






Amazon S3安全和访问控制最佳实践
关键字: [Amazon Web Services re:Invent 2024, 亚马逊云科技, Data Access Control, S3 Bucket Policies, Iam Roles, S3 Access Points, S3 Access Grants, Lake Formation Integration]
导读
严格遵守架构最佳实践和主动控制是数据安全的基础。Amazon S3提供了适合任何工作负载的安全设置和精细的访问控制。在本次讨论中,您将了解Amazon S3安全性的基本原理,并深入探讨最新的可用性和功能增强。探索访问控制、加密、监控、审计和修复的各种选项。发现Amazon S3中数据安全和访问控制的最佳实践。
演讲精华
以下是小编为您整理的本次演讲的精华。
在他们全面的演讲中,Meg和Becky深入探讨了确保存储在Amazon Simple Storage Service(S3)中的数据安全的复杂性,为与会者提供了大量实用见解和高级技术。
他们强调了S3的可扩展性和灵活性,它通常作为组织数据湖的中央存储库。通过在S3上托管企业的数据湖,组织可以释放无数可能性,包括利用亚马逊云科技服务产品、合作伙伴解决方案和自定义应用程序进行高级分析、机器学习和其他数据驱动工作负载。这种方法使企业能够从数据中获取更多价值,从而凸显了健全的访问控制和安全措施的重要性。
演讲者承认S3的多种用例,从存储作为各种工作负载的连接组织的配置和日志,到作为托管组织数据湖的高可用对象存储。在一个示例中,他们提到了一个组织的存储桶包含运行所有应用程序所需的配置数据的场景,突出了确保此类关键资源安全的重要性。
在讨论S3的基本安全功能时,演讲者强调了亚马逊云科技实施的三个重大变化。首先,默认情况下S3加密确保了所有新对象(无论是在新存储桶还是现有存储桶中)都会自动使用Amazon S3 Managed Keys(SSE-S3)进行加密,除非明确选择了其他服务器端加密方法,否则将应用此加密方法,有效满足了数据加密的合规性要求。
其次,默认情况下,所有新存储桶都启用了阻止公共访问功能,从而防止由于访问设置配置错误而意外暴露敏感数据。
第三,在新存储桶上默认禁用了较旧的访问控制列表(ACL)机制来管理访问权限,而更倾向于使用更健壮和细粒度的IAM策略。对于2023年之前创建的存储桶,演讲者建议启用阻止公共访问并禁用ACL,以符合最佳实践并确保使用IAM进行一致的访问控制。
在深入探讨如何有效地将IAM与S3结合使用时,演讲者提供了编写策略以授予或拒绝访问特定对象和存储桶的实际示例。在一个场景中,他们演示了如何编写策略以允许某个角色读取使用特定Amazon Key Management Service(KMS)密钥加密的对象,突出了不仅需要为S3存储桶授予权限,还需要为用于加密的KMS密钥授予权限。
为了促进现代亚马逊云科技环境中跨账户共享数据的常见做法,演讲者讨论了使用存储桶策略和PrincipalOrgID条件键来实现亚马逊云科技组织。这种方法允许组织授予特定账户或整个组织访问权限,简化了共享数据的过程,同时保持控制权。在一个示例中,他们展示了如何使用PrincipalOrgID允许组织中的所有调用者读取特定存储桶,从而简化了使用亚马逊云科技组织的组织的访问管理。
为了增强安全性并建立明确的数据边界,演讲者介绍了拒绝策略的概念。这些策略可以根据调用者的组织和网络来拒绝访问,同时排除需要合法访问的亚马逊云科技服务。在一个实际示例中,他们演示了如何编写拒绝策略,以防止来自组织外部或亚马逊云科技服务之外的访问,从而有效地围绕S3存储桶创建了一个安全边界。
此外,新推出的资源控制策略功能使使用亚马逊云科技组织的组织能够在所有现有和未来的S3存储桶上强制执行一致的拒绝语句,从而消除了手动审计的需要,并确保了安全策略的统一应用。
认识到排查和审计访问问题的重要性,演讲者强调了几个有价值的工具和功能。附加的拒绝源信息提供了对访问被拒绝原因的见解,无论是显式还是隐式的,并识别了负责的策略或资源。在一个示例中,他们展示了如何让这个功能指示拒绝是由于显式拒绝语句还是缺乏允许语句,以及拒绝是否由资源策略(如存储桶策略)引起。
Access Analyzer仪表板提供了公共和共享S3存储桶的集中视图,使组织能够快速识别和解决潜在的安全风险。演讲者演示了仪表板如何在顶部显示具有公共访问权限的存储桶,在底部显示与外部亚马逊云科技账户共享的存储桶,并提供有关允许访问的策略或ACL的详细信息,以供进一步调查。
此外,启用S3服务器访问日志和Amazon CloudTrail日志可以全面审计和监控数据访问模式。演讲者建议使用CloudTrail日志而不是S3服务器访问日志,因为CloudTrail提供了更新的功能并与其他亚马逊云科技服务更好地集成。
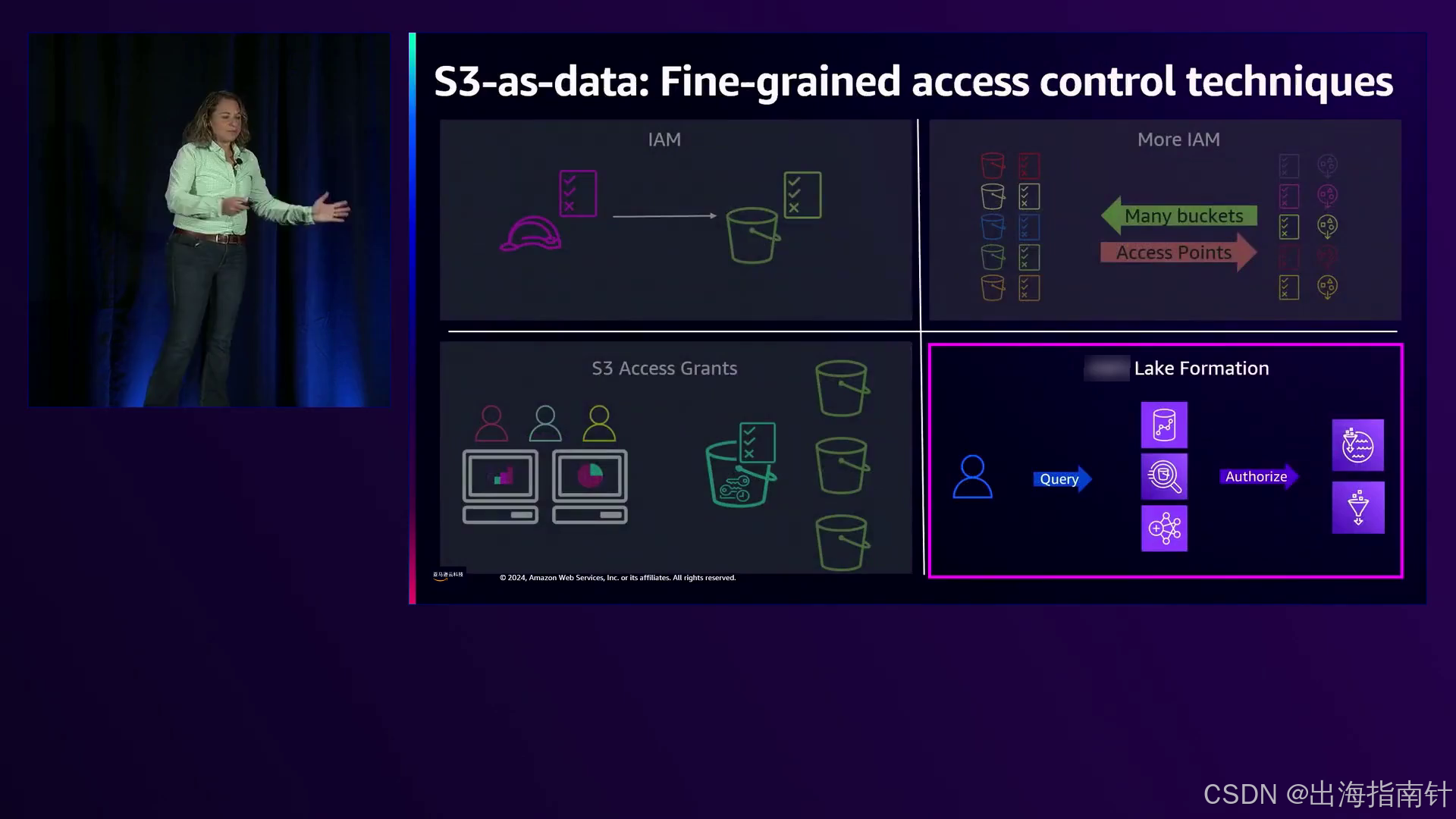
随着组织扩大数据运营并遇到不同的数据模式和用例,演讲者介绍了在S3中大规模管理访问的高级技术。对于通常使用SQL或分析工具查询的结构化数据,他们介绍了使用多个S3存储桶(每个账户最多100万个)、S3访问点(每个账户最多10,000个)和Amazon Lake Formation的方法。
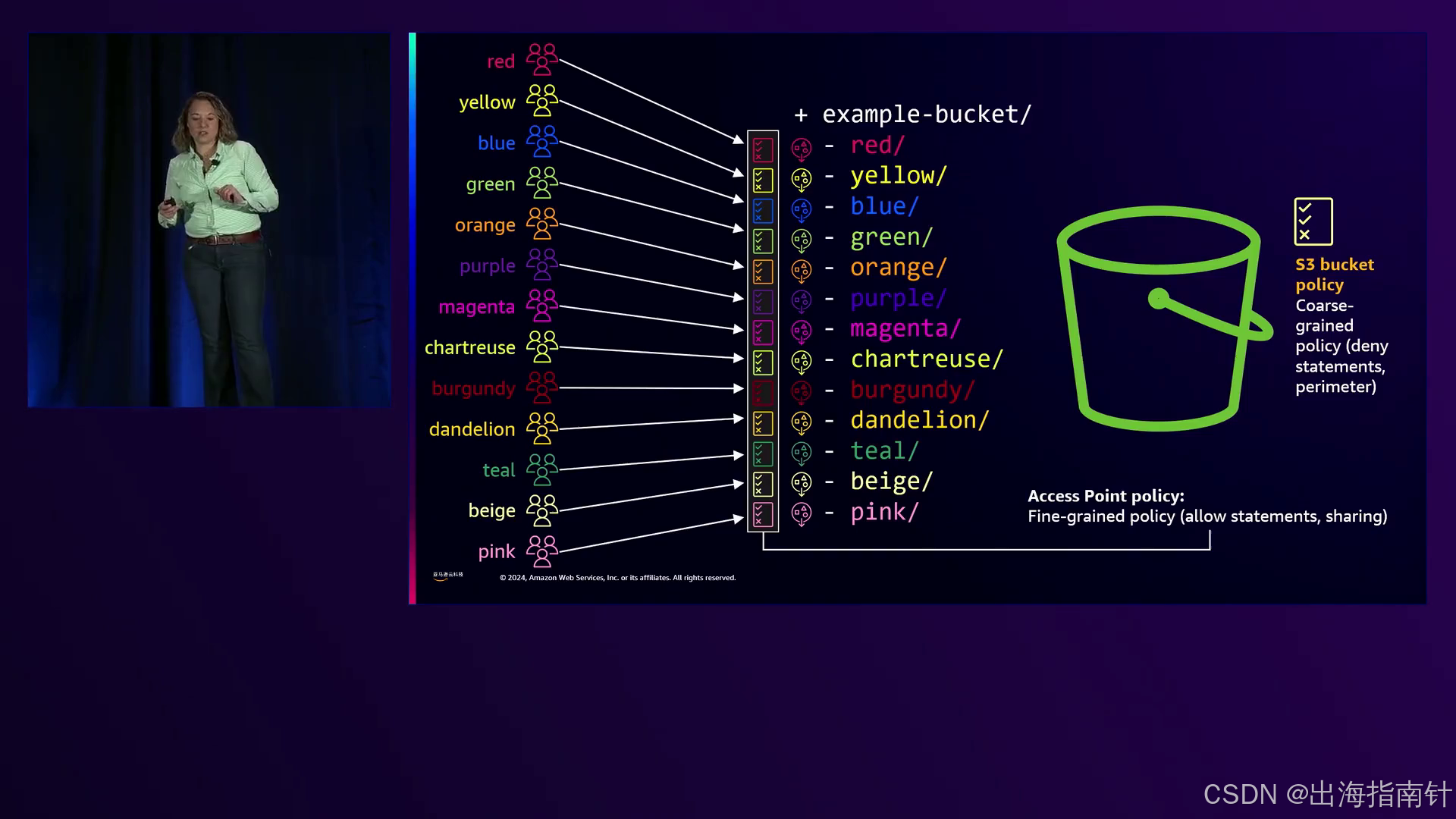
S3访问点提供了一个替代端点来访问存储在S3存储桶中的数据,允许使用单独的IAM策略和细粒度访问控制。这种方法使组织能够以不同的方式制定策略,并容纳更多的访问模式,而不会触及IAM策略大小限制。演讲者演示了应用程序需要如何更新才能通过访问点生成的存储桶别名发现和访问数据,而不是直接访问底层S3存储桶。
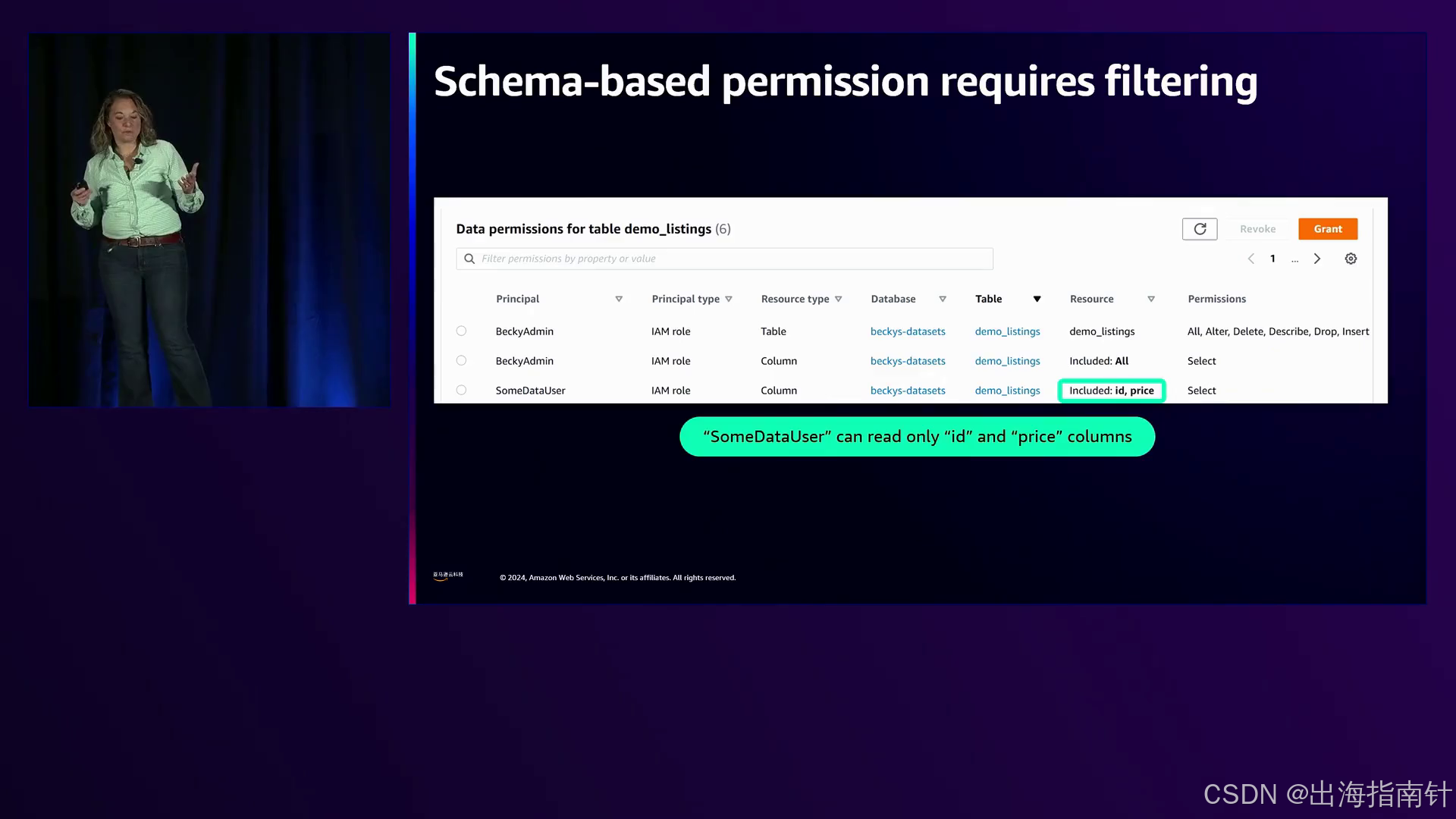
另一方面,Amazon Lake Formation专门用于管理对存储在S3和其他数据源中的结构化数据的访问。它与Amazon Glue数据目录集成,支持细粒度的列级权限,并根据数据模式强制执行访问控制。在一个示例中,演讲者展示了如何使用Lake Formation授予“某些数据用户”仅访问表的特定列的权限,而“管理查看用户”可以访问所有列。
对于非结构化数据,其访问模式涉及单独访问对象,演讲者介绍了S3访问授权。该功能允许组织直接将用户和目录组映射到数据访问权限,解决了多对多访问模式的挑战。通过与Amazon IAM Identity Center集成,S3访问授权确保了用户加入或离开组时权限会自动更新,从而消除了手动映射的需要,减少了管理开销。演讲者强调S3访问授权默认支持高达100,000个授权,为大型组织提供了充足的可扩展性。
认识到用户友好的数据协作工具的需求,演讲者演示了新的Transfer家族Web应用程序功能。该功能使组织能够单击即可围绕S3访问授权生成基本应用程序,促进用户自助式数据协作。用户可以通过熟悉的Web界面安全地访问和共享数据,而无需广泛的亚马逊云科技知识或控制台访问权限。演讲者展示了一个示例,其中属于“蓝色”和“红色”组的用户可以根据授予的权限查看和访问相应的文件夹,而仅属于“蓝色”组的另一个用户只能看到“蓝色”文件夹。
在整个演讲过程中,演讲者强调了理解不同访问控制方法的规模维度和限制的重要性。他们鼓励与会者根据数据模式、访问模式的数量以及数据是结构化还是非结构化来选择合适的方法。通过仔细考虑这些因素,组织可以实施既安全又可扩展的访问控制,确保其宝贵数据资产的保护,同时实现高效的数据访问和协作。
下面是一些演讲现场的精彩瞬间:
梅格强调亚马逊云科技将安全性作为头等大事,为她和同事Becky分享亚马逊云科技安全实践做了铺垫。

演示如何通过S3访问点访问数据,它与底层存储桶逻辑分离,实现细粒度访问控制和数据隔离。
Amazon S3访问授权简化了非结构化数据的访问控制,为多对多映射提供了可扩展且可审计的解决方案,无需中间角色。

Amazon Lake Formation为Glue数据目录提供了权限系统,根据数据架构实现了对结构化数据的访问控制。
Andy Jassy解释了Athena、Glue数据目录和Lake Formation如何协同工作,为分析查询实现对S3中数据的安全且受控访问。
Swami Sivasubramanian强调使用Amazon Lake Formation和Glue数据目录进行结构化数据分析的重要性,实现了强大的权限、ETL功能和端到端身份管理。

演讲者总结了本次讨论的重点,包括S3的默认安全功能、IAM和S3基础知识,以及大规模S3的高级访问控制方法。

总结
这篇演讲全面概述了在Amazon S3中保护数据访问的方法,涵盖了各种方法和最佳实践。它首先强调了S3的默认安全功能,如加密和阻止公共访问。然后,演讲者深入探讨了使用IAM策略和存储桶策略来控制访问的方式,解释了每种方法的细微差别和局限性。
一个关键点是强调了在选择访问控制策略时,了解您的数据访问模式的规模和复杂性的重要性。对于静态的基于角色的访问模式,IAM角色策略或使用S3访问点可以提供可扩展的解决方案。然而,对于数据湖中常见的多对多访问模式,S3访问授权(用于非结构化数据)和Amazon Lake Formation(用于结构化数据)通过与用户身份和目录组集成,提供了更高级和细粒度的控制。
演讲者还强调了最近的一些功能,如资源控制策略,用于跨多个存储桶实施数据边界,以及Access Analyzer等工具,用于审计和排查访问问题。在整个演讲过程中,他们提供了实际示例和指导,根据具体的数据访问需求和规模选择适当的访问控制方法。
最后,演讲者重申了在S3中保护数据访问的重要性,并鼓励与会者探索所介绍的各种选项,以找到最适合其用例的解决方案。他们强调亚马逊云科技提供了一系列工具和服务来满足不同的数据访问需求,从基本的IAM策略到高级的细粒度控制机制。
亚马逊云科技(Amazon Web Services)是全球云计算的开创者和引领者。提供200多类广泛而深入的云服务,服务全球245个国家和地区的数百万客户。做为全球生成式AI前行者,亚马逊云科技正在携手广泛的客户和合作伙伴,缔造可见的商业价值 – 汇集全球40余款大模型,亚马逊云科技为10万家全球企业提供AI及机器学习服务,守护3/4中国企业出海。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









