







基于Python数据分析与可视化预测项目实例分享
包含源码、实战案例和数据集,支持直接在Jupyter Notebook中打开,让您即刻开始数据分析和可视化的实战演练。
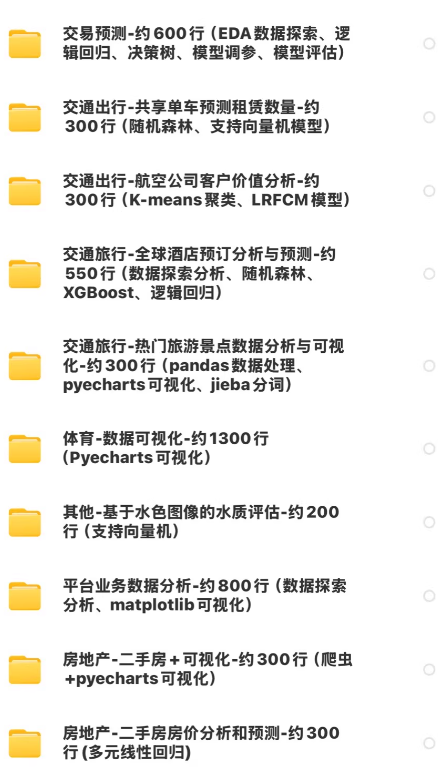
50个Pyecharts可视化实例: 从基础到高级,涵盖50个Pyecharts可视化实例,包括职场数据分析师职位分析、员工离职原因分析、微博情感分析等,每个案例均包含约300行代码,助您深入理解数据探索和分析
29个深度分析案例: 精选29个深度分析案例,覆盖电影票房、奥运会数据、时令蔬菜时间序列、人口普查数据等多个领域,每个案例均包含详细的代码实现和分析报告,让您全面掌握数据分析的各个方面。
可视化大屏项目: 包括国产进口电影票房榜单分析、春节档票房分析等大屏可视化项目,使用Pyecharts技术,让您的数据分析结果更加直观、震撼。
高级分析技术: 涵盖支持向量机、随机森林、XGBoost、逻辑回归等多种高级分析技术,让您在数据分析领域更加游刃有余。
文章目录
以下为示例代码,仅供参考!
下面是一个基于Python的数据分析与可视化预测项目的完整示例,包含代码和说明。该项目适用于时间序列数据(例如:股票价格、销售额、气温等),使用 Pandas 处理数据、Matplotlib 和 Seaborn 可视化分析结果,并用 Scikit-learn 或 statsmodels 进行简单预测。
🧠 项目目标
对某公司某产品月度销量进行数据分析与未来销量预测。
✅ 使用技术栈
| 技术 | 工具 |
|---|---|
| 数据处理 | pandas, numpy |
| 数据可视化 | matplotlib, seaborn |
| 预测模型 | scikit-learn (线性回归) / statsmodels (ARIMA) |
| 环境 | Python 3.x, Jupyter Notebook / VS Code |
💾 示例数据格式(CSV)
Month,Sales
2020-01,250
2020-02,260
2020-03,275
2020-04,280
...
你可以自己创建该CSV文件,或从Kaggle、UCI等平台获取类似的时间序列数据。
—
📦 步骤一:导入库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
from statsmodels.tsa.arima.model import ARIMA
📊 步骤二:加载与预处理数据
# 加载数据
df = pd.read_csv("sales_data.csv")
# 转换日期格式
df['Month'] = pd.to_datetime(df['Month'])
df.set_index('Month', inplace=True)
# 查看前几条数据
print(df.head())
# 检查缺失值
print(df.isnull().sum())
📈 步骤三:数据可视化分析
# 设置画布大小
plt.figure(figsize=(12,6))
# 绘制折线图
sns.lineplot(data=df, x=df.index, y='Sales')
plt.title("Monthly Sales Trend")
plt.xlabel("Month")
plt.ylabel("Sales")
plt.grid(True)
plt.show()
🔍 步骤四:特征工程(用于机器学习方法)
将“月份”转换为数字形式,作为训练特征:
df.reset_index(inplace=True)
df['Month_num'] = np.arange(len(df))
X = df[['Month_num']]
y = df['Sales']
🤖 方法一:使用线性回归建模预测
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, shuffle=False)
# 创建模型
model = LinearRegression()
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
# 计算误差
mse = mean_squared_error(y_test, y_pred)
print("MSE:", mse)
# 绘图展示预测结果
plt.figure(figsize=(10,5))
plt.plot(df['Month'], df['Sales'], label="Actual Sales", color="blue")
plt.plot(df.loc[X_test.index, 'Month'], y_pred, label="Predicted Sales", color="red", linestyle="--")
plt.legend()
plt.title("Linear Regression Prediction")
plt.show()
🕰️ 方法二:使用ARIMA做时间序列预测(推荐用于时序)
# 使用ARIMA模型
model = ARIMA(df['Sales'], order=(2,1,2)) # p,d,q 参数可根据AIC优化
results = model.fit()
# 预测未来12个月
forecast = results.forecast(steps=12)
# 可视化历史+预测
plt.figure(figsize=(10,5))
plt.plot(df['Sales'], label="Historical")
plt.plot(forecast, label="Forecast", color="green")
plt.title("ARIMA Forecasting")
plt.legend()
plt.show()
🚀 总结与扩展建议
✅ 当前功能已完成:
- 数据加载与清洗
- 时间序列趋势可视化
- 线性回归预测
- ARIMA时间序列预测
🔁 可扩展方向:
- 加入更多特征(如广告投入、季节因素)
- 使用LSTM神经网络进行预测
- 构建Web界面(Flask/Django + ECharts前端图表)
- 自动化预测系统 + 定期更新
📎 附录:依赖安装命令
pip install pandas numpy matplotlib seaborn scikit-learn statsmodels
如果你使用Jupyter Notebook,可以一行一行运行上述代码,实时查看结果。
📌 最终成果展示(可做PPT/报告内容):
- 销量趋势图
- 实际 vs 预测对比图
- 预测误差指标(RMSE/MSE)
- 模型选择与评估结论

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









