







基于python的大学毕业生就业分析预测 含报告
文章目录
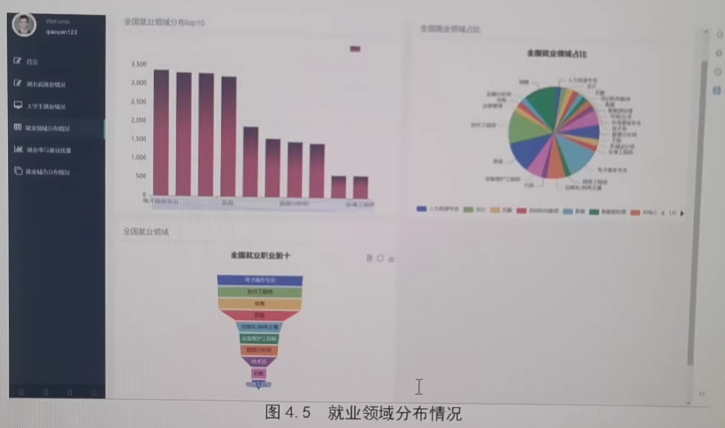
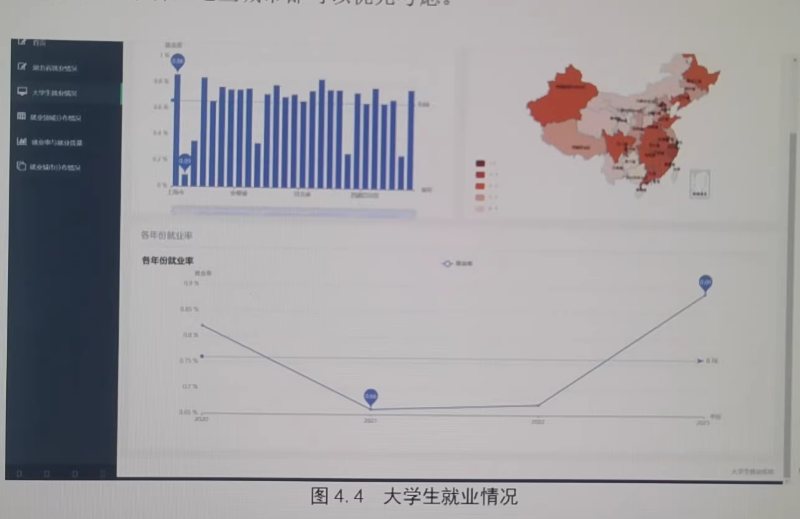
基于Python的大学毕业生就业分析预测
一、项目概述
本项目旨在利用Python进行数据分析和机器学习,对大学毕业生的就业情况进行分析并预测。通过收集相关数据集(如学历、专业、成绩、实习经历等),使用统计分析方法理解影响就业的关键因素,并构建预测模型来预测毕业生的就业情况。
二、开发环境
- Python 3.8
- Pandas:用于数据处理
- NumPy:用于数值计算
- Matplotlib/Seaborn:用于数据可视化
- Scikit-learn:用于机器学习模型构建
三、数据集说明
假设我们有一个数据集graduates.csv,包含以下字段:
ID: 毕业生编号Gender: 性别Major: 专业GPA: 学分绩点Internships: 实习次数Employed: 就业状态(1表示已就业,0表示未就业)
四、代码实现
1. 数据预处理
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder, StandardScaler
# 加载数据集
data = pd.read_csv('graduates.csv')
# 查看数据集基本信息
print(data.info())
print(data.describe())
# 处理缺失值(这里简单地删除)
data.dropna(inplace=True)
# 特征编码(将非数值特征转换为数值特征)
labelencoder = LabelEncoder()
data['Gender'] = labelencoder.fit_transform(data['Gender'])
data['Major'] = labelencoder.fit_transform(data['Major'])
# 分离特征和目标变量
X = data[['Gender', 'Major', 'GPA', 'Internships']]
y = data['Employed']
# 数据标准化
scaler = StandardScaler()
X = scaler.fit_transform(X)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
2. 数据探索性分析
import matplotlib.pyplot as plt
import seaborn as sns
# 绘制GPA与就业状态的关系图
plt.figure(figsize=(10,6))
sns.boxplot(x='Employed', y='GPA', data=data)
plt.title('GPA vs Employment Status')
plt.show()
# 绘制不同专业的就业率
employment_rate_by_major = data.groupby('Major')['Employed'].mean().sort_values(ascending=False)
employment_rate_by_major.plot(kind='bar', figsize=(10,6))
plt.title('Employment Rate by Major')
plt.xlabel('Major')
plt.ylabel('Employment Rate')
plt.show()
3. 构建预测模型
(1) 使用逻辑回归模型
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, classification_report
# 初始化逻辑回归模型
model = LogisticRegression()
# 训练模型
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
# 评估模型性能
print("Accuracy:", accuracy_score(y_test, y_pred))
print(classification_report(y_test, y_pred))
(2) 使用随机森林模型
from sklearn.ensemble import RandomForestClassifier
# 初始化随机森林模型
rf_model = RandomForestClassifier(n_estimators=100, random_state=42)
# 训练模型
rf_model.fit(X_train, y_train)
# 预测
y_pred_rf = rf_model.predict(X_test)
# 评估模型性能
print("Random Forest Accuracy:", accuracy_score(y_test, y_pred_rf))
print(classification_report(y_test, y_pred_rf))

五、结果与讨论
通过上述步骤,我们可以完成大学毕业生就业情况的数据分析和预测。以下是主要发现:
- GPA与就业状态:一般来说,GPA较高的学生更有可能找到工作。
- 专业差异:不同专业的就业率存在显著差异,某些热门专业的就业率明显高于其他专业。
- 实习经历的重要性:拥有更多实习经历的学生在就业市场上更具竞争力。
基于逻辑回归和随机森林两种模型的预测结果显示,随机森林模型在本案例中表现更好,准确率更高,能够更好地捕捉数据中的复杂模式。
六、结论
本项目展示了如何使用Python进行数据分析和机器学习,以理解和预测大学毕业生的就业情况。通过数据预处理、探索性分析以及模型构建,我们不仅能识别出影响毕业生就业的主要因素,还能基于这些信息构建有效的预测模型,帮助教育机构和个人做出更好的职业规划决策。未来的工作可以考虑增加更多的特征(如技能证书、社会活动等)以进一步提升模型的预测能力。
七、环境配置
主要技术: python+Vue+Mysql+Django
环境配置: Mysql8,python3.7.7
操作系统: Windows10/MacOs
架构模式: MVC
开发工具: pycharm
数据库版本: Mysql8
数据库可视化工具: Navicat


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









