






今天我给大家分享一个在学术和工业界都备受关注的顶会热门主题:时间序列 + 聚类。这一领域作为数据挖掘与模式识别的关键课题,在众多领域都有着不可或缺的作用。在工业界,从智能工厂的设备故障预测,到电商平台的库存管理,都迫切需要高效的时间序列聚类算法。
目前,顶尖学术会议上关于时间序列 + 聚类的论文成果,多围绕跨领域模型构建和实际场景适配展开。像在一些研究中,通过融合不同领域的知识,构建通用的时间序列聚类模型,以适应多样化的应用需求。例如,针对多模态时间序列数据(包含文本、图像、传感器数据等多种类型)设计专门的聚类算法;或是探索轻量化算法,提升计算效率,满足实时性要求高的场景。同时,结合扩散模型、生成对抗网络等最新技术,往往能带来意想不到的创新成果。
为了助力大家在这个领域深入探索,我精心整理了12篇时间序列 + 聚类的前沿论文,涵盖近期顶会顶刊成果。要是你在研究过程中缺乏思路,或是遇到其他问题,欢迎一起交流探讨!!
点击【AI十八式】的主页,获取更多优质资源!
【论文1】k-Graph: A Graph Embedding for Interpretable Time Series Clustering
![k-Graph resulting graph G when applied on the Trace
dataset [24]](https://i-blog.csdnimg.cn/direct/b6b46a37e8a24ec88b3554cba75b2355.png)
k-Graph resulting graph G when applied on the Trace dataset [24]
1.研究方法
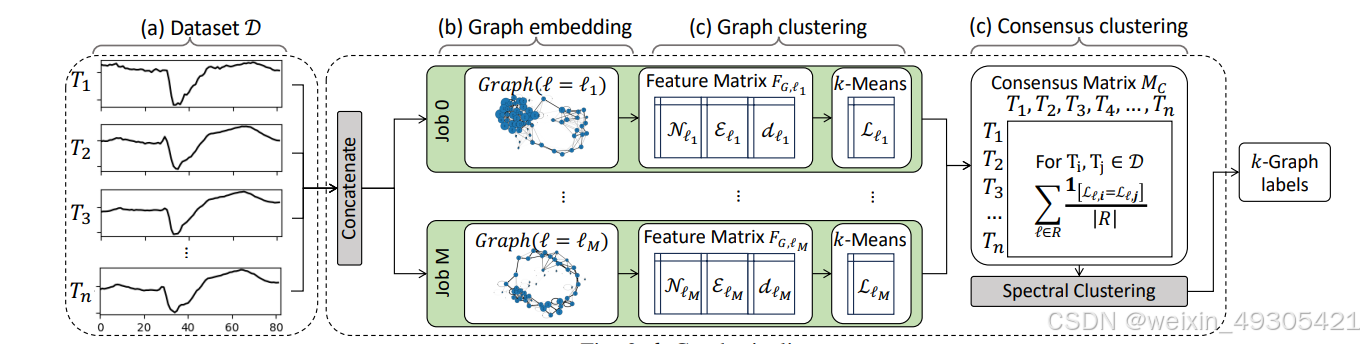
k-Graph pipeline
论文提出 k-Graph 方法用于时间序列聚类。先基于不同子序列长度构建多个图,将时间序列数据集转换为图表示;再从图中提取特征,用 k-Means 聚类;然后通过共识聚类得到最终标签;最后选择最相关的图计算图 oid,提升聚类结果的可解释性。
2.论文创新点
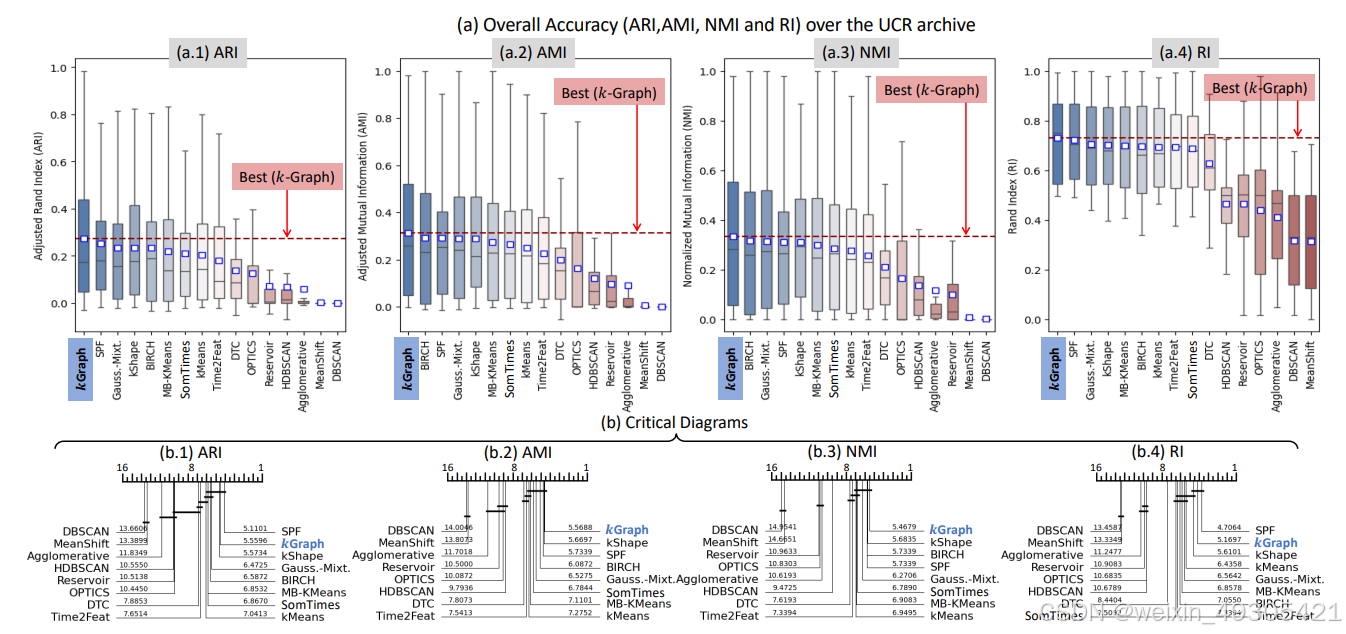
Experimental comparison of k-Graph versus the baselines on the UCR archive.
k -Graph这一图嵌入时间序列聚类方法,通过构建图、提取特征、共识聚类和计算可解释性图oid等步骤,实现对时间序列的聚类分析,并增强聚类结果的可解释性。其创新点如下:
-
新的问题公式化:形式化定义时间序列聚类中图表示的可解释性概念及其度量方式,为图嵌入时间序列聚类提供了新的理论框架。
-
图嵌入方法创新:提出适用于可变长度单变量时间序列聚类的图嵌入方法,通过构建多个基于不同子序列长度的图,为用户提供可解释的接口,便于挖掘数据集中的有意义模式。
-
性能优势:实验表明k -Graph在准确性上优于当前主流时间序列聚类算法,执行时间与现有方法处于同一量级,在处理含噪数据时表现更鲁棒。
-
可解释性增强:通过计算图oid,k -Graph能为聚类结果提供有意义的解释,帮助用户理解聚类逻辑,在实际数据集上展示了强大的知识发现能力。
论文链接:https://arxiv.org/abs/2502.13049
【论文2】E2USD: Efficient-yet-effective Unsupervised State Detection for Multivariate Time Series
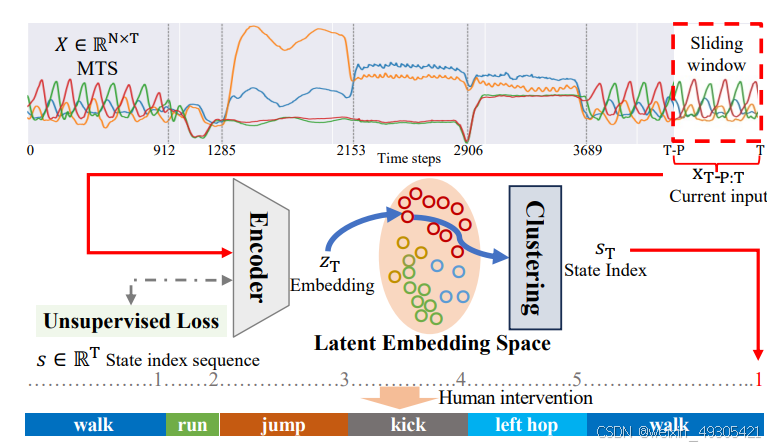
An example of unsupervised state detection on MTS.
1.研究方法
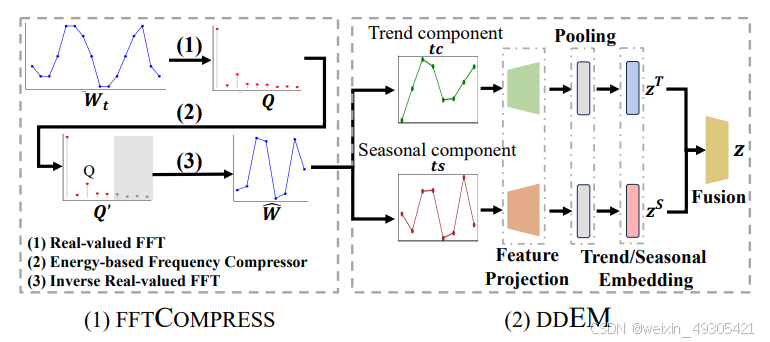
Compact embedding of the input MTS
论文提出统一框架 UP2ME,包含单变量预训练和多变量微调两个阶段。单变量预训练时,采用可变窗口长度和通道解耦技术生成实例,用掩码自动编码器(MAE)进行预训练以捕捉时间依赖;多变量微调阶段,冻结预训练的编码器和解码器,引入可训练的时间 - 通道(TC)层,通过构建通道间的依赖图来捕捉跨通道依赖并优化时间依赖。
2.论文创新点
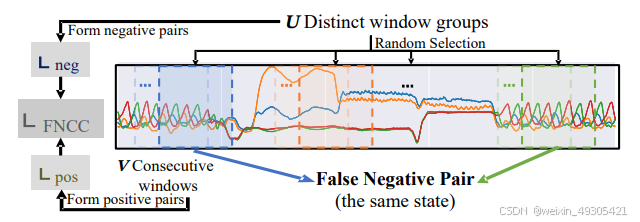
Overview of LFNCC. Same-color windows belong to the same group
-
紧凑嵌入方法:结合fftCompress和ddEM,前者基于快速傅里叶变换保留关键频率信息、减少噪声,后者将压缩后的时间序列分解为趋势和季节性成分进行双视图嵌入,有效融合传统与现代方法。
-
改进对比学习:提出fnccLearning方法,通过基于相似性的负采样策略,考虑趋势和季节性相似性来选择真正的负样本对,减少误判,优化嵌入空间,提高模型准确性。
-
自适应阈值检测:设计adaTD方案,根据当前窗口数据与前一窗口数据的相似性,自适应调整阈值决定是否聚类,减少在线聚类的冗余计算,平衡检测准确性和计算效率。
-
性能优势:在六个数据集上与六个基线模型对比实验,E2Usd在检测准确性和计算效率上表现出色,模型参数和计算量显著减少,能在资源受限设备上运行。
论文链接:https://arxiv.org/abs/2402.14041
点击【AI十八式】的主页,获取更多优质资源!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









