






Trainium2:实现突破性的AI训练和推理性能
关键字: [Amazon Web Services re:Invent 2024, 亚马逊云科技, 生成式AI, Trinium 2, Trainium 2 Chip, Ai Model Training, Inference Performance, Memory Bandwidth, Model Parallelism]
导读
介绍全新的Amazon EC2 Trn2实例,搭载第二代Trainium芯片亚马逊云科技 Trainium2。参加本次会议,首次了解Trn2实例如何为训练和部署最具挑战性的生成式AI模型(参数规模从数千亿到万亿不等)提供最高性能。深入探讨Trn2实例的设计理念,了解它如何帮助您缩短训练时间、加快迭代速度,并提供实时的AI驱动体验。
演讲精华
以下是小编为您整理的本次演讲的精华。
在喧闹的拉斯维加斯市中,亚马逊云科技 re:Invent 2024大会上洋溢着兴奋的氛围。亚马逊云科技人工智能芯片高级产品经理Joe Senercia登台,揭开了亚马逊云科技下一代人工智能芯片Trainium2 (TRN2)的神秘面纱。与他同台的是两位著名嘉宾:亚马逊云科技人工智能芯片高级首席工程师兼首席架构师Ron,以及世界领先人工智能创新实验室Anthropic的杰出工程师James Bradbury。
Joe首先谈到了围绕生成式人工智能的热潮,这项有望像互联网一样具有变革性影响的技术革命。他强调,人工智能能够以10、100甚至1000倍的效率提高生产力,从而引领了新一波技术变革浪潮。Joe对客户将如何利用亚马逊云科技的生成式人工智能能力进行创新表示兴奋,并强调公司正在全力推进整个生成式人工智能技术栈的进步。
概述了这一技术栈,Joe从顶层的应用程序开始,如旨在通过代码生成、内容创作和数据资源管理来提高生产力的Amazon Q。接下来是像Amazon Bedrock这样的工具,可让用户使用来自Anthropic、Cohere、AI21等领先前沿实验室以及最新发布的Amazon Nova的大型语言模型。支撑这一技术栈的是基础设施层,这也是Joe的主要关注点,也是当天会议的主题。
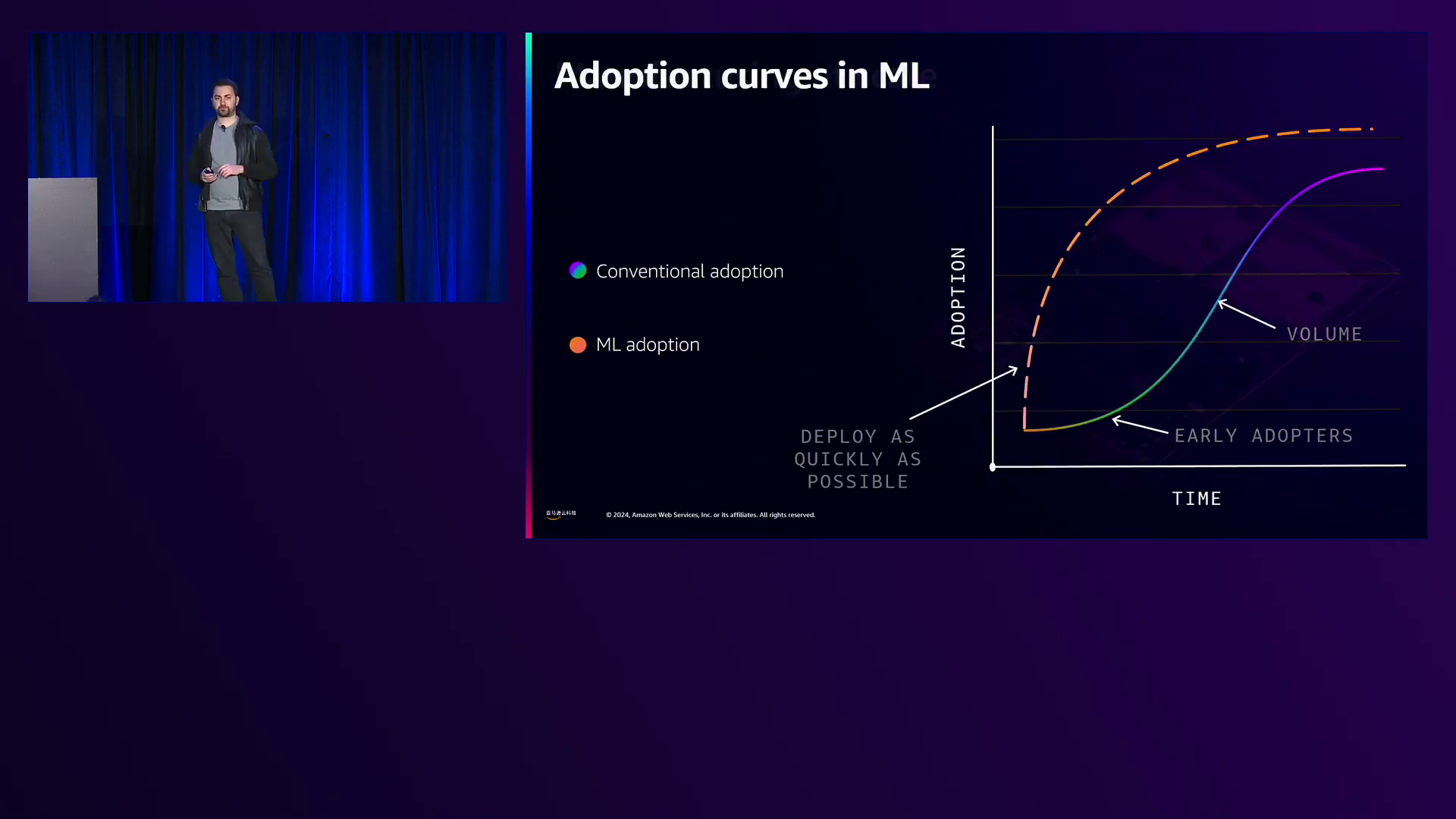
随后Ron登场,深入探讨了构建Trainium2的细节。他解释说,人工智能工作负载可能是内存带宽密集型、内存容量密集型或互连密集型,而Trainium2的设计目标是在这三个维度上都提供无与伦比的性能。Ron揭示了Trainium2令人印象深刻的规格,包括1.3佩塔浮点运算能力、超过5佩塔浮点稀疏计算能力、96GB HBM容量以及惊人的2.9TB/秒内存带宽。
为了展示Trainium2的实力,Ron分享了一些基准测试结果,展现了它在大型语言模型如LLaMA 405B上的卓越推理性能,这些测试由Artificial Analysis进行。在评估典型流量模式下10,000个输入token和100个输出token的总响应时间的基准测试中,Trainium2的延迟优化性能超越了所有其他可用产品,取得了最快的成绩。
另一项基准测试则突出了Trainium2的训练能力。Ron透露,在使用64个Trainium2节点的集群训练开源的Fuji 70B模型(由苹果公司开发)时,亚马逊云科技实现了比在类似规模的基于GPU的P5集群上训练快1.5倍的训练时间,以及低1.7倍的训练成本。
然而,Ron强调亚马逊云科技并没有止步于性能。他介绍了规模扩展的Trainium2 Ultra服务器,这是一个庞然大物,由两个机架通过NeuronLink结构连接在一起,集成了64个Trainium2设备。它拥有惊人的80佩塔浮点密集计算能力和前所未有的185TB/秒内存带宽,定位于训练下一代基础模型的关键力量。
性能固然至关重要,但Ron强调以可持续和经济高效的方式交付性能同样重要。他解释说,Trainium2是围绕一个高效的矩阵引擎构建的,该引擎采用系统阵列结构,提供并行处理、本地通信和数据重用。这种设计不仅提高了能源效率,而且还使亚马逊云科技能够将相应的成本节约转嫁给客户。
Ron接着强调了Trainium2的垂直电源传输系统,这是对Trainium1侧向电源传输的重大改进。通过将电压调节器从卡的顶部移至底部,正好位于Trainium2芯片的正下方,亚马逊云科技降低了电源网络的阻抗,提高了整体电源完整性。这一创新使Trainium2能够在较低的标称电压下运行,进一步提高了其能源效率。
在讨论深度学习工作负载的关键方面——可扩展性时,Ron强调了简单、模块化和健壮的服务器设计,以满足对新技术大规模集群的即时需求。他展示了Trainium2的简约无线缆服务器设计,这简化了冷却解决方案并有利于大规模部署。Ron还强调了亚马逊云科技的自动化装配过程,包括主板的扭矩和内存条的插入,确保了高服务器产量并实现了制造线快速扩展。
继续向上探讨技术栈,Ron谈到了Neuron SDK,其中包括运行时、编译器和开发工具。他强调与PyTorch和Jax团队以及开放XLA项目的密切合作,确保客户偏好的框架能够无缝集成到Trainium设备上,用于分布式训练和推理。
Ron介绍了Neuron X Distributed库(NXD),它允许用户只需几行代码就能将模型分片到任意数量的训练设备上,支持张量、管道、专家和数据并行等流行的并行形式。他还强调了Neuron与各种亚马逊云科技服务、第三方库(如Hugging Face的Optimum Neuron)以及规模扩展库的集成,为大规模部署铺平了道路。
意识到深度学习创新的步伐飞快,Ron强调让客户能够在Trainium之上进行创新的重要性。他介绍了Trainium2独特的4倍稀疏加速能力,该能力通过将稀疏矩阵压缩为密集表示并在计算时跳过零值,从而加速了稀疏矩阵乘法。Trainium2支持多种稀疏格式,包括4-to-8、4-to-12和4-to-16,为新的科学实验和潜在的性能提升带来机遇。
为了验证4-to-8稀疏性的优势,Ron分享了使用三种不同技术(包括广受欢迎的Wanda以及两种内部开发的方法)对LLaMA 8B模型进行稀疏化的结果。在所有技术中,4-to-8稀疏性都能够提供比2-to-4稀疏性更高的精度。此外,当使用各种技术将LLaMA 3.8B和LLaMA 370B模型稀疏化到4-to-8时,亚马逊云科技能够完全恢复原始密集模型的质量,这是一个强有力的结果,证明了利用稀疏性可以获得2倍的加速而不会牺牲模型质量。
Ron接着讨论了混合专家模型,这是一种更粗粒度的稀疏形式,其中变压器层的前馈网络(FFN)被一组更小的FFN(称为专家)所取代。每个token只会被路由到一个专家,从而增加了模型的参数数量和智能,而不会相应地增加训练所需的计算量。为了优化Trainium2以支持此类模型,亚马逊云科技优化了动态内存寻址以匹配静态内存寻址的效率,并构建了高度优化的块稀疏计算内核。
为了在最底层实现创新,Ron介绍了Neuron Internal Interface (NIKI),这是一个用于Trainium设备的裸机编程环境。NIKI允许开发人员绕过编译器,完全控制硬件并以独特的方式优化工作负载。Ron演示了一个简单的NIKI内核,用于添加两个张量,突出了这一看似简单操作的并行化特性。
Ron分享了一个Amazon内部团队使用NIKI优化MaMBa 2状态空间模型的例子,仅用77行NIKI代码就实现了瓶颈内核的18倍加速,这是一个令人印象深刻的成就。他鼓励与会者通过提供的二维码了解更多相关细节。
Ron强调了可观测性和分析的重要性,介绍了Neuron Profiler,这是一种具有可忽略开销的非侵入式指令级跟踪。与会导致执行速度下降的其他跟踪方式不同,Neuron Profiler的低开销允许开发人员持续运行,从而有效地识别瓶颈并优化工作负载。
Ron分享了一个有趣的数据点,说明了Neuron Profiler的交互式和响应迅速的性能,这得益于一种高度优化的查询算法,用于创建跟踪数据库。有趣的是,这一算法是由Anthropic的Tristan发明的,突出了两个团队在Neuron Profiler上的密切合作。
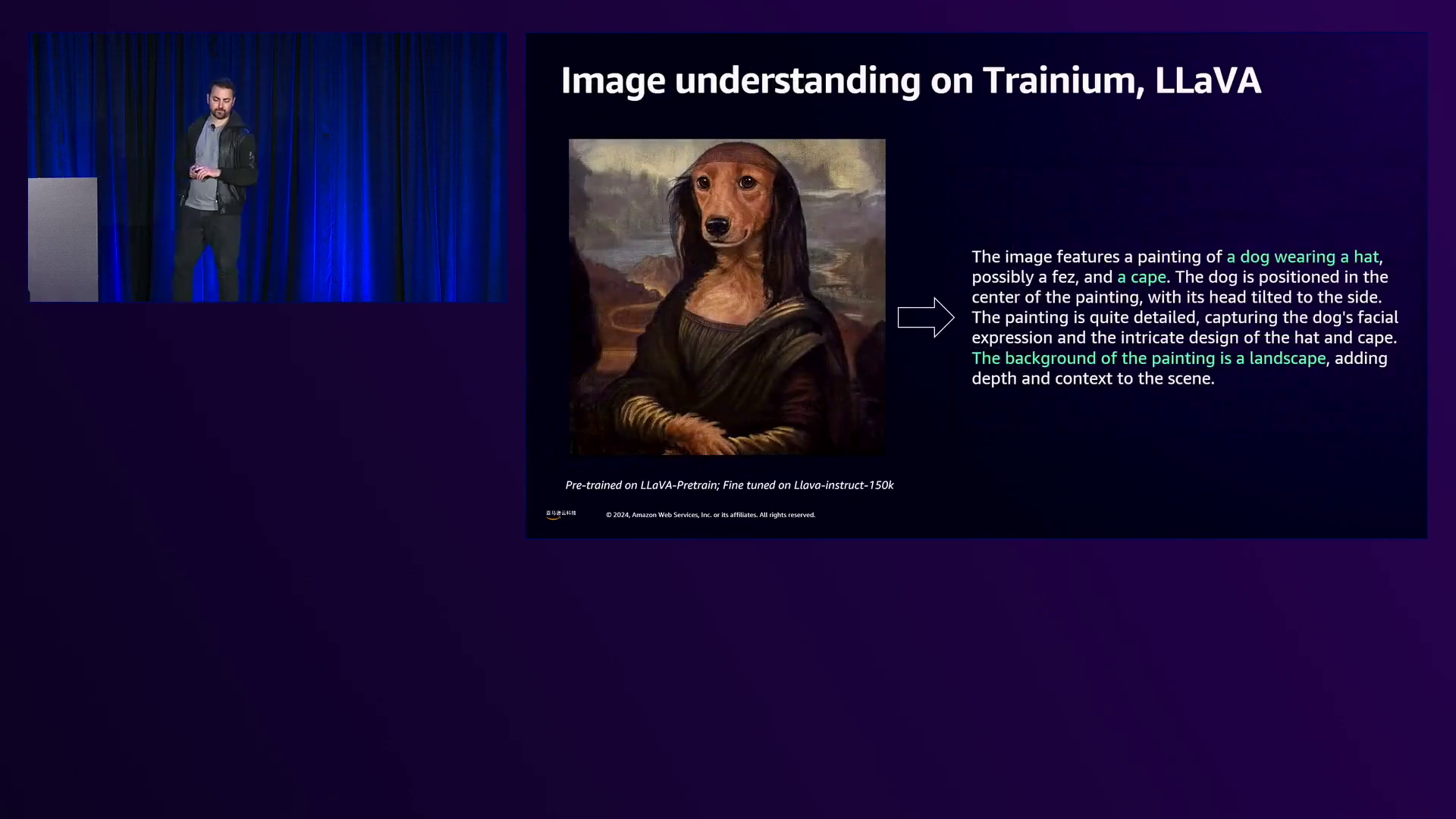
为了展示这些创新的集大成,Ron展示了客户在Trainium2上运行端到端工作负载和应用程序的实例。一位客户演示了图像理解工作负载,其中输入图像经过神经网络处理以生成描述。另一个例子展示了一种名为Pixart的扩散模型,根据“请给我们一张蓝jay站在一大篮彩虹马卡龙上的图像”的提示生成图像。该模型在训练过程中不断生成图像,展示了图像质量随时间的提高,直至最终输出高质量的图像。
在这一时刻,Ron邀请了来自Anthropic的James Bradbury分享他们与亚马逊云科技合作以及对Trainium2的押注的见解。James首先介绍了Anthropic作为一家致力于通过在能力和安全方面的行业领先基础研究来实现可信赖人工智能的公司。他强调了Anthropic的前沿大型语言模型家族Claude,该模型可通过Amazon Bedrock获取。
作为Anthropic计算团队的成员,James强调了寻找最具成本效益和可扩展性的计算平台用于他们的训练、推理、研究和所有其他运营的重要性。他解释说Anthropic选择大力押注Trainium2,尤其是用于快速、低延迟的Claude推理以及名为Project Rainier的大规模新Trainium2训练集群,后者是他们与亚马逊云科技合作进行的。
James概述了Anthropic做出这一选择的原因,首先是Trainium2出色的性价比,尤其是对于内存带宽敏感型工作负载。他赞扬了亚马逊云科技世界一流的数据中心基础设施经验和大规模容量交付的专业知识,这对于Project Rainier这种前所未有规模的集群至关重要。
James还强调了Anthropic对Trainium2中Neuron核心中灵活和可编程的硬件引擎的赞赏,这使他们能够编写低级内核并跨不同引擎管道化工作负载,从而最大化张量利用率并挤出每一分性能。他赞赏Neuron Profiler能够提供对芯片上指令执行的可见性,这是少数其他加速器所无法匹配的能力。
James对Ultra Server架构表现出兴奋,强调了它在支持更大模型上各种并行形式方面的出色可扩展性,无论是LLM推理还是训练。他赞赏了Ultra Server与NeuronLink和高带宽、低延迟EFA v3网络的组合,这使得平稳扩展到非常大的训练和推理工作负载成为可能。
James最后表达了对Anthropic与亚马逊云科技团队之间出色合作的感激,包括Ron和Annapurna团队、Joe和EC2团队以及所有参与Trainium项目的人员。
在谈到扩展到由数十万个Trainium2芯片组成的Project Rainier集群的挑战时,James强调了在整个堆栈的每一层都需要创新。Anthropic的团队已经在优化各个方面,包括并行方法、从芯片和系统中挤出每一个flop的性能,以及开发创新的可靠性和测试基础设施,以适应前所未有规模的硬件和系统故障。
James分享说,Anthropic在Trainium2工作的第一个成果已经可用:Claude 3.5 Haiku on Bedrock的延迟优化实现,与标准实现相比,输入和输出的推理速度提高了60%。这意味着每秒可输出高达125个token,具体取决于提示分布。James表示很快就会将Trainium2推理和更低延迟带给更多模型。
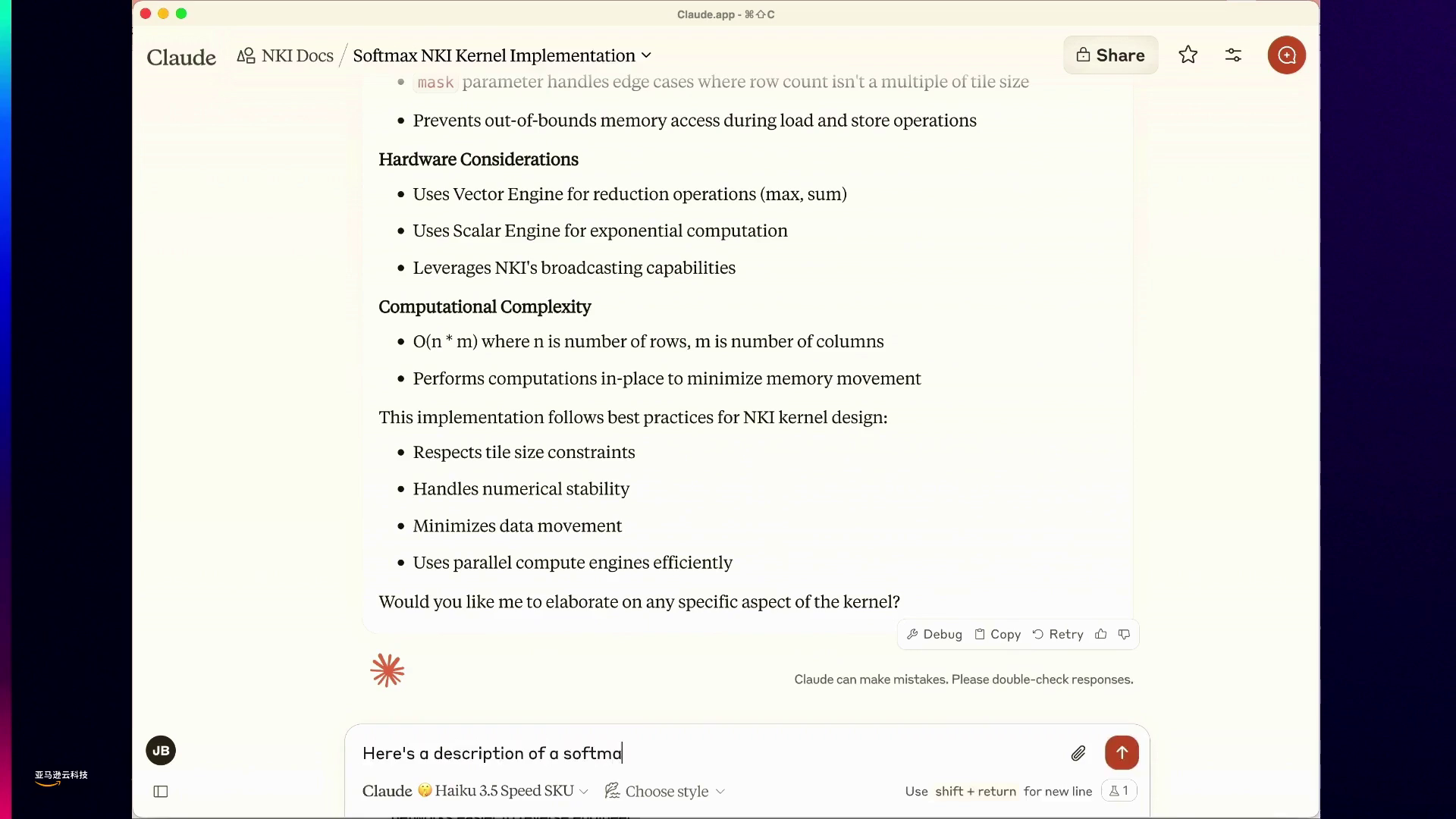
在现场演示中,James展示了连接到延迟优化的Trainium2 Haiku 3.5的ClawAI。他将NIKI文档(包括编程指南、示例内核和架构指南)加载到Claude的上下文窗口中,旨在教会这个AI一种全新的编程语言。
James提示Claude编写softmax函数的内核并解释每一行代码。当Claude处理和缓存超过10万个NIKI上下文token时,James注意到它生成代码的速度令人印象深刻,比之前的GPT-3.5等模型更快。
进一步推进边界,James粘贴了Anthropic开发的一种激活函数的描述,并要求Claude为其编写内核。令人惊讶的是,Claude成功地为它刚刚学习的这种激活函数生成了不熟悉的NIKI编程语言代码,展现了它即时适应和创新的能力。
Joe重新掌控舞台时,他提醒观众们刚刚见证了Trainium2正在为自身编写代码,这是一个展示该平台低级能力的非凡壮举。
最后,Joe重申了三个关键要点:Trainium2如今可用,在性能、能源效率和成本效率方面推动创新;并通过与Anthropic等合作伙伴的合作关系,从芯片到数据科学层,为前沿模型铺设下一层技术基础。
Joe提供了开始使用Trainium2的资源,包括Neuron文档链接和关于其他会议和研讨会的信息。他感谢Ron、James和与会者参与了这场具有开创性的会议,在会上揭示了Trainium2在AI训练和推理方面的未来。
下面是一些演讲现场的精彩瞬间:
亚马逊云科技推出了迄今为止最强大的机器学习计算服务器Traineum 2,拥有20佩塔浮点运算能力、46 TB/s的HBM带宽以及先进的互连技术。

一张Traineum 2服务器计算托盘的俯视图展示了其简约设计、无线缆架构以及单排设备布局,有利于简化冷却和可扩展部署。
亚马逊云科技展示了一位客户运行图像理解工作负载,以及一个扩散模型生成了一只蓝色的小鸟栖息在彩虹马卡龙篮子上的高分辨率图像。
展示了一个AI模型生成新型激活函数代码的惊人速度和能力,远超人类理解水平。
与Anthropic合作推出Trinium 2,这是一项突破性创新,提高了性能、能源效率、成本效率,并为前沿模型奠定了下一层技术基础。

演讲者鼓励观众探索Neuron文档并参加更多研讨会,以了解更多相关主题。

总结
揭开Trainium 2的神秘面纱: 亚马逊云科技革命性的AI加速器 助力前沿模型训练与推理
亚马逊云科技(Amazon Web Services)是全球云计算的开创者和引领者。提供200多类广泛而深入的云服务,服务全球245个国家和地区的数百万客户。做为全球生成式AI前行者,亚马逊云科技正在携手广泛的客户和合作伙伴,缔造可见的商业价值 – 汇集全球40余款大模型,亚马逊云科技为10万家全球企业提供AI及机器学习服务,守护3/4中国企业出海。

















 640
640

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









