






一,卡夫卡概述
分区概念:每个topic包含一个或多个分区,生产者和消费者通过节点进行数据发布和读取。
消费者组:每个消费者属于一个特定组,同一组内的消费者共同消费数据。
副本:分区副本数量不能高于节点数量,副本用于数据备份和故障恢复。
特性:
高吞吐量低延迟:每秒处理几十万条数据,延迟最低几毫秒。
可扩展性:支持水平扩展。
持久性和可靠性:消息持久化到本地磁盘,支持数据备份。
容错性:允许N-1个节点失败。
高并发性:支持数千个客户端读写。
卡夫卡安装步骤
前提条件:确保已安装JDK和Zookeeper。
下载安装包:根据Scala版本选择对应的Kafka版本。
上传和解压:将安装包上传到指定目录并解压。
配置修改:
修改server.properties文件中的broker.id、host.name、日志路径等。
配置Zookeeper集群端口号。
分发安装包:将配置好的安装包分发到其他节点。
启动集群:使用脚本一键启动Kafka集群,确保Zookeeper已启动。
Spark和Yarn环境安装
解压缩:解压Spark安装包并进行重命名。
配置文件修改:
修改spark-env.sh文件,添加Java home路径和其他变量。
修改slaves文件,添加工作节点。
分发配置:将修改后的配置文件分发到其他节点。
启动集群:启动HDFS和Yarn集群,提交测试应用验证安装。
数据生产与消费:
生产数据和消费数据的概念,类比为往篮子里放鸡蛋和从篮子里拿鸡蛋。
三、卡夫卡作为数据源的应用
创建方式:
三种创建方式:自定义方式、RDD 方式和使用卡夫卡数据源的方式。
卡夫卡数据源的优势,避免了内存溢出的问题。
Direct API 使用:
irect API 的工作原理及其优点,即计算节点主动消费数据,避免了接收数据和计算速度不匹配的问题。
提到 Direct API 是当前推荐的使用方式。
案例演示:通过一个具体案例展示了如何使用 Spark Streaming 从卡夫卡读取数据并进行简单计算。
DStream创建:
通过 SparkStreaming 从 Kafka 读取数据,并将读取过来的数据做简单计算,最终打印到控制台。
- 导入依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.12</artifactId>
<version>3.0.0</version>
</dependency>
2.编写代码
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.dstream.{DStream, InputDStream}
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
object DirectAPI {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("direct")
val ssc = new StreamingContext(sparkConf,Seconds(3))
//定义kafka相关参数
val kafkaPara :Map[String,Object] = Map[String,Object](ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG
->"node01:9092,node02:9092,node03:9092",
ConsumerConfig.GROUP_ID_CONFIG->"kafka",
"key.deserializer"->"org.apache.kafka.common.serialization.StringDeserializer",
"value.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer"
)
//通过读取kafka数据,创建DStream
val kafkaDStream:InputDStream[ConsumerRecord[String,String]] = KafkaUtils.createDirectStream[String,String](
ssc,LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String,String](Set("kafka"),kafkaPara)
)
//提取出数据中的value部分
val valueDStream :DStream[String] = kafkaDStream.map(record=>record.value())
//wordCount计算逻辑
valueDStream.flatMap(_.split(" "))
.map((_,1))
.reduceByKey(_+_)
.print()
ssc.start()
ssc.awaitTermination()
}
}
3.开启集群
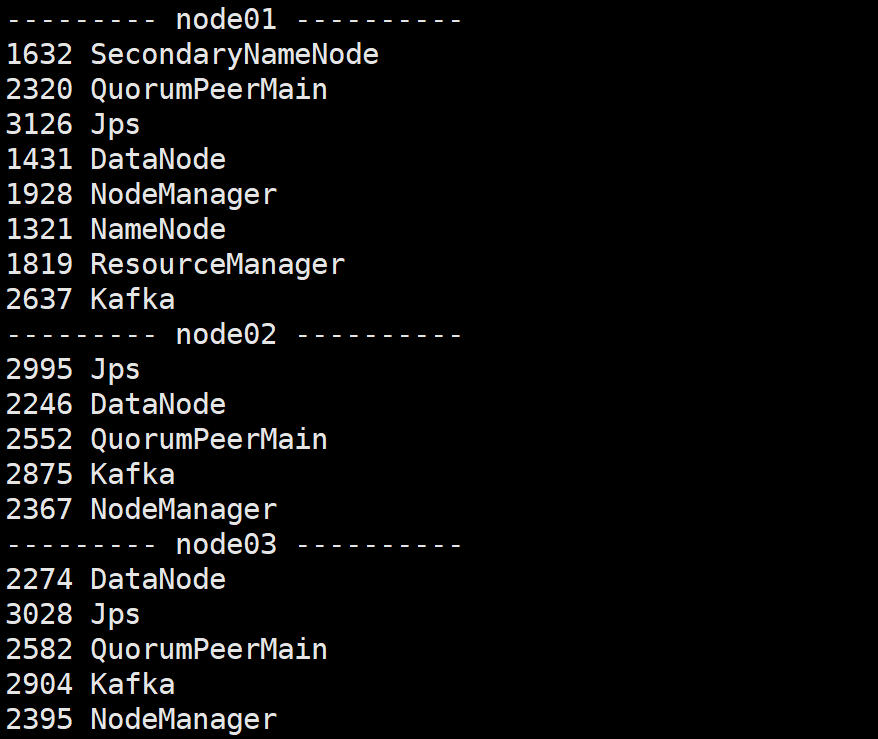
4,开启Kafka生产者,产生数据
kafka-console-producer.sh --broker-list node01:9092,node02:9092,node03:9092 --topic kafka
5.运行程序,接收Kafka生产的数据并进行相应处理


















 670
670

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









