






大小球的预测一直是体育数据分析领域的核心课题。传统方法多依赖复杂的模拟技术或多元变量模型,但其资源消耗与不确定性常限制实用价值。本文提出一种基于最大化简约模型(Maximally Parsimonious Model)的预测框架,通过联赛早期数据的统计特性,构建高效且鲁棒的排名预测系统。我们将深入探讨以下关键问题:如何定义预测质量?早期联赛数据(如积分排名与净胜球)如何解释最终结果?以及为何简约模型能在资源效率与预测精度间取得平衡?
1.预测质量评估:平均绝对误差(MAE)的统计性质
1.1MAE的定义与计算
预测质量的量化需选取合适的评估指标。对于排名预测问题,平均绝对误差(Mean Absolute Error,MAE)因其直观性与稳健性成为首选。设真实排名为序列{1,2,......,n},预测排名为排列P=[P1,P2,......,Pn],则MAE定义为:
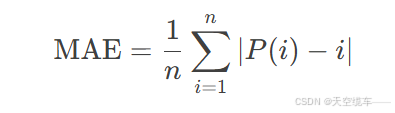
以2016/17赛季英超联赛为例,专家保罗·默森(Paul Merson)的预测MAE为2.8,即平均每个俱乐部的预测排名偏离真实位置2.8个名次。然而,单凭此值难以判断预测质量优劣,需结合MAE的统计极值与期望值进行对比。
1.2MAE的极值与期望值
在完全随机预测假设下,MAE的数学极值与期望值可通过组合数学推导得出:
最小值(MAEₘᵢₙ):当预测完全准确时,MAE=0。
最大值(MAEₘₐₓ):当预测排名与真实排名完全逆序时(即P=[n,n-1,......,1]),MAE达到理论最大值:
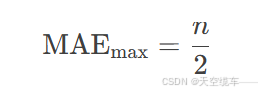
期望值(E[MAE]):在均匀随机排列假设下,MAE的期望值为:
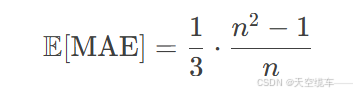
以英超(n=20)为例,随机预测的期望MAE为6.65,显著高于默森的预测值2.8,表明其预测具备统计学意义上的显著优势。
2.简约模型构建:早期数据的预测效力
2.1线性回归模型
为量化早期联赛数据对最终排名的解释能力,我们构建如下线性回归模型:
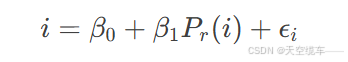
其中,Pr(i)为第r轮时俱乐部i的排名,β1为排名对最终位置的回归系数。通过计算不同轮次r的确定系数R2(r),可评估模型随赛季推进的预测能力变化。
2.2实证分析:挪威超级联赛案例
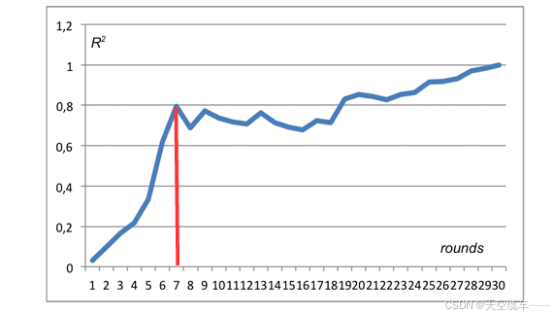
以2016年挪威顶级联赛(Tippeligaen)数据为例,绘制R2(r)曲线,发现:
早期高解释力:第7轮时R2已达0.8,表明联赛初期数据已蕴含80%的最终排名信息。
非线性增长:R2(r)呈现非严格单调上升,后期波动反映俱乐部状态调整与意外事件影响。
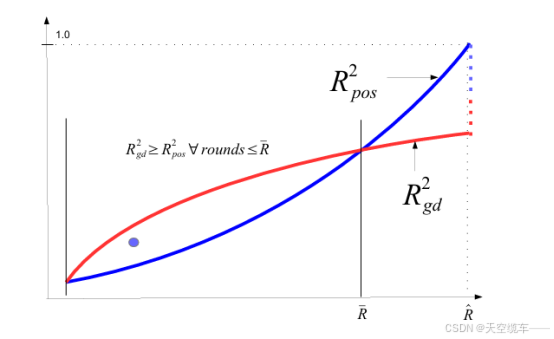
2.3净胜球指标的优化作用
进一步引入净胜球(Goal Difference,GD)作为预测变量,构建双变量回归模型:
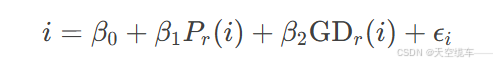
对比单一排名模型(Rpos2(r)Rpos2(r))与净胜球模型(Rgd2(r)Rgd2(r))发现:
早期阶段优势:前10轮内,净胜球模型的R2显著高于排名模型,反映其更早捕捉俱乐部真实实力。
收敛趋势:随着赛季推进,两模型R2逐渐趋同,表明后期排名稳定性增强。
3.数学推导:MAE的统计性质
3.1最大MAE的证明
考虑排列P的总偏差和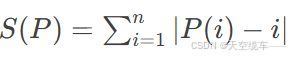 ,其最大化问题等价于:
,其最大化问题等价于:
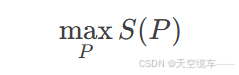
通过构造逆序排列P0=[n,n−1,…,1],可证明其满足极值条件。对于偶数联赛(n=2m),最大MAE为:

3.2期望MAE的推导
在均匀随机排列假设下,总偏差和的期望值计算为:

从而:
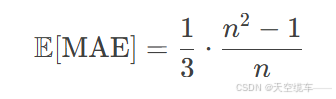
3.3方差与概率分布
MAE的方差计算为:
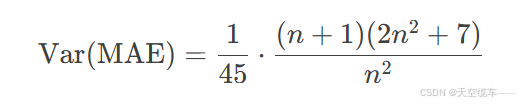
此外,达到最大MAE的概率为:
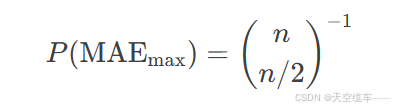
以英超为例,此概率约为5.4×10−65.4×10−6,远低于完全随机猜测的准确率(1/n!),凸显极端预测的罕见性。
4.实际应用与战略启示
4.1预测策略优化
早期阶段:优先采用净胜球指标,利用其高灵敏度捕捉俱乐部实力动态。
中后期阶段:切换至积分排名模型,降低噪声干扰并提升稳定性。
4.2资源效率对比
与传统仿真模型(需模拟每场比赛结果并迭代更新参数)相比,简约模型仅需历史排名或净胜球数据,计算复杂度由O(k⋅n2)降至O(n),适用于实时预测与大规模联赛分析。
4.3局限与改进方向
升降级影响:跨赛季预测需处理俱乐部更替问题,可通过加权历史数据或引入外部变量(如转会市场指数)缓解。
非线性效应:引入机器学习模型(如梯度提升树)捕捉排名与净胜球间的交互作用,进一步提升预测精度。
5.软件模型预测效果展示
预测成效
该预测模型依托于庞大的赛事数据,通过应用机器学习算法进行深度分析。经过精确的数据挖掘与算法处理,模型具备一定的赛事结果预测能力,其预测准确率约为80%。这一预测能力对赛事发展趋势的判断具有重要意义,为赛事分析提供了有价值的参考依据。
模型的80%准确率得益于多种先进技术的协同运作,诸如泊松分布和蒙特卡洛模拟等方法。这些技术从不同角度对赛事数据进行分析,有效提升了预测的准确性。该模型已被广泛应用于全球范围的赛事,通过筛选相关赛事并整理关键信息,为关注者提供数据支持,帮助优化体育赛事分析工作。
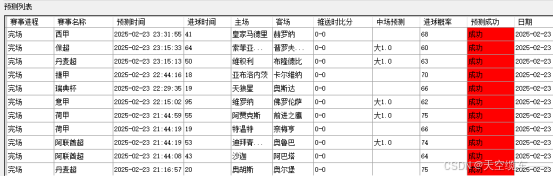
赛事监测成效
在赛事的进行过程中,监测模块发挥着关键作用。该模块利用先进的数据采集技术,实时捕捉比分和比赛进程等关键信息。这些数据一旦采集完成,便进入智能分析流程,通过高效的算法进行快速处理,最终转化为赛事分析和趋势预测结果。
随后,分析结果会即时推送给用户,帮助用户及时了解赛事动态,并基于科学分析对比赛走势进行合理预判。这一过程避免了盲目观赛,提升了用户对赛事的理解,同时优化了整体的观赛体验。
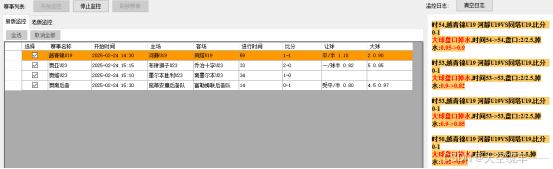
6.结论
本文通过统计推导与实证分析,验证了简约模型在大小球预测中的高效性与实用性。核心结论包括:
1.早期数据的高信息量:联赛前10轮数据可解释超过80%的最终排名变动。
2.指标选择策略:净胜球在早期阶段具备更优预测效力,而积分排名在中后期更具稳定性。
3.资源效率优势:简约模型在计算成本与预测精度间实现帕累托最优,为实时媒体分析与俱乐部战略规划提供可行工具。
未来研究可结合图神经网络(GNN)建模俱乐部间竞争关系,或集成外部经济变量(如转会支出与赞助收入),以构建更全面的预测生态系统。通过持续优化模型架构与数据源,大小球预测将不仅服务于娱乐需求,更能为俱乐部运营与联赛管理提供科学决策支持。

















 1109
1109

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









