







Qwen2.5:自定义损失函数、验证指标【文本分类微调、视频讲解自定义验证指标出现显存爆炸的原因】
一、问题描述
在huggingface的Trainer微调Qwen 2.5 模型,自定义损失函数和评价指标后,模型就会出现显存爆炸的情况。
trainer=transformers.Trainer(
model=model,
args=train_args,
train_dataset=train_data,
eval_dataset=test_data,
data_collator=data_collator,
compute_metrics=compute_metrics
)二、原因
2.1 自定义 compute_metrics
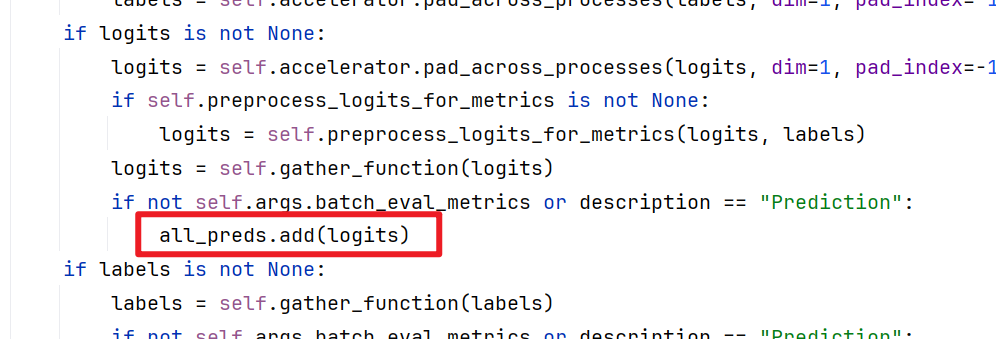
计算指标时处理了完整的 Logits 张量
-
默认验证方式:Hugging Face 的
Trainer默认在验证时仅计算损失值,不会保留完整的 Logits 张量。计算损失时,只需前向传播的中间结果,这些结果在计算后会被及时释放。 -
自定义
compute_metrics:当在compute_metrics中直接处理pred.predictions时,系统会保留 完整的 Logits 张量(形状为[batch_size, seq_len, vocab_size])。
2.2 自定义 compute_loss
默认ForCausalLMLoss函数的两种不同计算模式:
- 求和模式:当传入num_items_in_batch参数时,函数会对所有token的损失进行求和
- 平均模式:不传入该参数时,函数会计算batch内token损失的平均值
在分布式数据并行(DDP)训练中,transformers 库内部会处理梯度累积和多个设备间的同步问题。标准Trainer会自动考虑以下因素:
- 梯度累积步数
- 分布式训练的device数量
- batch大小的归一化处理
当直接重写compute_loss方法时,这些自动处理机制可能被绕过,导致损失计算和梯度更新出现偏差。
三、解决方案
1. 在TrainingArguments中设置per_device_eval_batch_size,它代表每次处理几条数据。官方的文档是这样说的:
per_device_eval_batch_size (`int`, *optional*, defaults to 8):
The batch size per device accelerator core/CPU for evaluation.
gradient_accumulation_steps (`int`, *optional*, defaults to 1):
Number of updates steps to accumulate the gradients for, before performing a backward/update pass.
<Tip warning={true}>
When using gradient accumulation, one step is counted as one step with backward pass. Therefore, logging,
evaluation, save will be conducted every `gradient_accumulation_steps * xxx_step` training examples.
</Tip>
2. 在TrainingArguments中设置eval_accumulation_steps ,它代表多久一次将tensor搬到cpu。官方的文档是这样说的:
eval_accumulation_steps (`int`, *optional*):
Number of predictions steps to accumulate the output tensors for, before moving the results to the CPU. If left unset, the whole predictions are accumulated on the device accelerator before being moved to the CPU (faster but requires more memory).
3. 在Trainer中设置preprocess_logits_for_metrics方法,它代表你要在每一个eval step后怎么处理这些张量,如果你并不需要所有的logits(例如我只想知道它到底属于哪一类),那么你可以在这个方法中定义,从而减小合并的时候占用的显存。官方的文档是这样说的:
preprocess_logits_for_metrics (
Callable[[torch.Tensor, torch.Tensor], torch.Tensor], optional) — A function that preprocess the logits right before caching them at each evaluation step. Must take two tensors, the logits and the labels, and return the logits once processed as desired. The modifications made by this function will be reflected in the predictions received bycompute_metrics.
4. 在Trainer中设置compute_loss_func 方法,它接受原始模型输出、标签和整个累计中的项目数的函数批处理,并返回损失。官方的文档是这样说的:
compute_loss_func (`Callable`, *optional*):
A function that accepts the raw model outputs, labels, and the number of items in the entire accumulated batch (batch_size * gradient_accumulation_steps) and returns the loss. For example, see the default [loss function (https://github.com/huggingface/transformers/blob/052e652d6d53c2b26ffde87e039b723949a53493/src/transformers/trainer.py#L3618) used by [`Trainer`].

















 1261
1261

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









