






不带头节点的链表

结构定义
不带头节点的链表,也就是带头指针(pHead)的链表。第一个节点即为实际存储数据的节点。
优点
内存使用:少了头节点,可以节省一些数据空间。(但对于大多数应用场景来说,这点差异可以忽略不计)
带头节点的链表
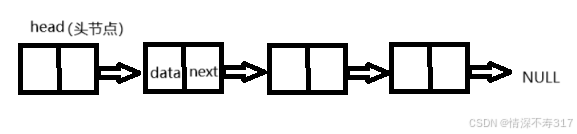
结构定义
带头节点的链表在头部有一个额外的头节点,该头节点不存储有效的数据,仅作为链表的起始节点。其next指向第一个存储有效数据的节点。
优点(含题目讲解)
操作便利性:带头节点的链表在进行插入和删除等操作时,由于头节点的存在可以简化对空链表的处理,避免了对链表是否为空的特殊判断。同时在链表头部进行插入和删除操作时也更加方便。而不带头节点的链表则需要在进行这些操作时进行额外的判断。
我们来通过1个题目来体验一下带头节点的链表的这个优点:
带头节点的处理方式:
我们先列举一组数据{1,7,5,4,2},X=5
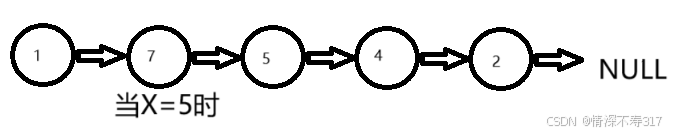
我们可以把数据小于X的节点取下来单独组成一个新链表(我们取名为less链表),再把数据大于或等于X的节点取下来有单独组成一个新链表(我们取名为great链表)。这两个新链表我们都用一个头节点指向他们第一个节点,分别为lessHead和greatHead。为了方便后插,我们用cur指针来遍历原链表的的每个节点(方便里面的每个节点力的数据与X进行比较),lessTail指针来标记less链表的尾节点,greatTail指针来标记great链表的尾节点。
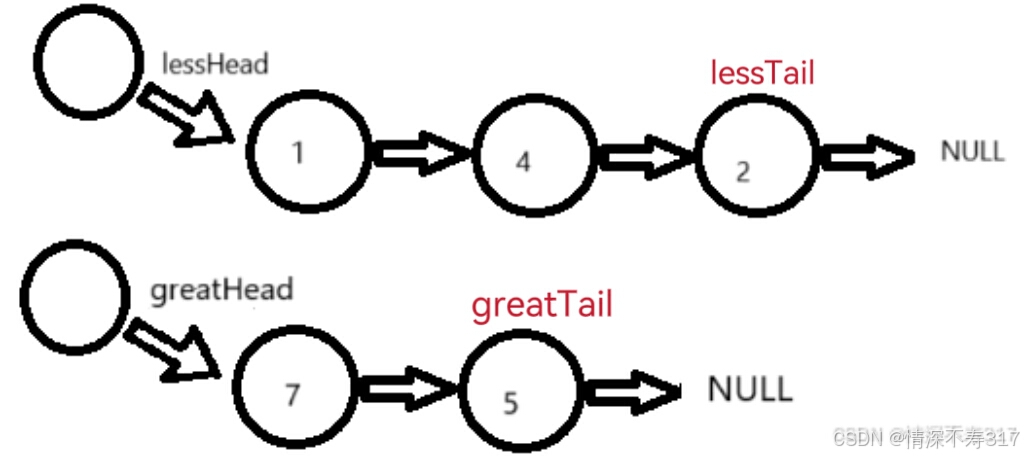
最后,我们再把less链表的尾节点的next指向great链表的第一个存放有效数据的节点(即头节点的next指向的第一个存储有效数据的节点,greatHead->next),也就是lessTail->next=greatHead->next;
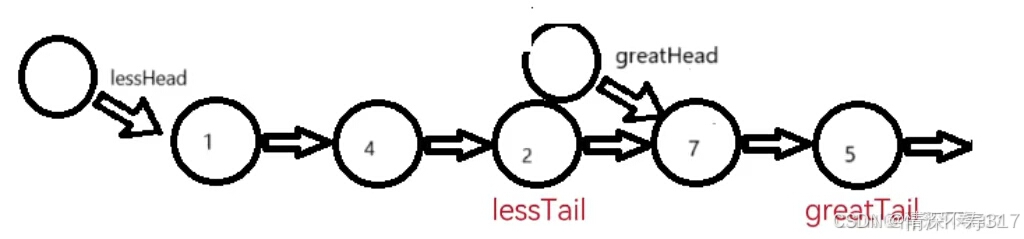
这里有一点要注意,greatTail链表的尾节点的next一定要指向NULL,否则最后容易陷入死循环。为什么呢?从原链表我们可以推断,great链表的尾节点greatTail的数据应该是5(我们就叫它为“5节点吧”)。但是greatTail节点在原链表的next指向后面的数据为4节点,如果greatTail->next最后不置NULL,会出现下面的情况:
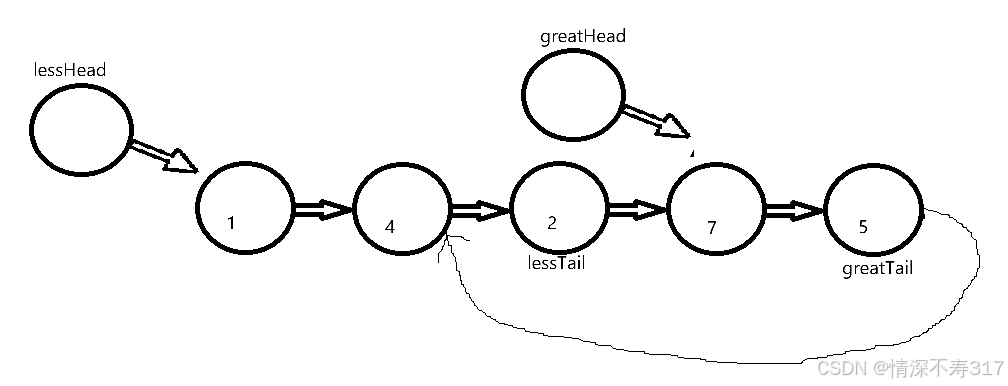
所以最后greatTail->next=NULL;这一个步骤不能忘记。
最后不要忘了释放掉less链表头节点和great链表头节点的空间。
具体代码如下:
class Partition {
public:
ListNode* partition(ListNode* pHead, int x) {
if(pHead==NULL)return NULL;
struct ListNode* greatHead=(struct ListNode*)malloc(sizeof(struct ListNode));
struct ListNode* lessHead=(struct ListNode*)malloc(sizeof(struct ListNode));
greatHead->next=NULL;
lessHead->next=NULL;
struct ListNode* greatTail=greatHead,*lessTail=lessHead,*cur=pHead;
while(cur){
struct ListNode* tmp=cur;
cur=cur->next;
if(tmp->val<x){
//小于X的节点尾插到头节点为lessHead的链表
lessTail->next=tmp;
lessTail=lessTail->next;
lessTail->next=NULL;
}else{
//大于X的节点尾插到头节点为lessHead的链表
greatTail->next=tmp;
greatTail=greatTail->next;
greatTail->next=NULL;//这一步不能忘,不然最终输出的链表很有可能会形成一个环
}
}
lessTail->next=greatHead->next;
struct ListNode* newHead=lessHead->next;
free(lessHead);
free(greatHead);
return newHead;
}
};带头指针的处理方式:

我们用pLessHead指针作为less链表的头指针,用pGreatHead指针作为great链表的头指针。其中有很多需要注意的点我将会在代码注释中标明。
class Partition {
public:
ListNode* partition(ListNode* pHead, int x) {
if(pHead==NULL)return NULL;
ListNode* pLessHead=NULL,*pGreatHead=NULL,*lessTail=NULL,*greatTail=NULL,*cur=pHead;
while(cur){
ListNode* tmp=cur;
cur=cur->next;
if(tmp->val<x){
if(pLessHead==NULL){
//需要判断less链表的头指针是否为空来进行第一个节点的插入
lessTail=pLessHead=tmp;
}else{
lessTail->next=tmp;
lessTail=lessTail->next;
}
lessTail->next=NULL;
}else{
if(pGreatHead==NULL){
//需要判断great链表的头指针是否为空来进行第一个节点的插入
greatTail=pGreatHead=tmp;
}else{
greatTail->next=tmp;
greatTail=greatTail->next;
}
greatTail->next=NULL;
}
}
if(pLessHead&&pGreatHead){
//如果原链表存在小于X和等于或大于X的节点,就将less链表的尾节点的next指向great链表的头节点
lessTail->next=pGreatHead;
return pLessHead;
}
if(pLessHead){
//如果不存在大于或等于X的节点,直接返回less链表的头指针
return pLessHead;
}
if(pGreatHead){
//如果不存在小于X的节点,直接返回great链表的头指针
return pGreatHead;
}
return NULL;//原链表为空的情况
}
};通过两个版本的代码,我们对比发现:不带头节点的代码写起来要麻烦很多,在插入第一个合适的节点以及最后拼接less链表和great链表的过程中,我们需要判断头指针是否指向空;而带头节点则无需考虑这些情况,只是最后要记得释放头节点的空间。

















 1684
1684

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









