






人类语言是复杂且充满语义的,但计算机只能处理数字。
如何让计算机“读懂”一段文字?
词嵌入(Word Embedding)技术为此提供了关键解决方案:它将词语转化为数学向量,让计算机能够捕捉词语的语义和关系。
一、词嵌入:从“文字”到“向量”的魔法
1. 什么是词嵌入?
词嵌入是一种将词语映射为低维稠密向量的技术。例如,词语“苹果”可能被表示为一个300维的向量:
v苹果=[0.21,−0.56,0.87,…,0.34]
这些向量在空间中“排列”得很有规律:语义相近的词(如“苹果”和“香蕉”)距离更近,而语义无关的词(如“苹果”和“汽车”)则距离较远。
2. 词嵌入的核心思想:
基于“分布式语义学”理论--词语的含义由其上下文决定。例如,“银行”在“河边”和“金融”语境中的含义不同,词嵌入通过分析大量文本中的共现关系,让计算机学习到这些细微差别。
二、静态词向量:预训练的“词典”
1. 什么是静态词向量?
静态词向量是预先训练好的固定向量,不依赖具体任务。常用模型包括:
-
Word2Vec:通过神经网络学习词语的上下文关系(如CBOW和Skip-Gram模型)。
-
GloVe:结合全局词共现统计信息,生成更全局的词向量。
-
FastText:考虑子词信息,解决未登录词(OOV)问题。如processing拆分为process和ing)。
2. 静态词向量的特点:
-
固定表示:每个词的向量在模型中是固定的,无法捕捉上下文差异。例如,“苹果”在“水果”和“公司”语境中用同一向量表示。
-
通用性强:可在多种任务(如分类、情感分析)中复用,但无法针对特定任务优化。
三、动态词向量:上下文感知的“活字”
1. 什么是动态词向量?
动态词向量是模型在训练过程中动态学习的向量,能根据上下文调整表示。典型模型包括:
-
ELMo:通过双向LSTM捕捉上下文信息。
-
BERT:基于Transformer架构,结合深度上下文和双向信息。
-
GPT:通过自注意力机制学习语言模式。
2. 动态词向量的优势:
-
上下文敏感:同一词在不同语境下生成不同向量。例如,“银行”在“河边”和“金融”中用不同向量表示。
-
深层语义:通过多层神经网络捕捉更复杂的语义关系(如隐喻、情感)。 任务适配性:通过微调预训练模型(如BERT),可针对特定任务优化性能。 动态词向量的实现:
-
初始化:随机生成初始向量(如均匀分布),通过训练动态调整。 训练过程:与任务模型联合训练,向量随反向传播更新。
四、词表:连接文字与向量的“索引”
无论是静态还是动态词向量,都需要一个词表(Vocabulary):
-
功能:将单词映射为唯一索引(如“自然”→101)。
-
不存储向量:词表仅记录单词到索引的对应关系,词向量由其他机制提供。
-
静态词向量的词表:词表是预训练词向量库的一部分,如Word2Vec的词汇表和对应的向量矩阵。
-
动态词向量的词表:词表仅用于索引转换,词向量由模型参数动态生成(如BERT的Embedding层)。
五、Transformer中的词嵌入:位置与上下文的结合
Transformer如何实现词嵌入?
-
词表映射:将文本转换为索引序列(如“我喜欢学习”→[101, 202, 303])。
-
词向量生成:通过Embedding层将索引映射为随机初始化的向量,并在训练中动态学习。
-
位置编码:添加位置信息(如正弦函数或可学习的位置向量),解决Transformer缺乏顺序信息的问题。
示例:在句子“我喜欢苹果”中,“苹果”的词向量会根据上下文(如“喜欢”)动态调整,同时位置编码确保模型知道“苹果”位于句子末尾。
六、词嵌入的应用:从分类到生成
-
文本分类: 将句子的词向量拼接为矩阵,输入分类模型(如神经网络)。
-
文本相似度: 通过余弦相似度或欧氏距离比较向量空间中的文本距离。
-
生成任务: BERT等模型通过上下文敏感的词向量生成连贯的文本(如问答、翻译)。
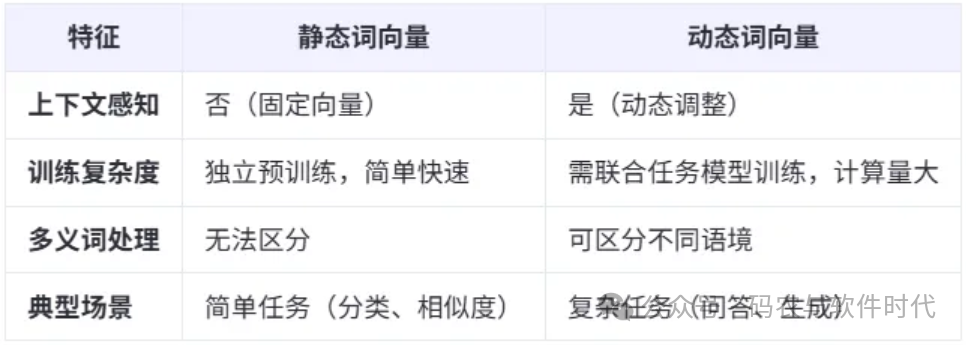
七、静态 vs 动态:如何选择?
八、未来展望:词嵌入的进化
随着大模型(如GPT-4、BERT)的发展,词嵌入技术正朝着更高效、更灵活的方向演进:
-
子词嵌入:FastText和Transformer的WordPiece技术提升未登录词处理能力。
-
动态适配:通过提示学习(Prompt Learning)进一步微调词向量的语义。
从静态的“词典式”向量到动态的“上下文感知”向量,词嵌入技术不断突破计算机与人类语言的鸿沟。无论是简单的分类任务,还是复杂的对话生成,词嵌入都是自然语言处理的“翻译密码”,让机器能够真正“读懂”人类的语言。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









