



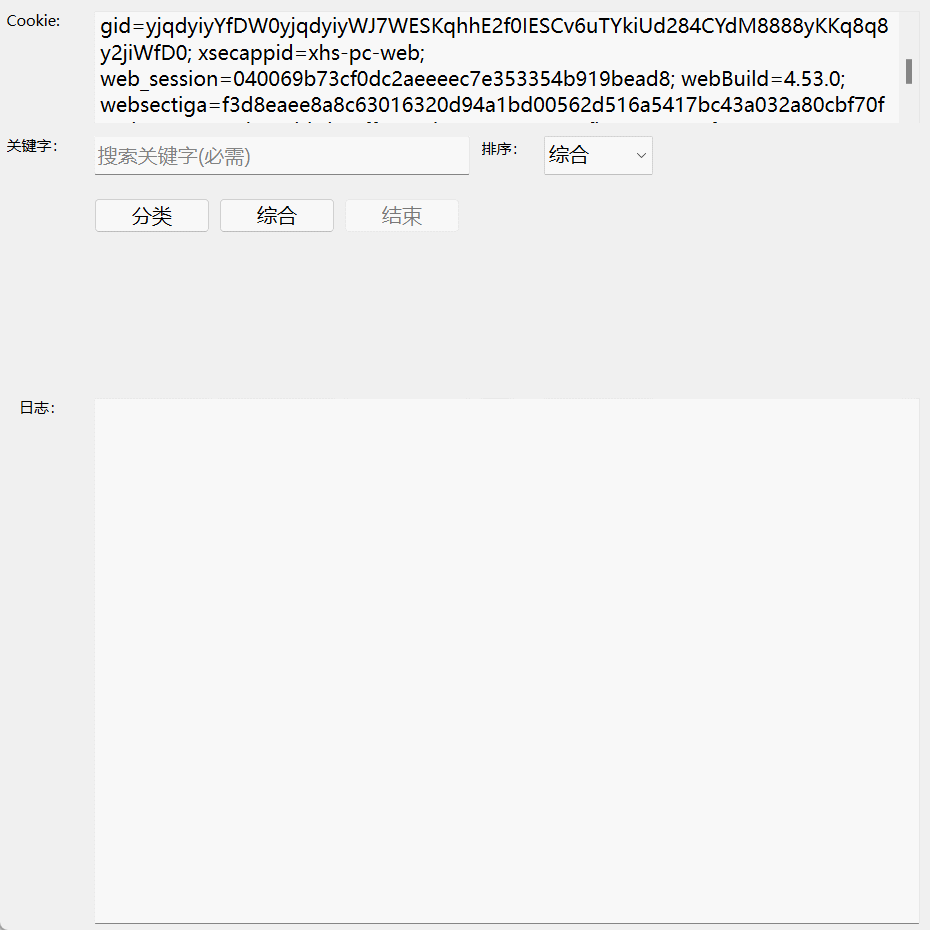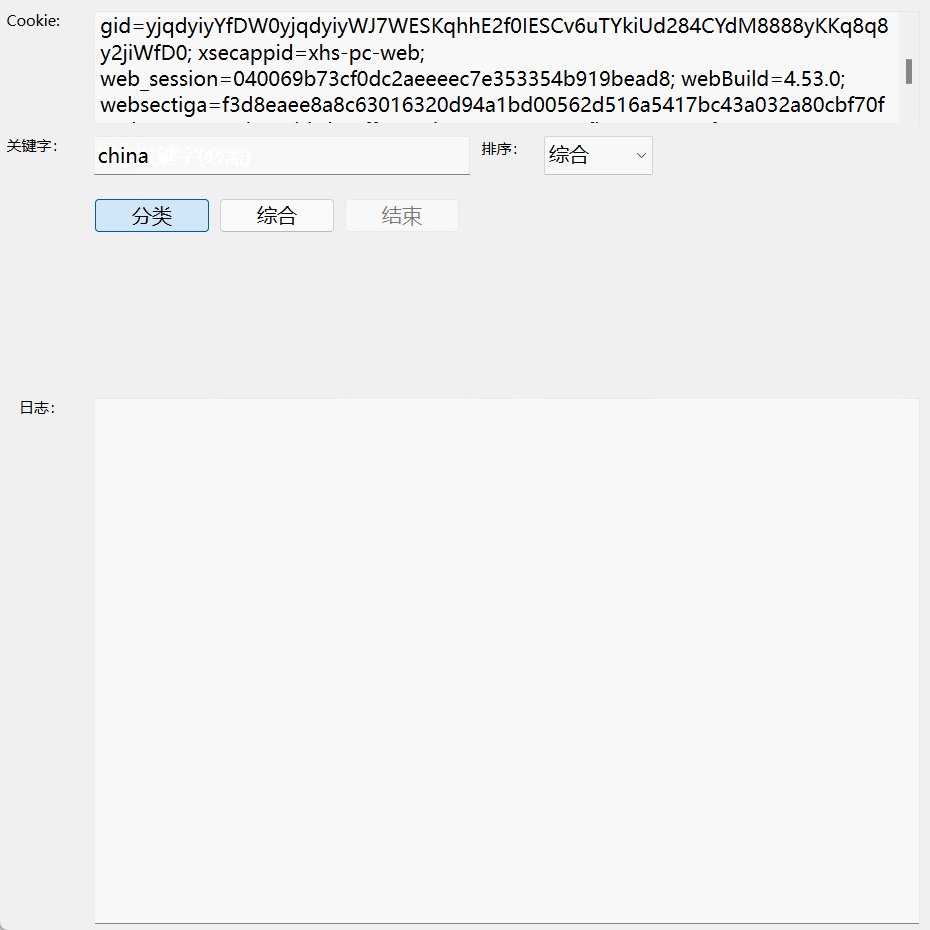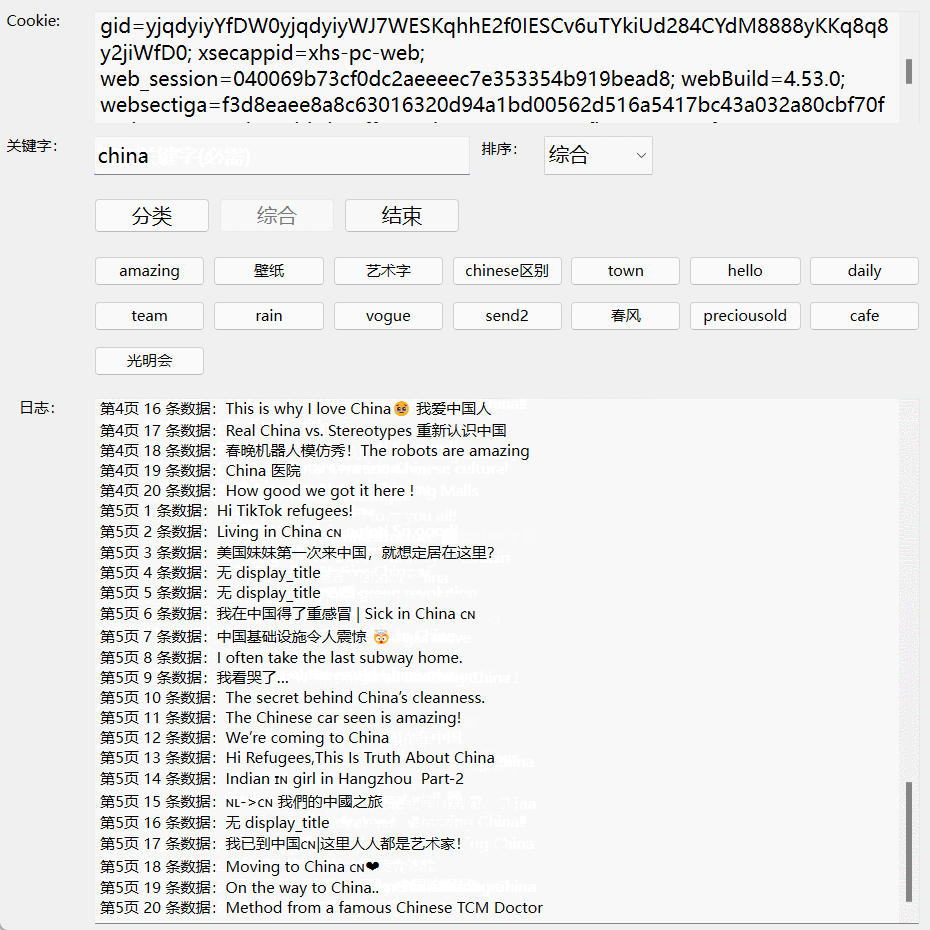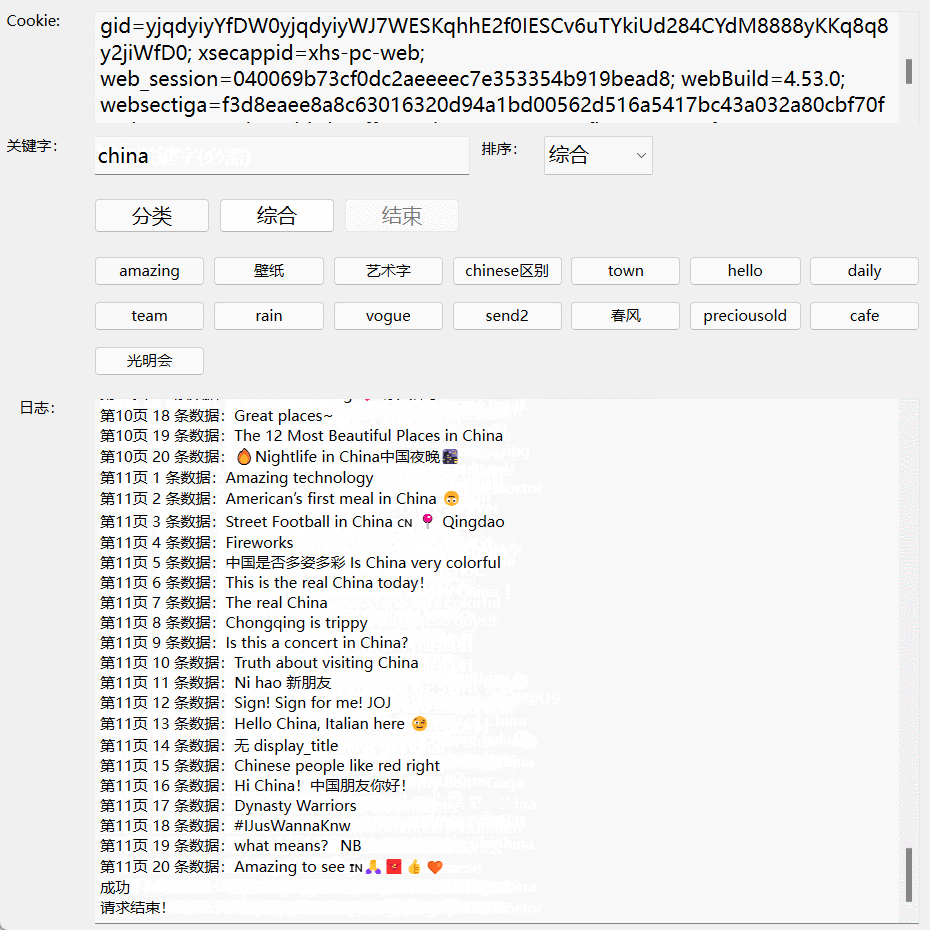
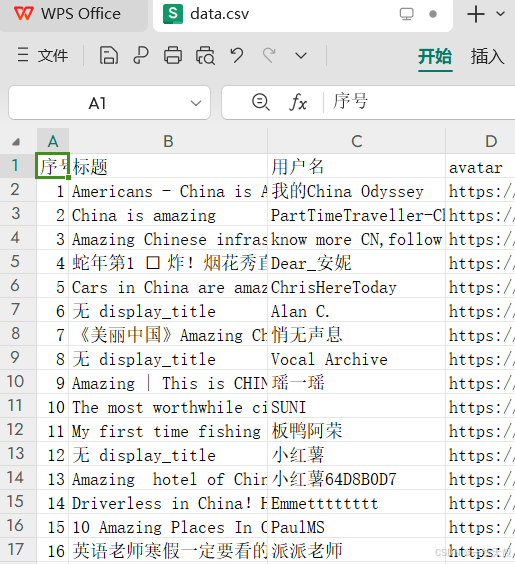
最近写了一个小红书笔记的自动收集 app, 效果如下图所示。app 运行环境:windows。需要填写登录小红书账号后的 cookie. 每请求完一条记录后都即时保存在 data.csv 文件中。
有需求的微1025466638,可以定制。
最近写了一个小红书笔记的自动收集 app, 效果如下图所示。app 运行环境:windows。需要填写登录小红书账号后的 cookie. 每请求完一条记录后都即时保存在 data.csv 文件中。
有需求的微1025466638,可以定制。
 1887
1650
356
292
1887
1650
356
292

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























