






CRITIC算法将数据稳定性作为一种数据,选定的指标也是有一定的联系的。
CRITIC权重确定算法是一种基于数据波动性(对比强度)和相关性(冲突性)的客观赋权法,因为数据波动性和相关性都是数据的信息,可以拿来计算权重。
对比强度其实跟数据的离散程度相似,跟集中情况相似,可以使用标准差表示,标准差越大说明波动越强(因为它所能提供的信息量也就越大,应该给该指标分配更多的权重),权重越大;
而冲突性便是使用相关系数表示,相关系数越大,说明关系越紧密(说明它所提供的信息与其他指标的信息有较大的相似性,存在信息上的重叠,因此应该减少对该指标分配的权重),冲突性越小,权重越小。
一、实现步骤
数据为n个长度为m的指标:
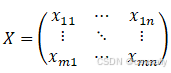
1.1 标准化(Min-Max Scaling)
数据标准化,也称为归一化,是将不同的数据按照一定的规则进行转换,使其具有相同的标准和范围,便于数据的比较和分析。
正向指标是指其数值越大,表示情况越好或越符合某种期望的指标。通常用于衡量积极的结果或性能。
逆向指标是指其数值越小,表示情况越好或越符合某种期望的指标。用于衡量需要减少或避免的结果或性能。
1.1.1 正向指标
max和min是当前列中的最大最小值。下面同是。
1.1.2 逆向指标
1.2 信息承载量(信息量)
信息量被用来确定各个指标的权重。权重的大小反映了指标在评价体系中的重要程度 。
1.2.1 对比强度(标准差)
具体公式都知道,便不给出,使用np.std可以算。
1.2.2 冲突性(相关系数)
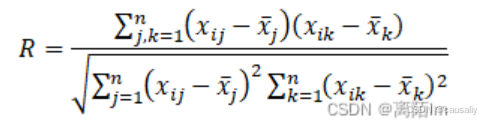
计算得到的是相关系数矩阵,下面是计算每个指标的冲突性
1.2.3 信息量
信息量=对比强度*冲突性
1.3 权重计算
每个指标的信息承载量除以信息承载量的总和,得到每个指标的客观权重。
二、代码案例
import pandas as pd
import numpy as np
#导入数据
data=pd.read_excel('问卷数据.xlsx')
#数据正向化标准化处理
label_need=data.keys()[0:9]
data1=data[label_need].values
data2=data1.copy()
[m,n]=data2.shape
index_all=np.arange(n)
index=[2]#负向指标位置,注意python是从0开始计数;对应位置也要相应减1
#负向指标位置
for j in index:
d_max=max(data1[:,j])
d_min=min(data1[:,j])
data2[:,j]=(d_max-data1[:,j])/(d_max-d_min)
#正向指标位置
index=np.delete(index_all,index)
for j in index:
d_max=max(data1[:,j])
d_min=min(data1[:,j])
data2[:,j]=(data1[:,j]-d_min)/(d_max-d_min)
#变异性
the=np.std(data2,axis=0)
print("指标变异性:",the)
data3=data2.copy()
#冲突性
data3=list(map(list,zip(*data2)))#矩阵转置 9*781
r=np.corrcoef(data3)#求相关系数 9*781
f=np.sum(1-r,axis=1) #9*1
print("指标冲突性:",f)
#信息承载量
c=the*f
print("信息量:",c)
w=c/sum(c)#计算权重
print("客观权重:",w)应用到的数据如下,包括九个指标,有781个数据。

最后得到变异性(对比强度),信息量以及权重。

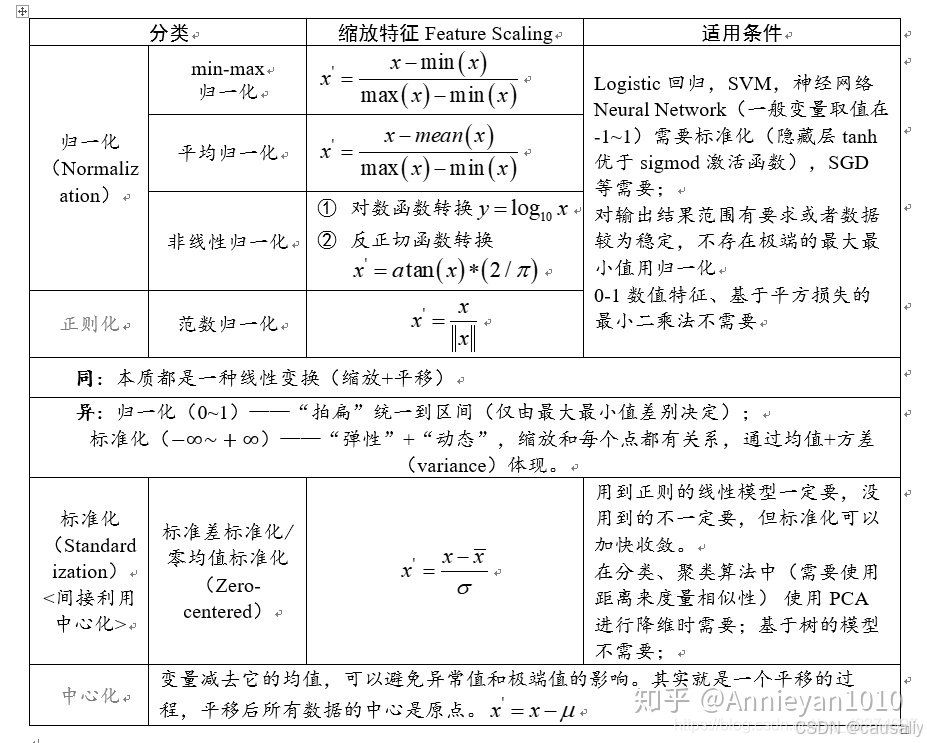
最后附一张从其它地方整过来的无量纲化处理总结,我自己偷摸看。

















 1503
1503

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









