







针对数据库监控指标缺失(如QPS、连接数)的问题,结合大数据处理思路和实际场景,以下是系统性解决方案:
一、指标缺失的根因分析
-
数据采集链路异常
- 监控代理服务(如Prometheus Exporter)未启动或配置错误,导致无法采集
SHOW GLOBAL STATUS中的关键参数。 - 数据库账号权限不足,无法读取
information_schema或performance_schema中的性能表。
- 监控代理服务(如Prometheus Exporter)未启动或配置错误,导致无法采集
-
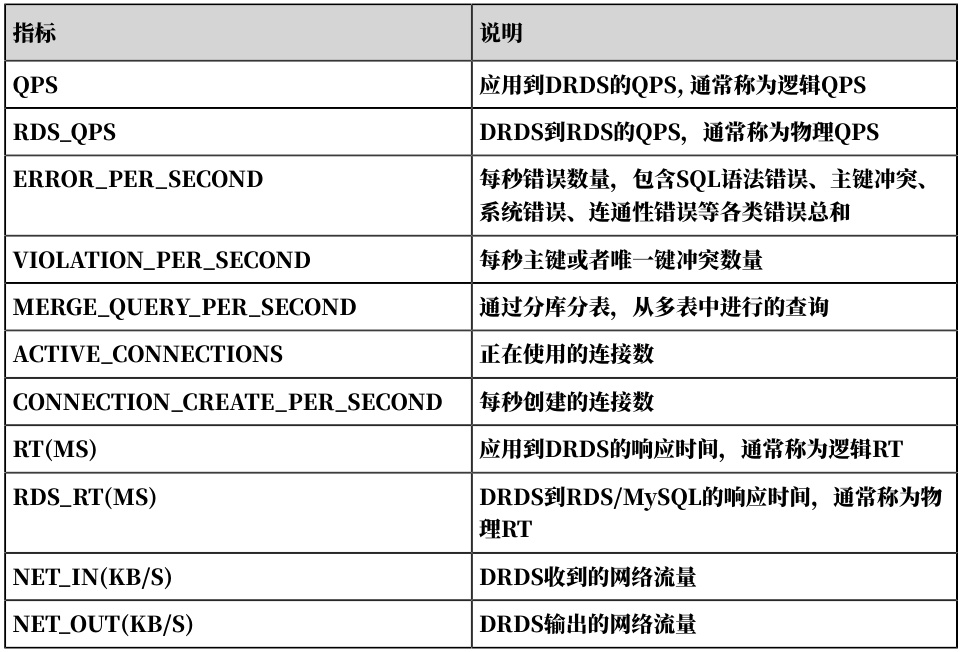
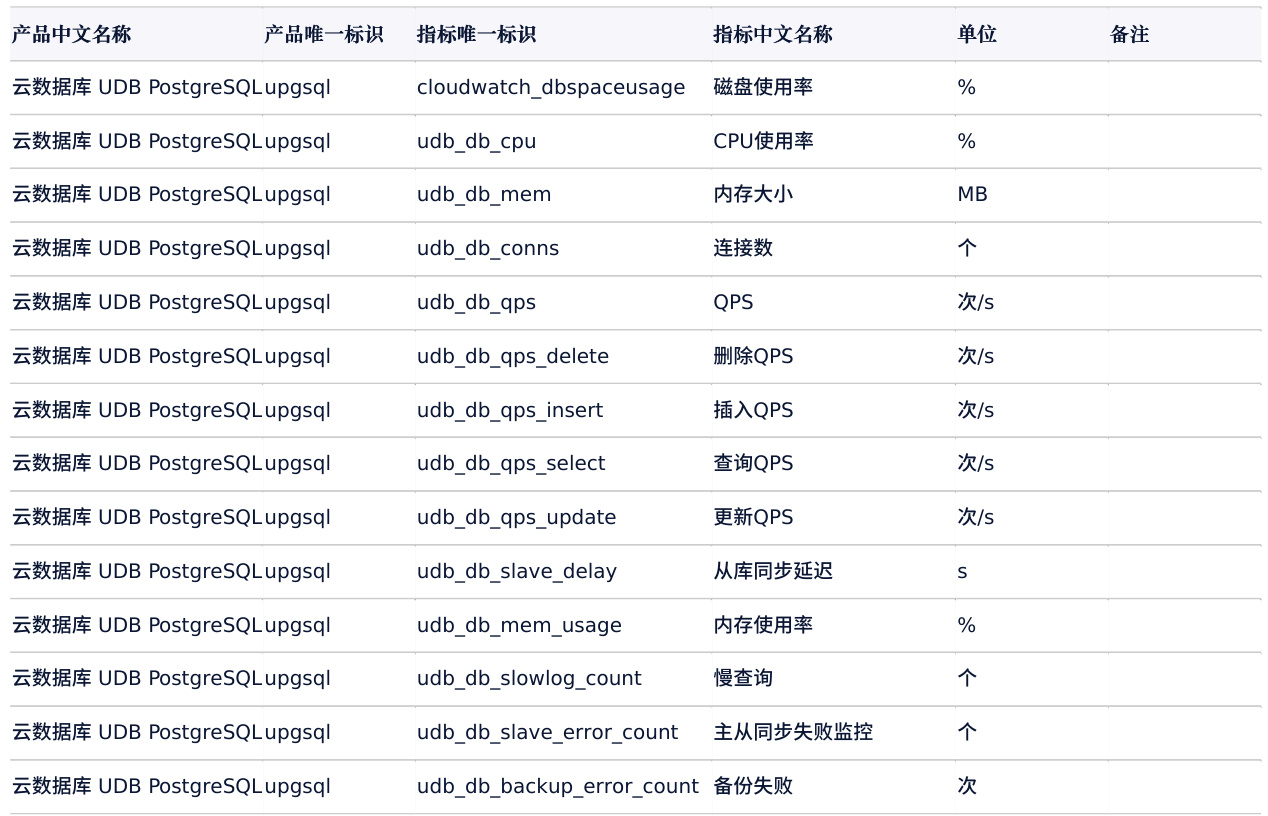
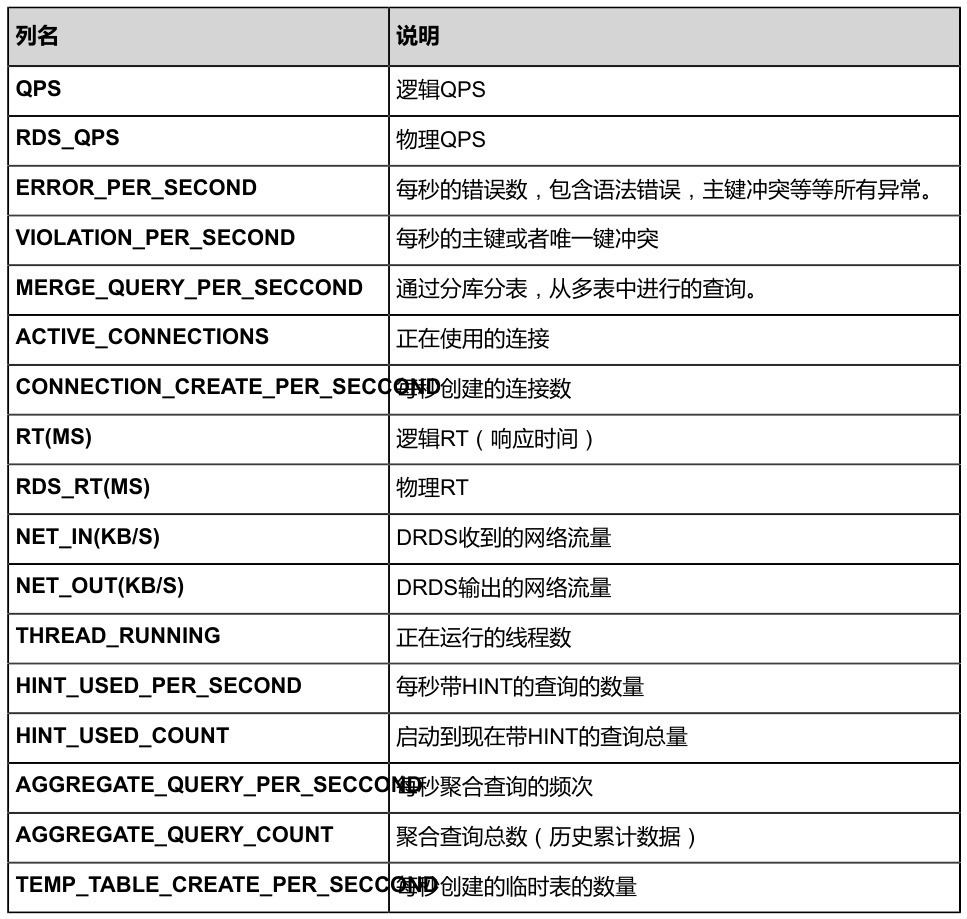
指标定义不匹配
- 不同数据库版本对监控项命名存在差异(如MySQL的
Questions与阿里云DRDS的QPS指标)。
- 分布式数据库(如PolarDB-X)需区分逻辑QPS与物理RDS_QPS,若未分层监控会导致数据断层。
- 不同数据库版本对监控项命名存在差异(如MySQL的
3. 资源限制触发阈值
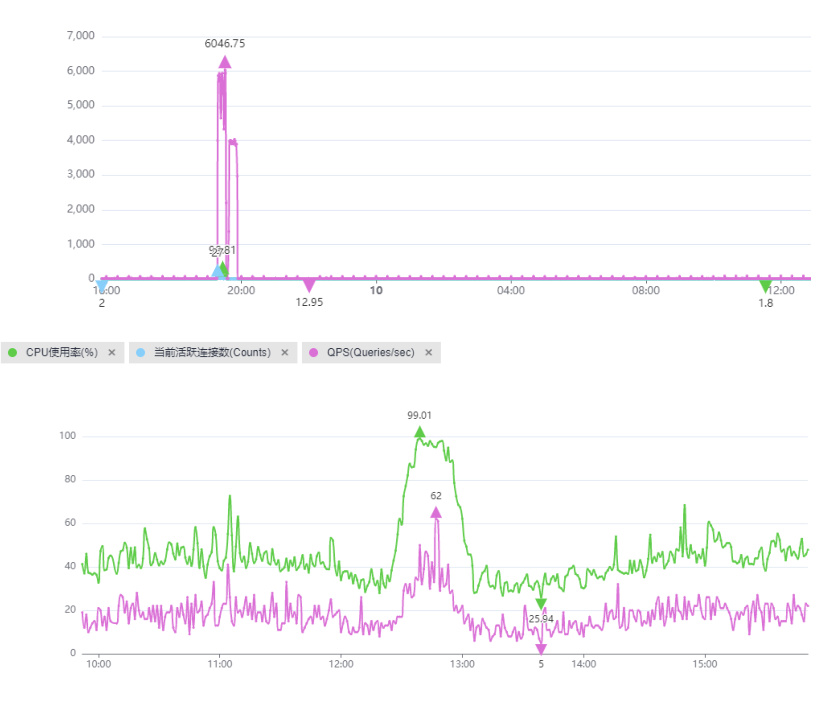
- 连接数超过
max_connections限制时,新增连接被拒绝,导致active_connections指标采集失败。 - 高QPS场景下,监控系统采样频率不足(如1分钟粒度),造成瞬时峰值丢失。
二、大数据处理方案
1. 指标补全与异常检测
# 基于时序数据预测缺失指标(使用Prophet模型)
from fbprophet import Prophet
import pandas as pd
# 假设df包含历史QPS数据(timestamp, qps)
model = Prophet(interval_width=0.95)
model.fit(df)
future = model.make_future_dataframe(periods=60, freq='S') # 补全未来60秒
forecast = model.predict(future)
# 结合实际采集数据,通过卡尔曼滤波修正预测值
2. 多源日志关联分析
# 解析慢查询日志与监控指标关联
import pyarrow.parquet as pq
slow_logs = pq.read_table('s3://logs/mysql-slow-2023.parquet').to_pandas()
monitor_data = spark.sql("SELECT * FROM hive.monitor_db.qps_table")
# 使用时间窗口关联QPS骤降与慢查询爆发
join_cond = [
F.abs(slow_logs['timestamp'] - monitor_data['timestamp']) <= '10 seconds',
slow_logs['instance_id'] == monitor_data['instance_id']
]
correlation_df = slow_logs.join(monitor_data, join_cond).groupBy('5m_window').agg(
F.count('slow_query_id').alias('slow_count'),
F.avg('qps').alias('avg_qps')
)
三、代码级监控实现
1. QPS实时计算(兼容多数据库)
# 使用多线程采集多实例QPS(以MySQL为例)
import mysql.connector
from prometheus_client import Gauge
qps_gauge = Gauge('mysql_qps' 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 754
754

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











