







【深度学习|学习笔记】 生成对抗网络 GAN(Generative Adversarial Network)详解,附代码。
【深度学习|学习笔记】 生成对抗网络 GAN(Generative Adversarial Network)详解,附代码。
文章目录
欢迎铁子们点赞、关注、收藏!
祝大家逢考必过!逢投必中!上岸上岸上岸!upupup
大多数高校硕博生毕业要求需要参加学术会议,发表EI或者SCI检索的学术论文会议论文。详细信息可关注VX “
学术会议小灵通”或参考学术信息专栏:https://blog.csdn.net/2401_89898861/article/details/146957966
前言
本文先给出对 GAN(Generative Adversarial Network)模型的核心观点总结,然后依次从“起源与发展”、“模型原理”、“应用领域”以及“Python 实现”四个方面展开详细论述。
- GAN 于 2014 年由 Goodfellow 等人提出,通过“生成网络”与“判别网络”在零和博弈中的对抗训练,实现对数据分布的高质量拟合与样本生成。
- 自原始 GAN 以来,DCGAN、WGAN、StyleGAN 等关键改进相继出现,解决了训练不稳定与模式崩溃等问题。
- GAN 已广泛应用于图像合成、超分辨率、域适应、数据增强等领域。
- 在 Python 中,可借助 PyTorch、TensorFlow、pyGAM 等生态轻松实现,并通过改进损失函数与网络结构获得业界领先效果。
1 起源与发展
- 2014 年,Ian Goodfellow 等在 arXiv 上首次提出 GAN 框架,定义了生成器 G G G 与判别器 D D D 的最小–最大对抗损失,奠定了对抗式学习的基础。
- 同年,Wikipedia 梳理了 GAN 的基本概念与无监督学习背景,指出其以博弈论视角实现生成模型训练的新范式。
- 2015 年,Radford 等提出 DCGAN,将卷积网络成功引入 GAN 架构,显著提升生成图像质量并促进无监督特征学习。
- 2017 年,Arjovsky 等针对原始 GAN 易崩溃、梯度消失问题,提出 Wasserstein GAN(WGAN),利用 Earth-Mover 距离改进训练稳定性与收敛性。
- 随后,Gulrajani 等在 WGAN 基础上提出 Gradient Penalty(WGAN-GP),进一步优化 Lipschitz 约束的实现,成为工业界常用方案之一。
- 2018–2020 年,StyleGAN、CycleGAN、BigGAN 等多种变体相继问世,推动 GAN
在高分辨率人脸生成、图像风格迁移、大规模图像分类等方向取得突破性进展。
2 模型原理
- GAN 架构包含两个网络:生成器
G
(
z
;
θ
g
)
G(z;θ_g)
G(z;θg) 接受噪声
z
z
z 输出“假样本”,判别器
D
(
x
;
θ
d
)
D(x;θ_d)
D(x;θd) 对输入判别真伪;训练目标是
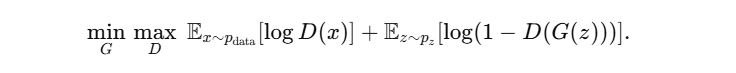
该最小–最大博弈等价于 JS 散度最小化。 - 在 DCGAN 中,生成器使用反卷积(fractional-strided convolution)逐步上采样,判别器使用下采样卷积,并在两侧加入 BatchNorm 与 LeakyReLU,以稳定训练。
- WGAN 用 Wasserstein-1 距离替代 JS 散度,判别器(称为“Critic”)不加 sigmoid 而直接输出实数评分,并通过权重裁剪或梯度惩罚保障 1-Lipschitz 条件,从而缓解模式崩溃与梯度消失。
- 此外,诸如 Least-Squares GAN、Hinge-Loss GAN、Relativistic GAN 等多种损失变体被提出,用以改善判别信号和生成样本多样性。
3 应用领域
- 图像生成与编辑:从人脸(StyleGAN)到场景(BigGAN),GAN 可生成高保真、可操控的合成图像。
- 图像-to-图像 翻译:Pix2Pix、CycleGAN 等模型实现无监督的风格迁移、图像修复与域适应。
- 数据增强:在医学影像、遥感影像中,用 GAN 生成稀缺类别样本以平衡数据分布,提升下游分类或分割性能。
- 超分辨率重建:SRGAN 等将低分辨率图像提升至高清细节,在监控、卫星遥感等领域获得工程应用。
- 文本与语音生成:Conditional GAN 可用于文本到语音、语音风格转换,以及基于 GAN 的文本生成探索。
- 强化学习与仿真:GAN 用于生成环境模拟、策略对抗训练等场景,实现更高效的样本生成与策略优化。
4 Python 实现示例(PyTorch)
下面以最经典的 MNIST 简易 GAN 为例,演示生成器、判别器定义及训练流程:
import torch, torch.nn as nn, torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
# 1. 数据加载
dataset = datasets.MNIST(".", download=True,
transform=transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,),(0.5,))]))
loader = DataLoader(dataset, batch_size=128, shuffle=True)
# 2. 网络定义
class Generator(nn.Module):
def __init__(self):
super().__init__()
self.net = nn.Sequential(
nn.Linear(100, 256), nn.ReLU(True),
nn.Linear(256, 512), nn.ReLU(True),
nn.Linear(512, 1024), nn.ReLU(True),
nn.Linear(1024, 28*28), nn.Tanh()
)
def forward(self, z):
return self.net(z).view(-1,1,28,28)
class Discriminator(nn.Module):
def __init__(self):
super().__init__()
self.net = nn.Sequential(
nn.Flatten(),
nn.Linear(28*28, 512), nn.LeakyReLU(0.2,True),
nn.Linear(512, 256), nn.LeakyReLU(0.2,True),
nn.Linear(256, 1), nn.Sigmoid()
)
def forward(self, x):
return self.net(x)
G, D = Generator().cuda(), Discriminator().cuda()
optG = optim.Adam(G.parameters(), lr=2e-4, betas=(0.5,0.999))
optD = optim.Adam(D.parameters(), lr=2e-4, betas=(0.5,0.999))
criterion = nn.BCELoss()
# 3. 训练循环
for epoch in range(20):
for real, _ in loader:
real = real.cuda()
bsz = real.size(0)
# 判别器训练
z = torch.randn(bsz,100).cuda()
fake = G(z).detach()
lossD = criterion(D(real), torch.ones(bsz,1).cuda()) + \
criterion(D(fake), torch.zeros(bsz,1).cuda())
optD.zero_grad(); lossD.backward(); optD.step()
# 生成器训练
z = torch.randn(bsz,100).cuda()
lossG = criterion(D(G(z)), torch.ones(bsz,1).cuda())
optG.zero_grad(); lossG.backward(); optG.step()
print(f"Epoch {epoch}: D_loss {lossD.item():.4f}, G_loss {lossG.item():.4f}")
- 上述代码展示了 GAN 的核心对抗训练流程:交替优化 D D D 与 G G G 的损失函数。
- 在简单架构上可扩展为 DCGAN,只需将全连接层替换为转置卷积与卷积层,并加入 BatchNorm,即可生成更高质量图像。
通过上述讲解,既能掌握 GAN 的历史渊源与主要改进,也可理解其原理与多领域应用,并可在 Python 中快速实现和扩展,对 GAN 的研究与工程落地具备完整的知识体系。


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











