






一、开篇引言
今天,就带大家一步步解锁如何爬取 B 站弹幕、将其可视化成词云图,以及精准预测弹幕情感倾向。
二、前期准备
-
软件安装
确保你的电脑上已经安装好了 Python 环境,推荐使用 Python 3.x 版本。此外,还需要安装几个关键的 Python 库,在命令行中分别输入以下指令进行安装:pip install requests:用于发送网络请求,抓取网页数据,这是我们获取 B 站弹幕的得力工具。pip install xml.etree.ElementTree:用来解析 XML 格式的数据,B 站的弹幕数据返回格式就是 XML,它能帮我们提取出弹幕文本。pip install jieba:一款强大的中文分词库,能把连续的中文句子按语义切成一个个单词,为后续生成词云图做准备。pip install wordcloud:专门用于生成酷炫的词云图,让我们直观地看出弹幕中的高频词汇。pip install snownlp:能够对中文文本进行情感分析,判断弹幕是积极、消极还是中性情感。pip install pandas:用于数据处理与分析,在情感分析阶段帮助我们整理和统计数据。pip install matplotlib:绘图神器,不仅能在情感分析时绘制柱状图展示不同情感弹幕的数量对比,还能在生成词云图时辅助显示。- 这里用清华镜像下载的更快pip install 包名 -i https://pypi.tuna.tsinghua.edu.cn/simple
-
获取视频 CID
打开你想要分析弹幕的 B 站视频页面打开你想要获取cid的 B 站视频页面。右键点击页面空白处,选择 “查看网页源代码”(不同浏览器可能表述略有不同,如 “检查”“审查元素” 等)。在打开的源代码窗口中,使用快捷键(如Ctrl + F或Command + F)调出搜索框,输入cid。通常可以找到类似"cid":1234567这样的内容,其中数字部分就是该视频对应的cid。把它记下来,后续代码中会用到。 
三、代码拆解与实战
1.爬取弹幕
import requests
import xml.etree.ElementTree as ET
import time
def get_bilibili_danmaku(cid):
url = f"https://comment.bilibili.com/{cid}.xml"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept - Language': 'zh - CN,zh;q = 0.9'
}
try:
response = requests.get(url, headers=headers)
# 手动指定编码为utf-8
response.encoding = 'utf-8'
response.raise_for_status()
root = ET.fromstring(response.text)
danmaku_list = []
for d in root.findall('d'):
danmaku = d.text
danmaku_list.append(danmaku)
with open('danmaku.txt', 'w', encoding='utf-8') as f:
for danmaku in danmaku_list:
f.write(danmaku + '\n')
print("弹幕保存成功!")
except requests.RequestException as e:
print(f"请求出错: {e}")
except ET.ParseError as e:
print(f"XML解析出错: {e}")
if __name__ == "__main__":
# 替换为你要爬取的视频的cid
cid = 28705030211
get_bilibili_danmaku(cid)
# 每次请求间隔3秒,避免请求过于频繁
time.sleep(3)这里通过构造请求,带上模拟浏览器的请求头,向 B 站弹幕接口发送请求,获取 XML 格式的弹幕数据,再解析并保存到本地的 danmaku.txt 文件中。记得把 cid 替换成你实际获取的视频 CID,不然无法抓取到正确的弹幕。
2.生成词云图
import jieba
from wordcloud import WordCloud
import matplotlib.pyplot as plt
def generate_wordcloud():
with open('danmaku.txt', 'r', encoding='utf-8') as f:
text = f.read()
words = jieba.lcut(text)
# 筛选出长度大于等于3的词
filtered_words = [word for word in words if len(word) >= 3]
new_text = " ".join(filtered_words)
wc = WordCloud(font_path='simhei.ttf', background_color='white').generate(new_text)
plt.imshow(wc, interpolation='bilinear')
plt.axis('off')
plt.show()
wc.to_file('wordcloud.png')
print("词云图保存成功!")
if __name__ == "__main__":
generate_wordcloud()
先读取 danmaku.txt 中的弹幕文本,用 jieba 分词后,筛选出至少 3 个字的词汇,重新组合成新文本,接着利用 WordCloud 库生成词云图,设置好中文字体(这里是黑体 simhei.ttf,确保你的系统有该字体,没有的话需下载安装),去除坐标轴显示,展示并保存词云图为 wordcloud.png。
结果展示:

3.情感分析
from snownlp import SnowNLP
import matplotlib.pyplot as plt
import pandas as pd
# 设置图片清晰度
plt.rcParams['figure.dpi'] = 300
# 解决中文显示问题
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
# 解决负号显示问题
plt.rcParams['axes.unicode_minus'] = False
def get_sentiment(text):
return SnowNLP(text).sentiments
try:
# 读取弹幕文件
with open('danmaku.txt', 'r', encoding='utf-8') as file:
danmakus = file.readlines()
# 创建 DataFrame
df = pd.DataFrame({'评论内容': danmakus})
# 进行情感分析
df['sentiment'] = df['评论内容'].apply(get_sentiment)
# 绘制情感分布直方图
plt.figure(figsize=(10, 8))
plt.hist(df['sentiment'], bins=20, color='#4B96E9', edgecolor='black')
plt.title('弹幕情感得分分布')
plt.xlabel('情感得分 (0:负面 ~ 1:正面)')
plt.ylabel('弹幕数量')
# 保存图片
plt.savefig('danmaku_sentiment_distribution.png')
print("弹幕情感分布直方图已保存为 danmaku_sentiment_distribution.png")
except FileNotFoundError:
print("未找到 danmaku.txt 文件,请先运行获取弹幕的代码。")
except Exception as e:
print(f"发生错误: {e}")
读取 danmaku.txt 里的弹幕,逐行用 SnowNLP 进行情感分析,得到每条弹幕的情感得分,存入列表。然后用 pandas 构建数据框,统计不同情感倾向的弹幕数量,保存结果到 sentiment_analysis.csv 文件
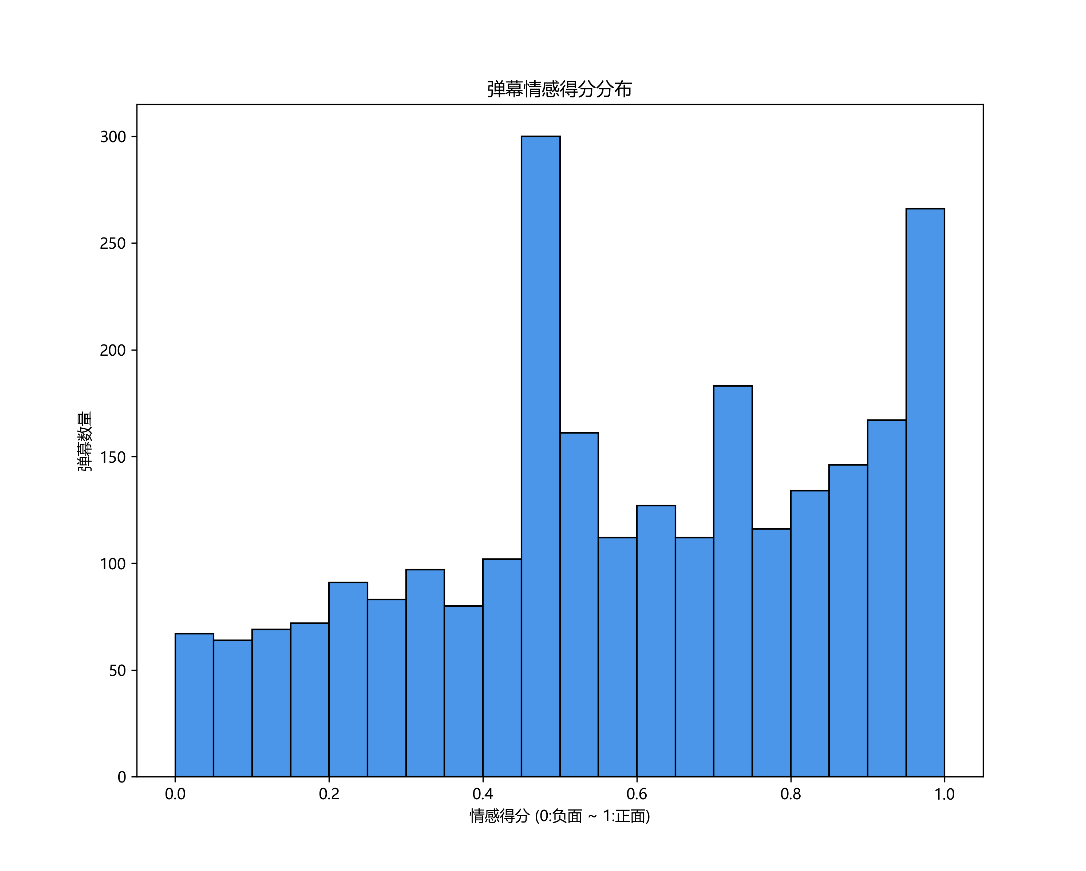
四、结果解读
- 词云图:词云图中字体越大的词汇,说明在弹幕中出现的频率越高,这些高频词往往反映了观众对视频核心关注点、人物、场景等的聚焦。比如,若视频是游戏攻略,“攻略”“技巧”“BOSS” 等大字体词汇,就暗示玩家们普遍关注的通关要点。
- 情感分析:通过柱状图中不同情感弹幕的数量对比,能精准把握观众整体对视频的喜好程度。若积极弹幕占比高,说明视频广受好评,创作者可以总结经验;消极弹幕多,则需仔细查看具体内容,反思视频存在的问题,如画质不佳、讲解不清等,以便后续改进。
五、总结拓展
至此,我们完整地走过了从 B 站弹幕爬取、可视化到情感分析的全过程。大家可以进一步拓展,尝试分析多个不同类型视频的弹幕,对比不同题材下观众的反应差异;还可以优化代码,比如增加弹幕清洗步骤,去除无意义的符号、空格等,让分析结果更加精准。希望大家都能利用好这些技能,在 B 站的大数据海洋中挖掘更多有价值的信息。
编辑
分享

















 229
229

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









