






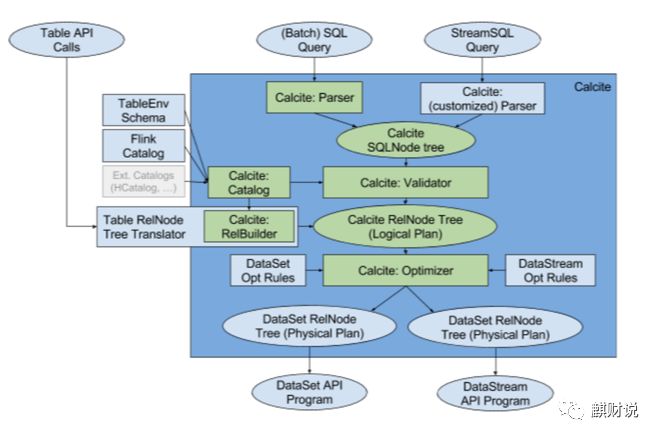
Flink SQL 是Fllink提供的SQL的SDK API。SQL是比Table更高阶的API,集成在Table library中提供,在流和批上都可以用此API开发业务。
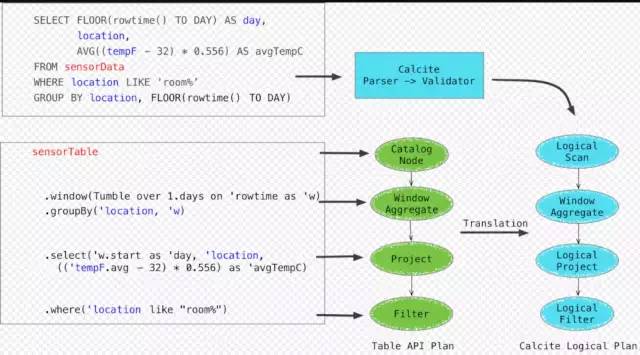
其完全依靠calcite(sql parser)去做语法解析,validate后生成calcite logical plan. 而Table API先自己生成table API的logical plan,再通过calcite relbuilder translation成calcite logical plan。
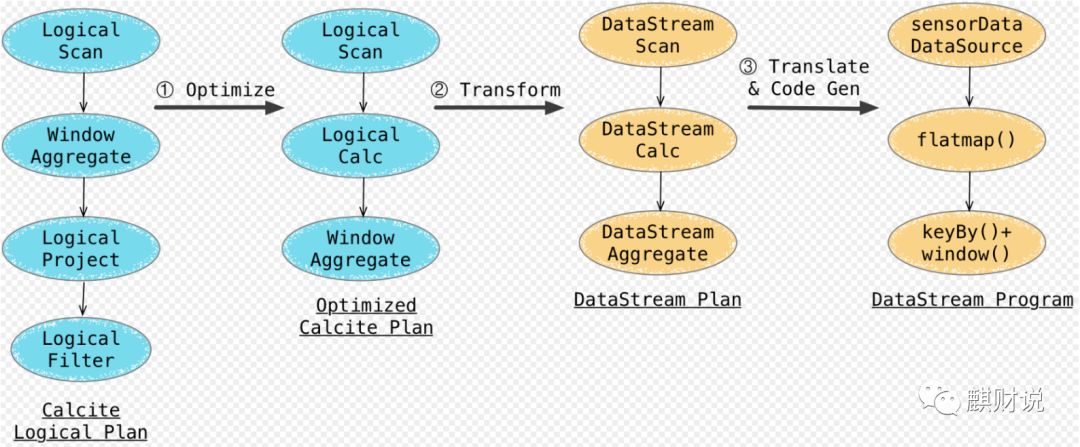
使用calcite cost-based optimizor 进行优化。也就是说和spark不同, flink 的SQL Parsing, Analysing, Optimizing都是托管给calcite(flink会加入一些optimze rules). Calcite 会基于优化规则来优化这些 Logical Plan,根据运行环境的不同会应用不同的优化规则(Flink提供了批的优化规则,和流的优化规则)。Calcite提供的内置优化规则(如条件下推,剪枝等),再基于flink定制的一些优化rules(根据是streaming还是batch选择rulue)去优化logical Plan。生成phsyical plan,基于flink里头的rules生成了DataStream Plan(Physical Plan)。
逻辑和spark类似,只不过calcite做了catalyst的事(sql parsing,analysis和optimizing)
代码案例
首先构建数据源,这里我用了’18-'19赛季意甲联赛的射手榜数据
rank,player,club,matches,red_card,total_score,total_score_home,total_score_visit,pass,shot
1,C-罗纳尔多,尤文图斯,26,0,19,5,7,111,61
2,夸利亚雷拉,桑普多利亚,26,0,19,5,5,76,42
3,萨帕塔,亚特兰大,26,0,16,1,4,53,31
4,米利克,那不勒斯,26,0,14,0,1,61,34
5,皮亚特克,热那亚,19,0,13,2,0,56,31
6,因莫比莱,拉齐奥,24,0,12,3,3,65,35
7,卡普托,恩波利,26,0,12,2,4,47,28
8,帕沃莱蒂,卡利亚里,23,0,10,0,1,44,22
9,佩塔尼亚,斯帕尔,25,0,10,2,0,44,29
10,热尔维尼奥,帕尔马,21,0,9,0,0,21,15
11,伊卡尔迪,国际米兰,23,0,9,3,2,44,23
数据列代表,排名、球员、所属俱乐部、比赛、红牌、总进球数、主场进球数、客场进球数、传球数、射门数
Spark SQL
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.SparkSession;
public class SparkSQLTest {
public static final String PATH = “E:\\devlop\\workspace\\streaming1\\src\\main\\resources\\testdata.csv”;
public static void main(String[] args) throws Exception {
SparkSession ss = SparkSession.builder().appName(“local”).master(“local”).getOrCreate();
ss.read().option(“header”, “true”).csv(PATH)
.registerTempTable(“topScore”);
Dataset ds = ss.sql(“select * from topScore”).toDF();
ds.collectAsList().forEach(it->System.out.println(it));
}
}
spark的程序非常简单,就可以实现对csv进行查询,
option(“header”, “true”)
设置了第一行作为列头,并将csv文件注册为表“topScore”。接下来直接通过SQL进行查询就好了。
输出结果:
[1,C-罗纳尔多,尤文图斯,26,0,19,5,7,111,61]
[2,夸利亚雷拉,桑普多利亚,26,0,19,5,5,76,42]
[3,萨帕塔,亚特兰大,26,0,16,1,4,53,31]
[4,米利克,那不勒斯,26,0,14,0,1,61,34]
[5,皮亚特克,热那亚,19,0,13,2,0,56,31]
[6,因莫比莱,拉齐奥,24,0,12,3,3,65,35]
[7,卡普托,恩波利,26,0,12,2,4,47,28]
[8,帕沃莱蒂,卡利亚里,23,0,10,0,1,44,22]
[9,佩塔尼亚,斯帕尔,25,0,10,2,0,44,29]
[10,热尔维尼奥,帕尔马,21,0,9,0,0,21,15]
[11,伊卡尔迪,国际米兰,23,0,9,3,2,44,23]
Flink SQL
import org.apache.flink.api.common.typeinfo.TypeHint;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.tuple.Tuple10;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.java.BatchTableEnvironment;
public class FlinkSQLTest {
public static final String PATH = “E:\\devlop\\workspace\\streaming1\\src\\main\\resources\\testdata.csv”;
public static void main(String[] args) throws Exception {
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
BatchTableEnvironment tableEnv = BatchTableEnvironment.getTableEnvironment(env);
DataSet<Tuple10<Integer,String,String,Integer,Integer,Integer,Integer,Integer,Integer,Integer>> csvInput = env.readCsvFile(PATH)
.ignoreFirstLine()
.types(Integer.class,String.class,String.class,Integer.class,Integer.class,Integer.class,Integer.class,Integer.class,Integer.class,Integer.class);
Table topScore = tableEnv.fromDataSet(csvInput);
tableEnv.registerTable(“topScore”,topScore);
Table t = tableEnv.sqlQuery(“select * from topScore”);
TypeInformation<Tuple10<Integer,String,String,Integer,Integer,Integer,Integer,Integer,Integer,Integer>> info = TypeInformation.of(new TypeHint<Tuple10<Integer,String,String,Integer,Integer,Integer,Integer,Integer,Integer,Integer>>(){});
DataSet<Tuple10<Integer,String,String,Integer,Integer,Integer,Integer,Integer,Integer,Integer>> dst10 = tableEnv.toDataSet(t,info);
dst10.collect().forEach(it->System.out.println(it));
}
}
出于常年做通用型BI产品的习惯,还是不太喜欢直接使用POJO,使用了元组,但是这样其实不是个好习惯,无形中增加了编程的复杂度。
DataSet<Tuple10<Integer,String,String,Integer,Integer,Integer,Integer,Integer,Integer,Integer>> csvInput = env.readCsvFile(PATH)
.ignoreFirstLine()
.types(Integer.class,String.class,String.class,Integer.class,Integer.class,Intege
TypeInformation<Tuple10<Integer,String,String,Integer,Integer,Integer,Integer,Integer,Integer,Integer>> info = TypeInformation.of(new TypeHint<Tuple10<Integer,String,String,Integer,Integer,Integer,Integer,Integer,Integer,Integer>>(){});
DataSet<Tuple10<Integer,String,String,Integer,Integer,Integer,Integer,Integer,Integer,Integer>> dst10 = table
输出结果:
(1,C-罗纳尔多,尤文图斯,26,0,19,5,7,111,61)
(2,夸利亚雷拉,桑普多利亚,26,0,19,5,5,76,42)
(3,萨帕塔,亚特兰大,26,0,16,1,4,53,31)
(4,米利克,那不勒斯,26,0,14,0,1,61,34)
(5,皮亚特克,热那亚,19,0,13,2,0,56,31)
(6,因莫比莱,拉齐奥,24,0,12,3,3,65,35)
(7,卡普托,恩波利,26,0,12,2,4,47,28)

















 610
610

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









