







LoRA技术详解—附实战代码
引言
随着大语言模型规模的不断扩大,如何高效地对这些模型进行微调成为了一个重要的技术挑战。Low-Rank Adaptation(LoRA)技术应运而生,它通过巧妙的低秩分解方法,显著减少了模型微调时需要训练的参数数量,同时保持了良好的性能表现。本文将深入介绍LoRA的原理,并通过详细的PyTorch代码实现来展示其工作机制。
LoRA的核心原理
基本思想
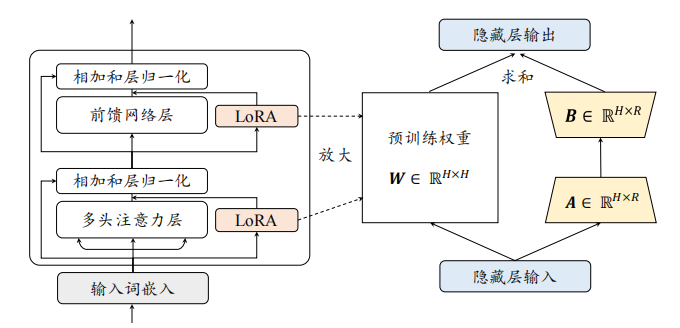
LoRA的核心思想是:在保持预训练模型权重不变的情况下,通过向每个转换器层添加低秩矩阵来实现模型的适应性调整。具体来说,对于原始的权重矩阵 W 0 ∈ R d × k W_0 \in \mathbb{R}^{d \times k} W0∈Rd×k,LoRA引入了如下的更新机制:
W = W 0 + Δ W = W 0 + B A W = W_0 + \Delta W = W_0 + BA W=W0+ΔW=W0+BA
其中:
- B
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2928
2928

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









