






在今年6月30日,上海人工智能实验室发布了最新的浦语灵笔InternLM2.5-7B,在距离2024年1月17日5个月左右的时间后,InternLM2.5-7B新鲜出炉,并且他们声称在数学推理方面超过了Llama3和Gemma2-9B。
浦语灵笔介绍
浦语·灵笔2.5是基于书生·浦语2大语言模型研发的突破性的图文多模态大模型,仅使用 7B LLM 后端就达到了 GPT-4V 级别的能力。浦语·灵笔2.5使用24K交错的图像-文本上下文进行训练,通过RoPE外推可以无缝扩展到96K长的上下文。这种长上下文能力使浦语·灵笔2.5在需要广泛输入和输出上下文的任务中表现出色
其具有以下特性:
卓越的推理性能:在数学推理方面取得了同量级模型最优精度,超越了 Llama3 和 Gemma2-9B。
有效支持百万字超长上下文:模型在 1 百万字长输入中几乎完美地实现长文“大海捞针”,而且在 LongBench 等长文任务中的表现也达到开源模型中的领先水平。 可以通过 LMDeploy 尝试百万字超长上下文推理。更多内容和文档对话 demo 请查看这里。
工具调用能力整体升级:InternLM2.5 支持从上百个网页搜集有效信息进行分析推理,相关实现将于近期开源到 Lagent。InternLM2.5 具有更强和更具有泛化性的指令理解、工具筛选与结果反思等能力,新版模型可以更可靠地支持复杂智能体的搭建,支持对工具进行有效的多轮调用,完成较复杂的任务。可以查看更多样例。
摘自:InternLM/README_zh-CN.md at main · InternLM/InternLM · GitHub
而且目前只发布了7B的版本,后续上海人工智能实验室还会陆续开源1.8B和20B的版本,20B 模型的综合性能更为强劲,可以有效支持更加复杂的实用场景。
他们还有许多衍生的模型:
-
InternLM2.5:经历了大规模预训练的基座模型,是我们推荐的在大部分应用中考虑选用的优秀基座。
-
InternLM2.5-Chat: 对话模型,在 InternLM2.5 基座上经历了有监督微调和 online RLHF。InternLM2.5-Chat 面向对话交互进行了优化,具有较好的指令遵循、共情聊天和调用工具等的能力,是我们推荐直接用于下游应用的模型。
-
InternLM2.5-Chat-1M: InternLM2.5-Chat-1M 支持一百万字超长上下文,并具有和 InternLM2.5-Chat 相当的综合性能表现。
如果想体验的话,可以去HF等平台体验
| Model | Transformers(HF) | ModelScope(HF) | OpenXLab(HF) | OpenXLab(Origin) | Release Date |
|---|---|---|---|---|---|
| InternLM2.5-7B | 🤗internlm2_5-7b | internlm2_5-7b | OpenXLab浦源 - 模型中心 | OpenXLab浦源 - 模型中心 | 2024-07-03 |
| InternLM2.5-7B-Chat | 🤗internlm2_5-7b-chat | internlm2_5-7b-chat | OpenXLab浦源 - 模型中心 | OpenXLab浦源 - 模型中心 | 2024-07-03 |
| InternLM2.5-7B-Chat-1M | 🤗internlm2_5-7b-chat-1m | internlm2_5-7b-chat-1m | OpenXLab浦源 - 模型中心 | OpenXLab浦源 - 模型中心 | 2024-07-03 |
模型性能
现列举一下模型的特性:
-
卓越的推理性能:在数学推理方面取得了同量级模型最优精度,超越了 Llama3 和 Gemma2-9B。
-
有效支持百万字超长上下文:模型在 1 百万字长输入中几乎完美地实现长文“大海捞针”,而且在 LongBench 等长文任务中的表现也达到开源模型中的领先水平。 可以通过 LMDeploy 尝试百万字超长上下文推理。更多内容和文档对话 demo 请查看这里。
-
工具调用能力整体升级:InternLM2.5 支持从上百个网页搜集有效信息进行分析推理,相关实现将于近期开源到 Lagent。InternLM2.5 具有更强和更具有泛化性的指令理解、工具筛选与结果反思等能力,新版模型可以更可靠地支持复杂智能体的搭建,支持对工具进行有效的多轮调用,完成较复杂的任务。可以查看更多样例。
再展示一下该模型在主流测试项目上的表现:
基座模型
| Benchmark | InternLM2.5-7B | Llama3-8B | Yi-1.5-9B |
|---|---|---|---|
| MMLU (5-shot) | 71.6 | 66.4 | 71.6 |
| CMMLU (5-shot) | 79.1 | 51.0 | 74.1 |
| BBH (3-shot) | 70.1 | 59.7 | 71.1 |
| MATH (4-shot) | 34.0 | 16.4 | 31.9 |
| GSM8K (4-shot) | 74.8 | 54.3 | 74.5 |
| GPQA (0-shot) | 31.3 | 31.3 | 27.8 |
对话模型
| Benchmark | InternLM2.5-7B-Chat | Llama3-8B-Instruct | Gemma2-9B-IT | Yi-1.5-9B-Chat | GLM-4-9B-Chat | Qwen2-7B-Instruct |
|---|---|---|---|---|---|---|
| MMLU (5-shot) | 72.8 | 68.4 | 70.9 | 71.0 | 71.4 | 70.8 |
| CMMLU (5-shot) | 78.0 | 53.3 | 60.3 | 74.5 | 74.5 | 80.9 |
| BBH (3-shot CoT) | 71.6 | 54.4 | 68.2* | 69.6 | 69.6 | 65.0 |
| MATH (0-shot CoT) | 60.1 | 27.9 | 46.9 | 51.1 | 51.1 | 48.6 |
| GSM8K (0-shot CoT) | 86.0 | 72.9 | 88.9 | 80.1 | 85.3 | 82.9 |
| GPQA (0-shot) | 38.4 | 26.1 | 33.8 | 37.9 | 36.9 | 38.4 |
我们使用
ppl对基座模型进行 MCQ 指标的评测。评测结果来自 OpenCompass ,评测配置可以在 OpenCompass 提供的配置文件中找到。
由于 OpenCompass 的版本迭代,评测数据可能存在数值差异,因此请参考 OpenCompass 的最新评测结果。
* 表示从原论文中复制而来。
摘自:InternLM/README_zh-CN.md at main · InternLM/InternLM · GitHub
技术细节&流程
训练数据来源万卷CC
WanJuan2.0(WanJuan-CC) 是从CommonCrawl获取的一个 1T Tokens 的高质量英文网络文本数据集。结果显示,与各类开源英文CC语料在 Perspective API 不同维度的评估上,WanJuan2.0 都表现出更高的安全性。此外,通过在4个验证集上的困惑度(PPL)和6下游任务的准确率,也展示了WanJuan2.0 的实用性。WanJuan2.0 在各种验证集上的PPL表现出竞争力,特别是在要求更高语言流畅性的tiny-storys等集上。通过与同类型数据集进行1B模型训练对比,使用验证数据集的困惑度(perplexity)和下游任务的准确率作为评估指标,实验证明,WanJuan2.0 显著提升了英文文本补全和通用英文能力任务的性能。
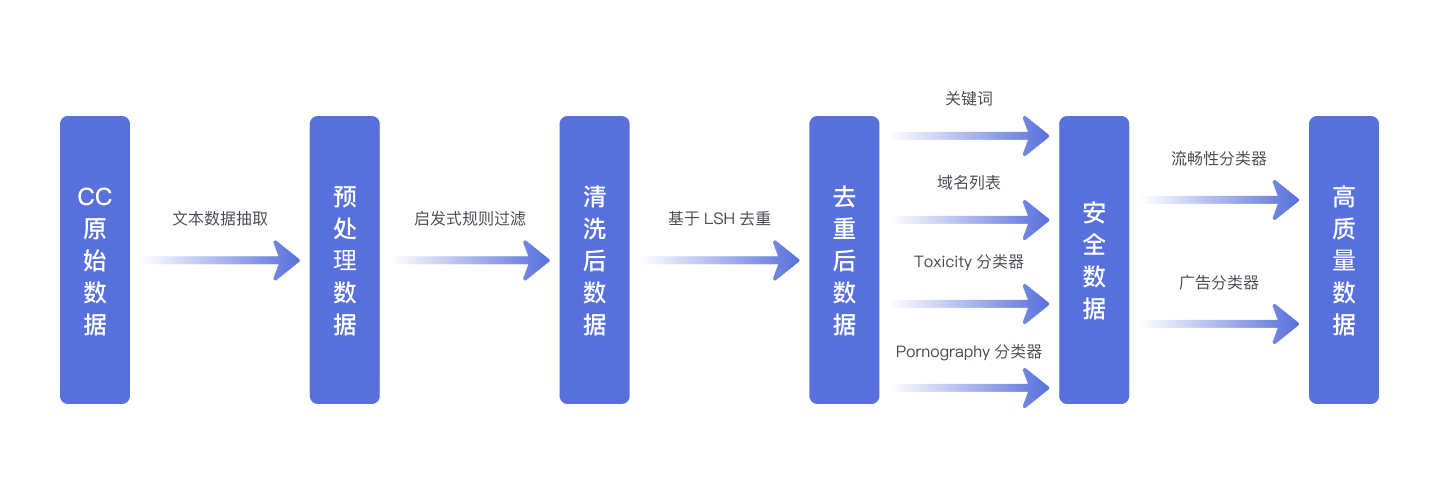
从Common Crawl的WARC格式数据中提取文本,得到"原始数据"(Raw data)。
通过启发式规则对原始数据进行过滤,生成"清洗数据"(Clean data)。
利用基于LSH的去重方法对清洗数据进行处理,得到"无重复数据"(Dedup data)。
使用基于关键词和域名列表的过滤方法,以及基于Bert的有害内容分类器和淫秽内容分类器对无重复数据进行过滤,产生"安全数据"(Safe data)。
采用基于Bert的广告分类器和流畅性分类器对安全数据进行进一步过滤,得到"高质量数据"(High-Quality data)。
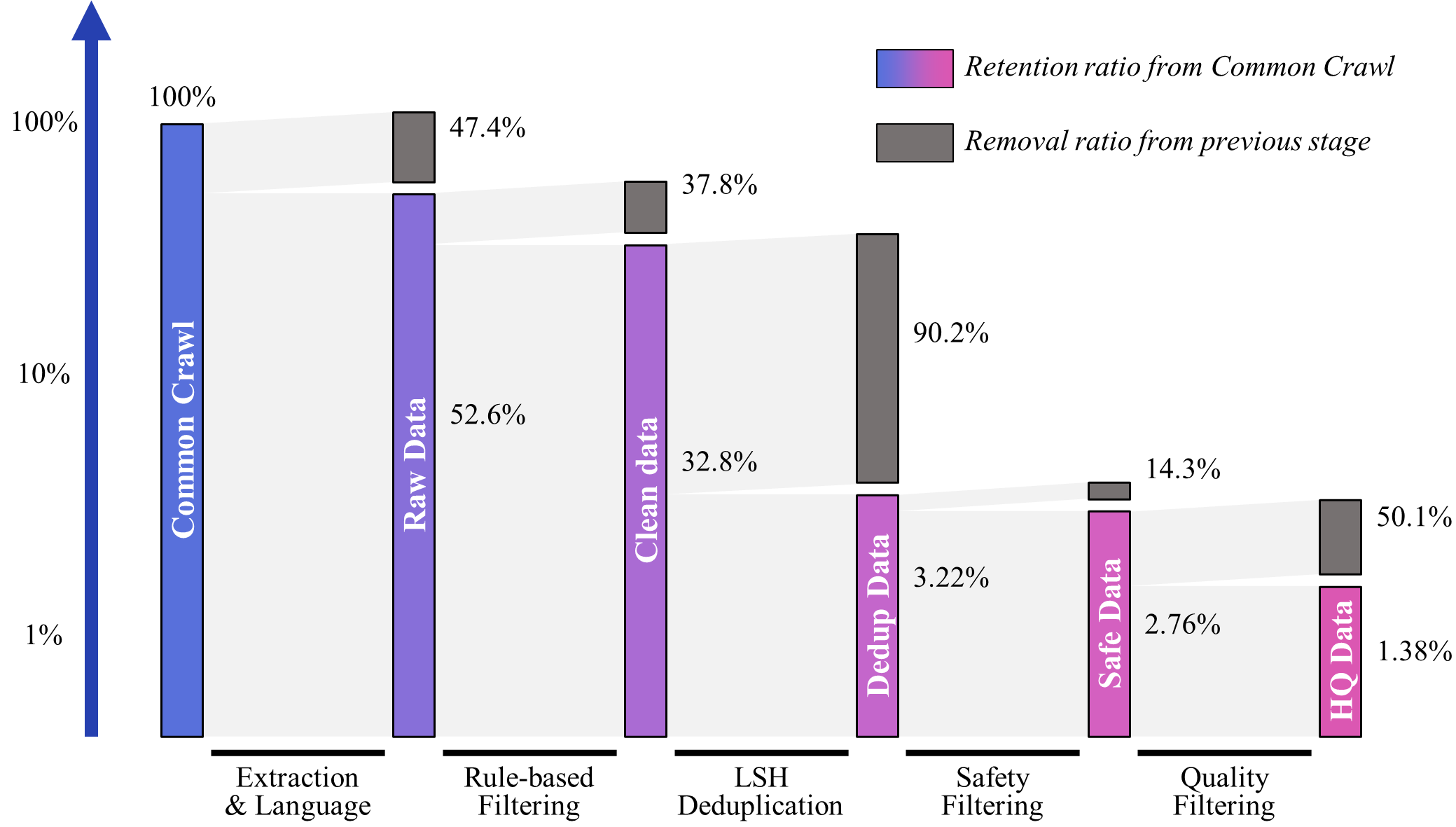
各步骤数据留存率
预训练InternEvo
简介
InternEvo是一个开源的轻量级训练框架,旨在支持无需大量依赖关系的模型预训练。凭借单一代码库,InternEvo支持在具有上千GPU的大规模集群上进行预训练,并在单个GPU上进行微调,同时可实现显著的性能优化。当在1024个GPU上进行训练时,InternEvo可实现近90%的加速效率。
基于InternEvo训练框架,我们累计发布了一系列大语言模型,包括InternLM-7B系列和InternLM-20B系列,这些模型在性能上显著超越了许多知名的开源LLMs,如LLaMA和其他模型。
摘自InternEvo/README-zh-Hans.md at develop · InternLM/InternEvo · GitHub
框架性能
InternEvo深度集成了Flash-Attention、Apex等高性能计算库,以提高训练效率。通过构建Hybrid Zero技术,InternEvo可在训练过程中实现计算和通信的有效重叠,显著降低跨节点通信流量。InternEvo支持将7B模型从8个GPU扩展到1024个GPU,在千卡规模下可实现高达90%的加速效率,超过180 TFLOPS的训练吞吐量,平均每个GPU每秒可处理超过3600个tokens。下表展示了InternEvo在不同配置下的可扩展性测试数据:
GPU Number 8 16 32 64 128 256 512 1024 TGS 4078 3939 3919 3944 3928 3920 3835 3625 TFLOPS 193 191 188 188 187 185 186 184 TGS表示每张GPU每秒可处理的平均Tokens数量。更多模型性能测试数据细节请查看 Training Performance document
摘自InternEvo/README-zh-Hans.md at develop · InternLM/InternEvo · GitHub
微调:Xtuner
XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。
高效
-
支持大语言模型 LLM、多模态图文模型 VLM 的预训练及轻量级微调。XTuner 支持在 8GB 显存下微调 7B 模型,同时也支持多节点跨设备微调更大尺度模型(70B+)。
-
自动分发高性能算子(如 FlashAttention、Triton kernels 等)以加速训练吞吐。
-
兼容 DeepSpeed 🚀,轻松应用各种 ZeRO 训练优化策略。
灵活
-
支持多种大语言模型,包括但不限于 InternLM、Mixtral-8x7B、Llama 2、ChatGLM、Qwen、Baichuan。
-
支持多模态图文模型 LLaVA 的预训练与微调。利用 XTuner 训得模型 LLaVA-InternLM2-20B 表现优异。
-
精心设计的数据管道,兼容任意数据格式,开源数据或自定义数据皆可快速上手。
全能
-
支持增量预训练、指令微调与 Agent 微调。
-
预定义众多开源对话模版,支持与开源或训练所得模型进行对话。
-
训练所得模型可无缝接入部署工具库 LMDeploy、大规模评测工具库 OpenCompass 及 VLMEvalKit。
速度测试(Speed Benchmark)
-
XTuner 与 LLaMA-Factory 在 Llama2-7B 模型上的训练效率对比

-
XTuner 与 LLaMA-Factory 在 Llama2-70B 模型上的训练效率对比
-

具体:xtuner/README_zh-CN.md at main · InternLM/xtuner · GitHub
评测:OpenCompass
OpenCompass 是面向大模型评测的一站式平台。其主要特点如下:
-
开源可复现:提供公平、公开、可复现的大模型评测方案
-
全面的能力维度:五大维度设计,提供 70+ 个数据集约 40 万题的的模型评测方案,全面评估模型能力
-
丰富的模型支持:已支持 20+ HuggingFace 及 API 模型
-
分布式高效评测:一行命令实现任务分割和分布式评测,数小时即可完成千亿模型全量评测
-
多样化评测范式:支持零样本、小样本及思维链评测,结合标准型或对话型提示词模板,轻松激发各种模型最大性能
-
灵活化拓展:想增加新模型或数据集?想要自定义更高级的任务分割策略,甚至接入新的集群管理系统?OpenCompass 的一切均可轻松扩展!

详细:opencompass/README_zh-CN.md at main · open-compass/opencompass · GitHub
官网:https://internlm.intern-ai.org.cn
如今,国内的模型普遍较少,但是上海人工智能实验室开源的浦语灵笔,为国内的开源贡献了一份力量!
















 1025
1025

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











