






总览
数学能力是大语言模型推理水平的重要体现。上海人工智能实验室在推出领先的开源数学模型InternLM2-Math的三个月之后对其进行了升级,发布了全新的 InternLM2-Math-Plus。升级后的 InternLM2-Math-Plus 在预训练和微调数据方面进行了全面的优化,显著提高了其在自然语言推理、代码解题以及形式化数学语言上的性能。模型包括了 1.8B、7B、20B、8x22B 四种不同尺寸的版本,其中 1.8B、7B、20B 版本基于 InternLM2 基座,而 8x22B 版本则基于 Mixtral-8x22B 基座。 我们在权威数学测试集 MATH(英文)和 MathBench(中英文)上进行了自然语言数学能力的测试。在性能方面,在每个级别的模型都超过了该级别的开源 SOTA 模型,其中 7B 版本则超过了 7B 的最强开源模型 Deepseek-Math-7B-RL,而 8x22B 的表现超过了国内的闭源模型且可以和 GPT-4-Turbo 相媲美。 在 MATH 测试集上,1.8B、7B、20B、8x22B 参数版本在 MATH 测试中的得分分别为 37.0、53.0、53.8 和 58.1 分。借助 Python 解释器,InternLM2-Math-Plus 在 MATH 上可以进一步取得 41.5、59.7、61.8 和 68.5 分的成绩,创开源模型的新高。 除此之外,InternLM2-Math-Plus 通过强化学习强化了形式化语言证明数学定理的能力。我们在开源数据集 MiniF2F-test 上进行了测试,其包含了不同难度的初高中数学竞赛中的题目。InternLM2-Math-Plus 在 MiniF2F-test 上达到了43.4 (pass@1)的性能,超过了之前 Meta 的算法 HTPS 的 41.0 的性能。 InternLM2-Math-Plus 的代码和模型完全开源,并支持免费商用。
-
GitHub:https://github.com/InternLM/InternLM-Math
-
Huggingface:https://huggingface.co/internlm
-
技术报告:https://arxiv.org/abs/2402.06332
-
在线试用:https://huggingface.co/spaces/internlm/internlm2-math-7b
下图是 InternLM2-Math-Plus 正确地解决了 2023 的高考题目的例子:

下图是 InternLM2-Math-Plus 通过代码解释器正确解决中国高中数学联赛一试题目的例子:

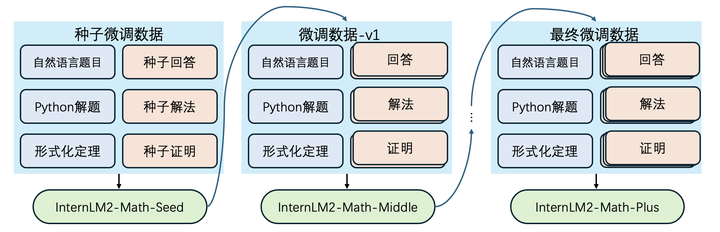
预训练和微调策略改进
InternLM2-Math-Plus 更新了预训练数据清洗的管线,从网页、书籍、论坛、代码等渠道重新清理了约百B的预训练数据,保证了模型在继续预训练阶段尽可能学到广泛的数学知识。在微调阶段,我们使用专家迭代的算法进行微调数据的构造。在每轮训练时,我们使用当前的 SFT 数据训练我们的模型,并用模型的自洽投票更新 SFT 数据。模型的最终微调来自多轮迭代后的训练数据。实践发现,专家迭代算法在不同参数量的模型(1.8B、7B、20B、8x22B)和不同任务(自然语言推理、Python 推理、形式语言证明)上都有提升。
媲美闭源模型的数学性能
我们先在数学榜单 MATH 上检验我们模型的性能。相比于 InternLM2-Math,InternLM2-Math-Plus 在自然语言数学推理和代码数学解题上都有明显的提升。在不同参数量的模型中,InternLM2-Math-Plus 都为同尺寸的最强开源模型。InternLM2-Math-Plus-Mixtral8x22B 在 MATH 上的准确率为 58.1(使用自然语言推理)、68.5(使用Python),刷新了开源模型的性能上限。
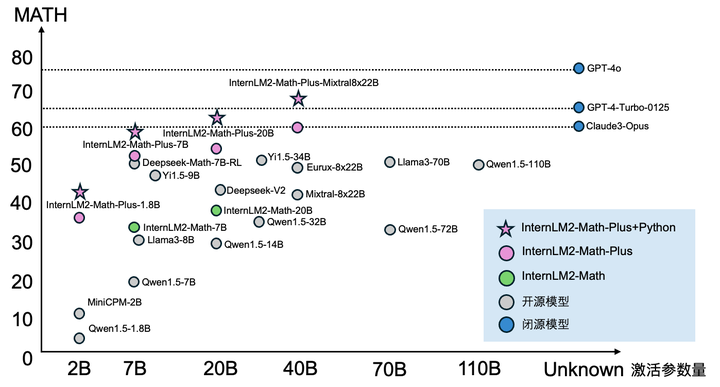
大多数数学模型都在 MATH 和 GSM8K 上进行了领域内增强,为了检测模型的泛化能力。我们测试了模型在 MathBench 上不同学段的应用题性能。可以看出模型在不同的学段都表现出一致的优越性,性能整体超过 Llama3、Qwen、Deepseek 等系列模型。InternLM2-Math-Plus-Mixtral8x22B 的性能更超过了 Qwen-Max-0428、Deepseek-V2、Llama-3-70B-Instruct 等重量级模型,和 Claude-3 Opus 表现得旗鼓相当。InternLM2-Math-Plus 系列在大学、高中等难度更大的题目上优势更大。


增强的形式化数学语言能力
语言模型在数学解题上已经有了长足的进步,但还不擅长数学定理的证明。人类本身也很难判定模型定理证明的正确性。形式化数学语言(如 LEAN、Coq 等)可以用来自动判别数学定理的正确性。除了更强的自然语言和 Python解题能力,InternLM2-Math-Plus 对形式化数学语言 LEAN 4 增强了适配。InternLM2-Math-Plus 通过多轮主动学习提升了自然语言和 LEAN 语言的双向翻译能力,通过专家迭代大幅增强了定理证明的能力。InternLM2-Math-Plus-7B在MiniF2F-test 的数据集上获得了单次采样 43.4 的证明准确率。超过了 Meta 的闭源 HTPS 算法的 41.0 的性能,也优于 Deepseek-Prover 的 30.0 的单次采样证明率。(注释为人做的解释,并非模型生成)

llm
总结
InternLM2-Math-Plus 对自然语言能力和形式推理能力都进行了全面升级,成为开源数学模型的新标杆。InternLM2-Math-Plus 的未来发展方向是基于自然语言推理能力、Python 计算能力、LEAN 的证明能力三者融合的自我迭代提升。InternLM2-Math-Plus 在各项数学能力上都得到了提升。 为了进一步推动对语言模型的理解和数学能力的发展,我们希望与学术社区和研究人员一起合作,共同探索如何提升语言模型在数学推理上的能力。我们在这个方向长期招聘实习生,欢迎感兴趣的同学投递openmmlab@pjlab.org.cn进行咨询。















 6万+
6万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









