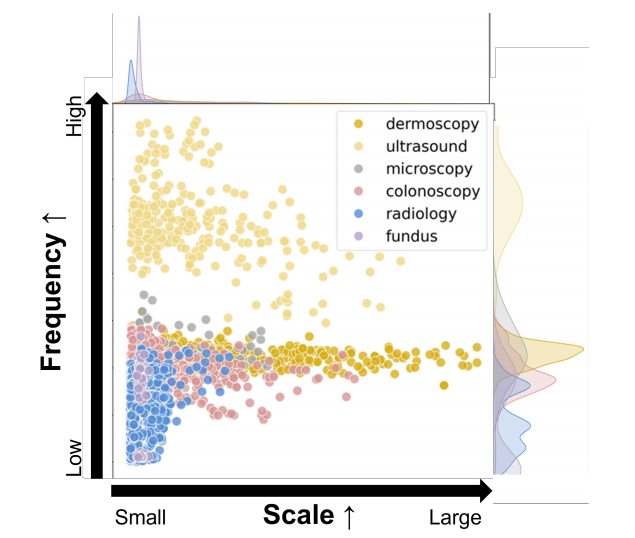
多模态鲁棒性:MADGNet能够在多种医学图像模态(如皮肤镜、放射学、超声、显微镜、结肠镜和眼底成像)上实现鲁棒的分割性能,与现有模型相比,其平均DSC和mIoU分别提高了1.1%和1.0%。
多频率和多尺度特征融合:通过同时考虑多频率和多尺度特征,MADGNet能够更全面地理解医学图像内容,从而在不同模态和临床场景中实现更准确的分割。
信息丢失补偿:ESDM通过集成不同任务的预测结果,有效解决了多任务学习中由于大幅上采样导致的信息丢失问题,从而提高了模型对复杂边界和结构的预测能力。
性能提升:在多个医学图像分割数据集上,MADGNet均取得了最高的分割性能。例如,在皮肤镜图像分割任务中,与M2SNet相比,MADGNet的DSC和mIoU分别提高了1.1%和1.0%;在放射学图像分割任务中,与FRCUNet相比,MADGNet的DSC和mIoU分别提高了2.0%。
论文3:
HartleyMHA: Self-Attention in Frequency Domain for Resolution-Robust and Parameter-Efficient 3D Image Segmentation
HartleyMHA:基于频域自注意力的分辨率鲁棒和参数高效的3D图像分割
方法
傅里叶神经算子(FNO):基于傅里叶神经算子(FNO)的深度学习模型,用于学习偏微分方程中函数之间的映射关系,具有零样本超分辨率和全局感受野的特性。
Hartley变换:使用Hartley变换替代傅里叶变换,将模型参数减少数个数量级,从而在频域中实现更高效的自注意力机制。
Hartley多头注意力(Hartley MHA):在频域中应用多头自注意力机制,通过高阶特征组合提高模型的表达能力。
网络架构(HNOSeg和HartleyMHA):基于Hartley变换的网络架构,包括HNO块和Hartley MHA块,通过残差连接和深度监督提高训练稳定性和准确性。
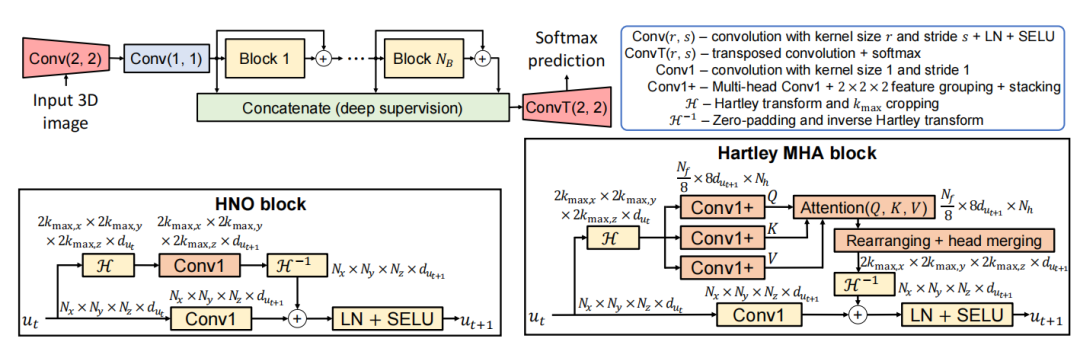
创新点
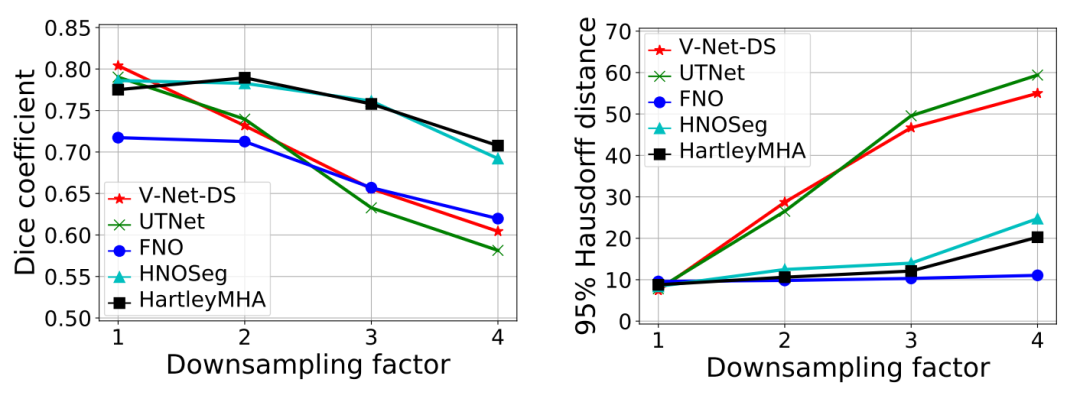
分辨率鲁棒性:HartleyMHA模型在训练图像分辨率降低时表现出显著的鲁棒性。例如,当训练图像的分辨率从240×240×155降低到60×60×39时,HartleyMHA的平均Dice系数仅下降了5.1%,而其他模型如V-Net-DS和UTNet的平均Dice系数分别下降了24%以上。
参数效率:HartleyMHA模型的参数数量显著减少。与V-Net-DS和UTNet相比,HartleyMHA的参数数量不到1%,但其性能在低分辨率训练时仍能保持较高水平。
计算效率:HartleyMHA模型在推理时的计算成本较低。例如,HartleyMHA的推理时间比HNOSeg快,且使用的内存更少,尽管其参数数量略多于HNOSeg。
性能提升:在BraTS’19数据集上,HartleyMHA模型在不同训练图像分辨率下的表现均优于或接近其他测试模型。例如,在原始分辨率下,HartleyMHA的平均Dice系数与V-Net-DS和UTNet相差不到3%,但其参数数量不到这些模型的1%。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









