







【深度学习|迁移学习笔记】常用的迁移策略包括None Tune、Full Tune、Re-Train 和 添加适配器(Adapter) 四种策略分别是如何进行的?有何优缺点?
【深度学习|迁移学习笔记】常用的迁移策略包括None Tune、Full Tune、Re-Train 和 添加适配器(Adapter) 四种策略分别是如何进行的?有何优缺点?
文章目录
欢迎铁子们点赞、关注、收藏!
祝大家逢考必过!逢投必中!上岸上岸上岸!upupup
大多数高校硕博生毕业要求需要参加学术会议,发表EI或者SCI检索的学术论文会议论文。详细信息可关注V “
学术会议小灵通”或参考学术信息专栏:https://blog.csdn.net/2401_89898861/article/details/145551342
前言
迁移学习(Transfer Learning)是一种通过借用已经在某个任务上训练好的模型来提高另一个任务性能的方法。针对不同的迁移需求,常用的迁移策略包括None Tune、Full Tune、Re-Train 和 添加适配器(Adapter) 四种策略。这些策略主要涉及如何在目标任务中调整预训练模型的参数和架构。下面是每种策略的详细说明,以及它们的优缺点。
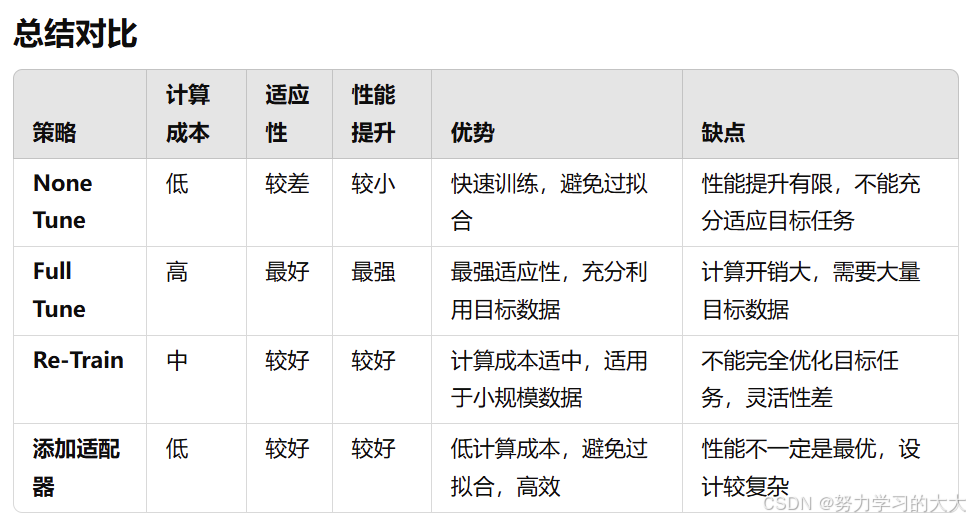
1. None Tune(无微调)
过程:
在None Tune策略中,使用的预训练模型保持完全不变,不对其进行任何参数更新。预训练模型通常在源任务上进行训练后,直接应用到目标任务中。在实际应用中,这种策略往往只是通过调整最后一层(如分类层或回归层)来适应目标任务,其他所有参数都不发生变化。
优点:
- 计算成本最低:由于没有对模型进行任何参数调整,训练过程非常快速,计算资源消耗较少。
- 避免过拟合:对于目标任务数据量较小的情况,保持模型的原始参数可以防止过拟合。
缺点:
- 性能提升有限:不进行微调意味着模型的特定特征可能无法很好地适应目标任务。特别是当源任务与目标任务差异较大时,性能提升可能较为有限。
- 无法充分利用目标任务数据:没有针对目标任务的微调,导致模型可能未能提取目标任务的最佳特征。
2. Full Tune(全量微调)
过程:
在Full Tune策略中,所有的预训练模型参数都可以更新。在目标任务上,模型的所有层都进行微调,以便让模型适应目标任务的数据和特征。这种策略的目标是让模型在源任务上学到的知识能最大限度地应用到目标任务中。
优点:
- 最强的适应性:通过对模型的所有参数进行微调,模型能够完全适应目标任务,通常能获得最好的性能。
- 充分利用目标任务数据:可以完全根据目标任务的训练数据调整模型,从而优化模型对目标任务的学习效果。
缺点:
- 计算开销大:由于模型的所有参数都需要更新,这会带来大量的计算成本,特别是对于大型模型,如Transformer类模型,训练过程可能非常耗时和资源。
- 需要大量目标任务数据:为了避免过拟合并确保微调的有效性,目标任务通常需要足够的训练数据。这对于数据量较小的任务可能不可行。
3. Re-Train(重新训练)
过程:
在Re-Train策略中,通常只对模型的部分层或结构进行训练。例如,可以只训练模型的后几层(如全连接层或卷积层),保持前面几层(通常是较低层次的特征提取层)不变。这种策略是在预训练模型的基础上进行再训练,使得模型能够适应目标任务。
优点:
- 较低计算开销:相比于全量微调,Re-Train只更新部分参数,计算开销较小。
- 较好的性能:通过调整模型的高层特征,Re-Train可以适应目标任务,通常能获得比None Tune更好的性能。
- 适用于中小规模数据:如果目标任务数据量较小,Re-Train可以避免全量微调带来的过拟合问题。
缺点:
- 可能无法充分挖掘目标任务数据的特征:由于只对部分层进行训练,Re-Train可能未能最大限度地调整模型的所有参数,可能导致模型性能不如全量微调。
- 模型的灵活性较差:与全量微调相比,Re-Train的灵活性较低,不能像全量微调那样优化模型在目标任务上的整体表现。
4. 添加适配器(Adapter)
过程:
在添加适配器策略中,原始预训练模型保持不变,但通过添加额外的小型网络(适配器)来对模型进行任务特定的调整。这些适配器通常是轻量级的神经网络模块,添加到模型的不同层之间,通常位于Transformer模型中的自注意力层或前馈网络中。训练时,只有适配器的参数被更新,预训练模型的参数保持冻结。
优点:
- 低计算成本:由于仅训练适配器参数,计算开销远低于全量微调,尤其适用于大模型(如BERT、ViT等)。
- 迁移效果好:适配器通过只修改少量参数,使得模型在新的任务上快速适应,且不会丧失预训练模型的优势。
- 避免过拟合:与全量微调相比,适配器的参数较少,因此对于小规模数据的目标任务,适配器策略能够较好地避免过拟合。
- 高效性:适配器模块可以灵活地插入到现有模型中,适用于多种迁移学习场景。
缺点:
- 可能无法获得最优性能:尽管适配器能够在许多任务中取得不错的效果,但在某些任务中,可能无法像全量微调那样发挥出最强的适应能力,尤其是当目标任务与源任务差异较大时。
- 适配器的选择和设计较为复杂:需要根据不同的任务和模型架构,设计合适的适配器结构,这可能需要一定的经验和实验。
总结
 综上所述,选择合适的迁移学习策略需要根据任务的特点、计算资源和数据量等因素进行权衡。对于大规模模型和有限计算资源的场景,添加适配器是一种非常有效的迁移策略,而在数据丰富且计算资源充足的情况下,全量微调可能会取得最好的效果。
综上所述,选择合适的迁移学习策略需要根据任务的特点、计算资源和数据量等因素进行权衡。对于大规模模型和有限计算资源的场景,添加适配器是一种非常有效的迁移策略,而在数据丰富且计算资源充足的情况下,全量微调可能会取得最好的效果。
欢迎铁子们点赞、关注、收藏!
祝大家逢考必过!逢投必中!上岸上岸上岸!upupup
大多数高校硕博生毕业要求需要参加学术会议,发表EI或者SCI检索的学术论文会议论文:
可访问艾思科蓝官网,浏览即将召开的学术会议列表。会议详细信息可参考:https://ais.cn/u/EbMjMn



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











