







【深度学习|学习笔记】高斯混合模型(Gaussian Mixture Model,GMM)详解,附代码。
【深度学习|学习笔记】高斯混合模型(Gaussian Mixture Model,GMM)详解,附代码。
文章目录
欢迎铁子们点赞、关注、收藏!
祝大家逢考必过!逢投必中!上岸上岸上岸!upupup
大多数高校硕博生毕业要求需要参加学术会议,发表EI或者SCI检索的学术论文会议论文。详细信息可关注VX “
学术会议小灵通”或参考学术信息专栏:https://blog.csdn.net/2401_89898861/article/details/146957966
前言
本文先给出对高斯混合模型(GMM)的综合概览,然后分四大部分详细论述:起源与发展、模型原理、典型应用,以及 Python 实现示例。
- 高斯混合模型(Gaussian Mixture Model,GMM)是一类典型的概率生成模型,用若干个高斯分布按权重线性组合来拟合复杂数据分布。
- GMM 最早可追溯到 19 世纪末 Pearson 对混合分布的研究,真正成为机器学习主流方法则依赖于 1977 年 EM 算法的提出。
- 其核心通过“期望–最大化”(EM)迭代估计隐变量和参数,兼具灵活的非线性拟合能力与良好的可解释性。
- GMM 广泛应用于聚类、密度估计、异常检测、图像分割、市场细分等领域。
- 在 Python 中,可通过 scikit-learn、astroML、pyGMM 等库一行代码完成模型训练与预测,并可结合信息准则(AIC/BIC)实现组分数自动选择。
1 起源与发展
1.1 Pearson 与混合分布的早期研究
- 1894 年,Karl Pearson 在研究头部尺寸数据时首次提出用两个正态分布混合来拟合偏态数据,为后来的混合模型奠定了概念基础。
1.2 EM 算法使 GMM 成为可行方法
- 1977 年,Dempster、Laird 和 Rubin 在经典论文中提出了“期望–最大化”(EM)算法,用于含有隐变量的概率模型的极大似然估计,为 GMM 参数估计提供了通用可行的迭代框架。
1.3 GMM 在模式识别中的普及
- 1973 年,Duda 和 Hart 在其著作《Pattern Classification and Scene Analysis》中推广了高斯混合用于模式分类与聚类,推动 GMM 在信号处理与计算机视觉领域的应用。
- 1990 年代后,随着计算机算力提升与算法优化,GMM 与 EM 的组合成为语音识别(GMM-HMM)、图像分割、市场细分等系统的核心组件。
2 模型原理
2.1 混合高斯分布
GMM 假设数据生成于
K
K
K 个高斯分布的混合:
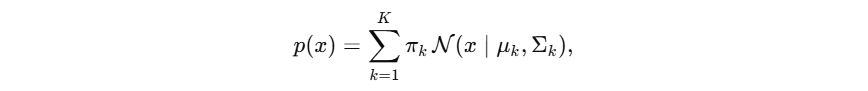
- 其中 π k π_k πk 为第 k 个分量的权重( ∑ π k = 1 ∑π_k =1 ∑πk=1), μ k μ_k μk , Σ k Σ_k Σk 分别为其均值和协方差。
2.2 EM 迭代估计
- E 步(Expectation): 计算后验概率 γ i k = p ( z i = k ∣ x i ) γ_{ik}=p(z_i=k∣x_i) γik=p(zi=k∣xi),即每个样本属于各分量的责任度。
- M 步(Maximization): 以责任度为权重重新估计
π
k
π_k
πk,
μ
k
μ_k
μk ,
Σ
k
Σ_k
Σk
,使得数据的期望完整对数似然最大化。 - 该过程等价于在函数空间对对数似然进行交替优化,直至收敛。
2.3 组分数与协方差类型选择
- 可通过 Akaike 信息准则(AIC)或贝叶斯信息准则(BIC)对不同 K、不同协方差结构(‘full’,‘tied’,‘diag’,‘spherical’)的模型进行比较与选择。
3 应用领域
- 聚类与密度估计: 相较于 K-means 假设球形簇,GMM 能拟合各向异性簇,常用于生物信息学、市场细分、图像分割等。
- 异常检测: 低密度区域被视为异常,GMM 在金融欺诈检测、机械故障预警中得到应用。
- 语音与信号处理: 传统语音识别系统中,声学特征常以 GMM-HMM 组合建模;在雷达、通信中用于信号分离。
- 生成建模: 作为早期生成模型,GMM 可用于数据增强、样本合成,并与深度模型结合实现混合生成架构。
4 Python 实现示例
下面用 scikit-learn 和 astroML 演示 GMM 的典型用法。
4.1 scikit-learn 中的 GaussianMixture
from sklearn.mixture import GaussianMixture
import numpy as np
# 生成示例数据:三组一维正态
rng = np.random.RandomState(0)
X = np.concatenate([
rng.normal(-2, 0.5, 200),
rng.normal(0, 1.0, 300),
rng.normal(3, 0.7, 150)
]).reshape(-1,1)
# 用 BIC 选出最佳组分数
bics = []
models = []
for k in range(1,6):
gm = GaussianMixture(n_components=k, covariance_type='full', random_state=0).fit(X)
bics.append(gm.bic(X))
models.append(gm)
best_k = np.argmin(bics)+1
gmm = models[best_k-1]
print(f"Selected {best_k} components") # 输出最优 K :contentReference[oaicite:11]{index=11}
# 预测每个样本的分量概率与类别
probs = gmm.predict_proba(X)
labels = gmm.predict(X)
4.2 astroML 中的 1D GMM 可视化
from astroML.mixins import GaussianKDE
import numpy as np
import matplotlib.pyplot as plt
# astroML 提供基于 EM 的 GMM 类
from astroML.density_estimation import GMM1D
# 拟合一维 GMM
gmm1d = GMM1D(n_components=3).fit(X.ravel())
x = np.linspace(-6,6,400)
pdf = np.exp(gmm1d.score_samples(x))
plt.hist(X, bins=30, density=True, alpha=0.5)
plt.plot(x, pdf, '-k', label='GMM PDF')
plt.legend()
plt.show() # 绘制混合密度与直方图​:contentReference[oaicite:12]{index=12}
以上内容系统地回顾了 GMM 的历史渊源与关键里程碑、模型数学原理、主要应用场景,以及在 Python 中使用 scikit-learn 与 astroML 进行训练与预测的典型示例,帮助全面掌握 Gaussian Mixture Model。


















 6014
6014

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











