






贝叶斯推断的核心在于利用先验知识与新数据共同更新对未知参数的理解,从而获得后验概率。在机器学习中,贝叶斯方法被广泛应用于模型选择与参数估计,能够有效处理模型不确定性,提升算法性能和泛化能力,已在图像识别、自然语言处理等领域发挥重要作用。
当前,贝叶斯推断正不断拓展边界,与深度学习等前沿技术深度融合,为人工智能发展注入新动能。其在复杂系统建模、不确定性量化等方面持续创新,成为推动多学科交叉研究的关键力量,吸引越来越多科研人员投身其中,在多个领域创造更大价值。
我已整理13篇贝叶斯推断领域的最新论文及配套代码,内容涵盖算法创新、架构设计与跨学科应用案例,有需要的同行可无偿获取参考。
点击【AI十八式】的主页,获取更多优质资源!
【论文1:SCIENCE CHINA】Bayesian Inference of Neutron - Skin Thickness and Neutron - Star Observables Based on Effective Nuclear Interactions
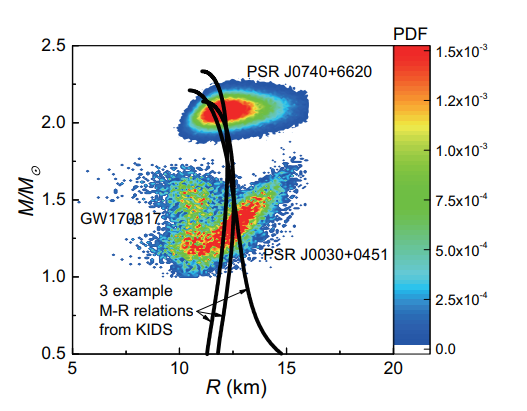
(Color online) Two-dimensional PDFs from the sampling data of the GW170817 event as well as the PSR J0030+0451 and the PSR J0740+6620 in the mass-radius (M-R) plane. Three representative highlyfavored M-R relations from the KIDS model, which pass through the most probable regions of the PDFs, are plotted for illustration
研究方法
论文基于标准 Skyrme-Hartree-Fock(SHF)模型、其扩展模型 KIDS 以及相对论平均场(RMF)模型,采用贝叶斯分析方法,通过构建似然函数对比理论计算与实验数据(中子皮厚度和中子星质量 - 半径关系等),提取模型参数的后验概率分布,从而约束核对称能从低到高密度的依赖关系。该方法结合宏观物理量参数化的能量密度泛函,在贝叶斯框架下高效探索参数空间,实现对核对称能的定量限制。
创新点
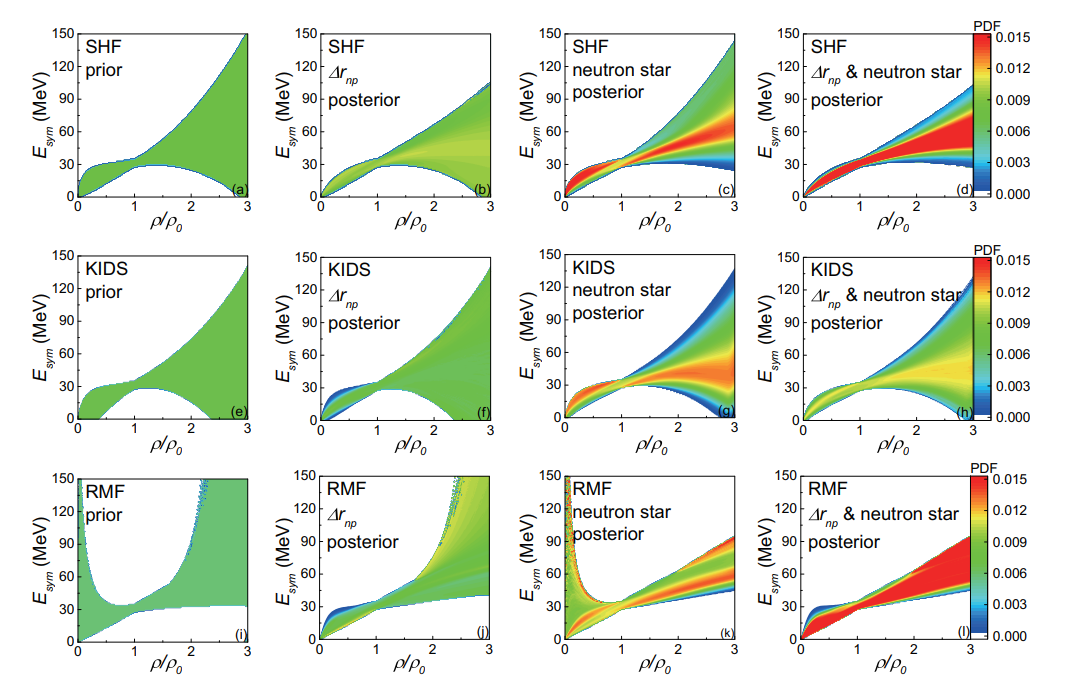
(Color online) Prior PDFs (first column) and posterior PDFs of the nuclear symmetry energy from the neutron-skin thickness data (second column), neutron-star observables (third column), and both data sets (fourth column), based on the standard SHF ((a)-(d)), KIDS ((e)-(h)), and RMF ((i)-(l)) models.
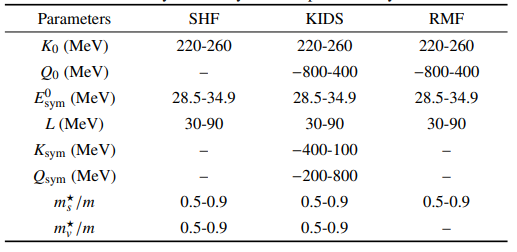
Prior ranges of model parameters in the standard SHF, KIDS, and RMF models for the Bayesian analysis in the present study
-
多模型贝叶斯联合约束:首次在贝叶斯框架下结合非相对论(SHF、KIDS)与相对论(RMF)有效核相互作用模型,系统对比不同模型对核对称能参数的约束差异,揭示模型依赖性对结果的影响。
-
跨尺度数据融合:利用贝叶斯方法融合核物理实验(PREX、CREX的中子皮厚度)与天体物理观测(GW170817、NICER的中子星数据),从亚饱和到超饱和密度区域联合限制对称能,突破单一数据类型的局限性。
-
宏观参数化与高效采样:将模型参数映射为对称能斜率、曲率等宏观物理量,通过马尔可夫链蒙特卡罗算法在贝叶斯分析中实现参数空间的高效探索,为核物理与天体物理交叉研究提供新的量化工具。
论文链接:https://link.springer.com/article/10.1007/s11433-024-2406-4
【论文2】CAN TRANSFORMERS LEARN FULL BAYESIAN INFERENCE IN CONTEXT?
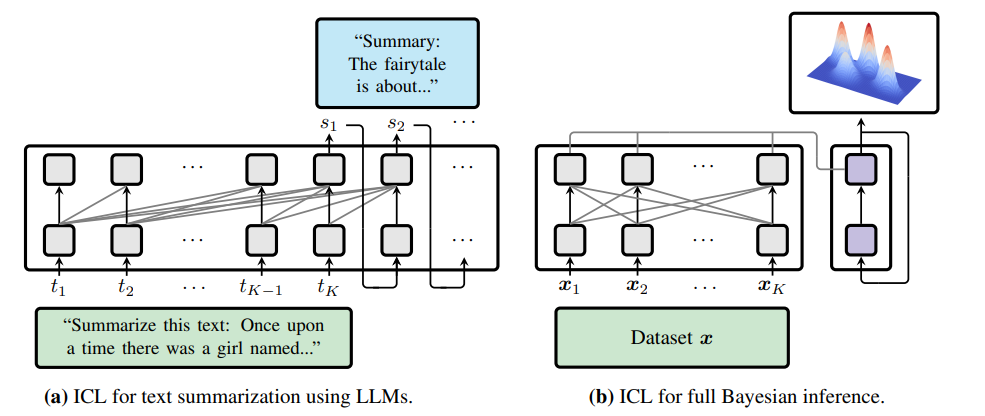
(a) An LLM generates a summary s1, s2, . . . of a text t1, t2, . . . , tK through autoregressive sampling while referring to the context using masked self-attention. (b) A dataset x is processed with a transformer encoder. Subsequently cross attention allows to generate samples from the posterior conditioned on x in context using a diffusion transformer (decoder) and flow matching.
研究方法

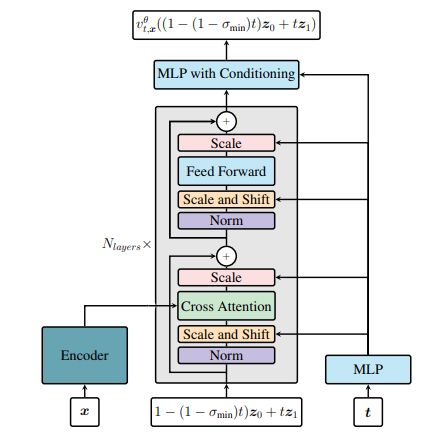
论文提出一种基于上下文学习(ICL)的全贝叶斯推断框架,利用Transformer模型结合连续归一化流(CNFs)和流匹配(flow matching)技术,通过合成数据训练模型学习从数据到后验分布的映射。具体而言,通过构建联合分布 (P(x, z)) 的模拟样本,训练Transformer编码器处理输入数据,解码器基于流匹配目标函数生成后验样本,实现无需显式参数更新的上下文贝叶斯推断,适用于广义线性模型(GLM)、潜在因子模型(FA)等场景,有效近似高维复杂后验分布。
创新点
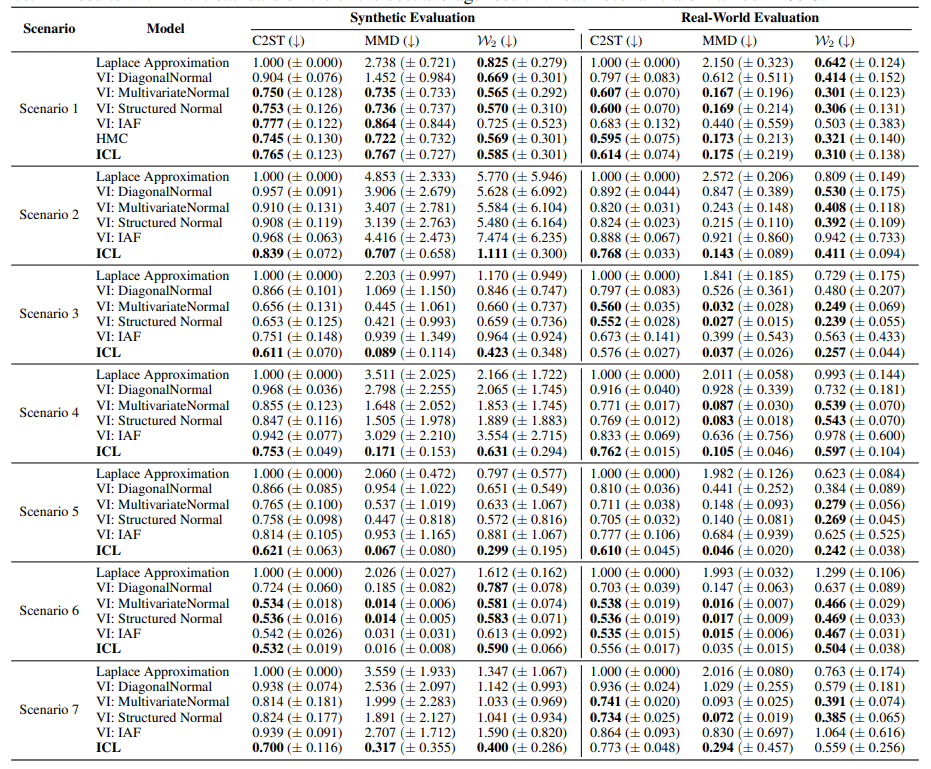
Generalized Linear Models: Evaluation on 50 synthetic and 17 real-world datasets for seven different scenarios. All results within two standard errors of the best average result for each scenario are marked in bold
-
上下文贝叶斯推断框架:首次将Transformer的上下文学习能力与流匹配技术结合,提出通用框架实现全贝叶斯推断,支持生成高维连续后验分布样本,突破传统变分推断(VI)对后验分布形式的假设限制。
-
数据驱动的后验建模:利用合成数据训练模型隐式学习后验分布,通过模拟联合分布 (P(x, z)) 样本,使模型能灵活适应不同输入数据,缓解模型误设问题,提升对真实数据的泛化能力。
-
多模型有效性验证:在GLM、FA、GMM等典型统计模型上验证方法有效性,实验表明该框架生成的后验样本质量接近哈密顿蒙特卡洛(HMC),且在真实数据集上优于多种变分推断方法,展现出强大的实用性和鲁棒性。
论文链接:https://arxiv.org/pdf/2501.16825
点击【AI十八式】的主页,获取更多优质资源!

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









