



一、技术路线概述
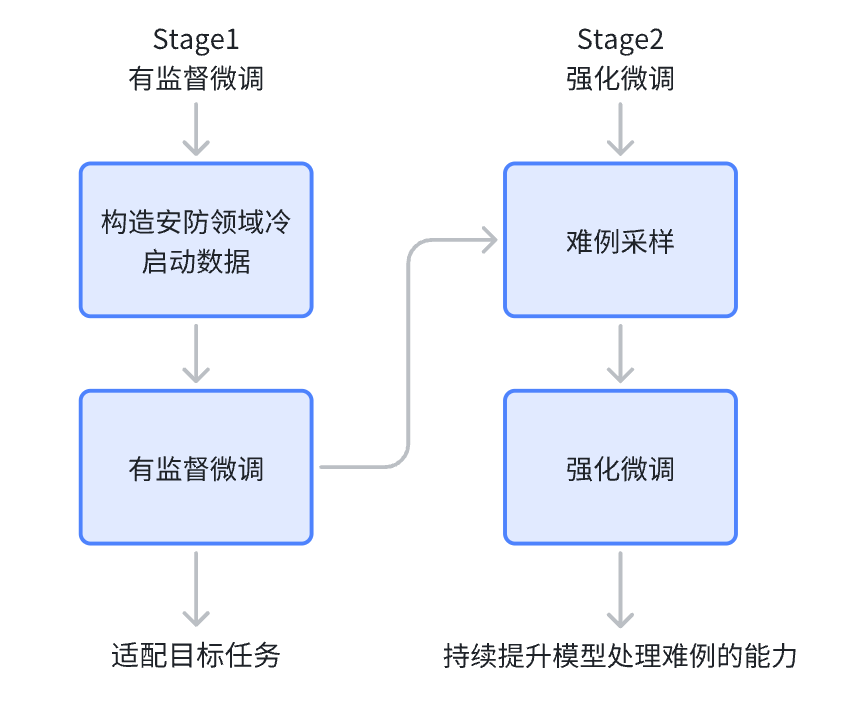
整体技术流程如下:
-
第一阶段:SFT监督微调 在安防场景构建的小规模冷启动数据集上,对基础多模态模型进行指令微调(SFT),让模型初步适配目标任务。
-
第二阶段:强化学习微调 基于 SFT 模型结果,通过难例采样机制进一步训练策略模型,采用 强化学习的方法,使模型在复杂样本上持续提升。
二、数据合成管道
多模态模型训练对数据质量要求极高,但安防领域往往数据缺失。我们搭建了一套完整的数据合成与筛选流水线:
1、基础目标场景数据获取:
-
视频爬取:采集各类真实监控视频(经脱敏处理);
-
公开数据集:如 VisDrone、UCF-Crime 等;
-
LVLM筛选:使用 Qwen2.5-VL 对图像进行自动标注与分类;
-
合成方式:使用图像合成器(如ControlNet+Diffusers)或VideoCrafter等生成特定场景片段。
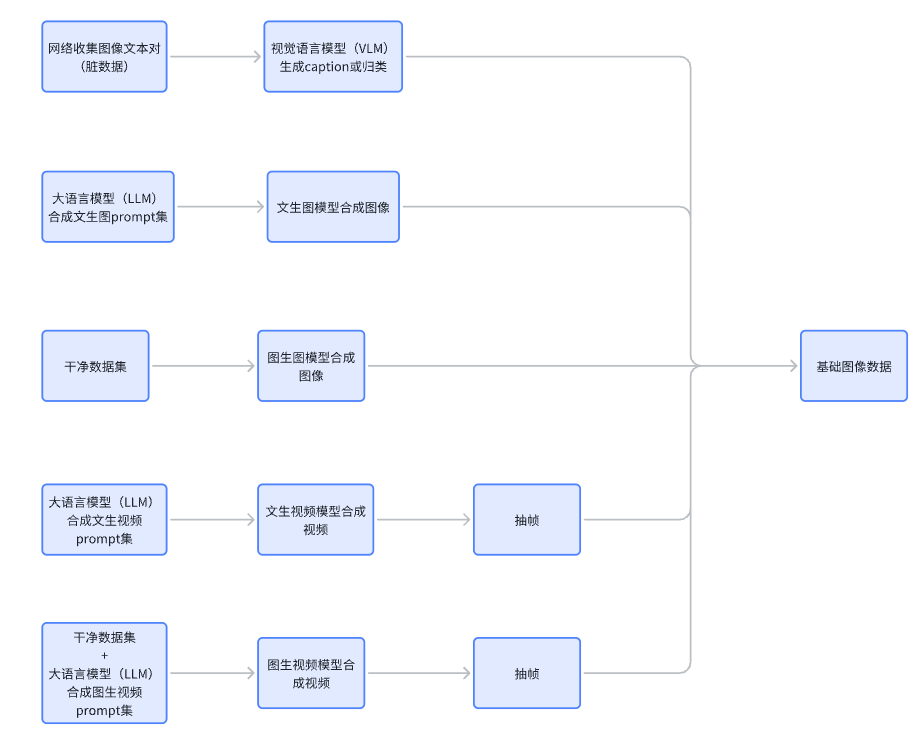
2、SFT数据与强化学习数据合成
借助LVLM模型进行模态桥接,再通过DeepSeek-R1生成图片对应目标场景问题的文本回复,通过这种方式,可以自然的获取DeepSeek-R1的思考数据,构建了一个适用于安防场景的冷启动训练集,并可持续更新以支撑强化训练。
本篇文章分享了我们在安防场景下应用多模态大模型的一整套训练流程。从小样本 SFT 微调到强化训练 ,从真实数据收集到高质量数据合成,在提升模型能力的同时也保障了其在垂直场景中的泛化与安全性。
未来我们计划进一步探索视频链路推理、多轮问答等更复杂的多模态任务,同时结合边端部署优化模型体积与推理速度,推动大模型真正落地安防实际应用。
三、监督微调(SFT)
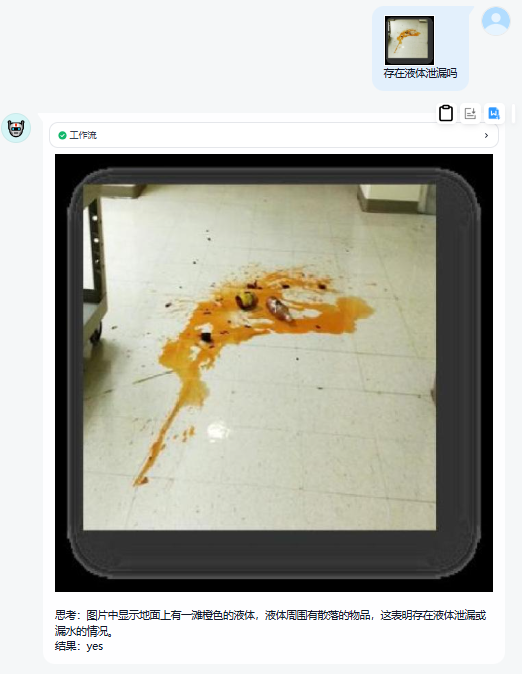
在冷启动阶段,我们构建了一个小规模但覆盖典型安防事件的多模态问答数据集,包含图像 + 自然语言指令 + 目标回答。
-
输入形式:图片(base64)、任务描述(prompt),输出为自然语言回答
-
数据:着重覆盖典型安防事件图片,合成约20万条数据的微调数据集
-
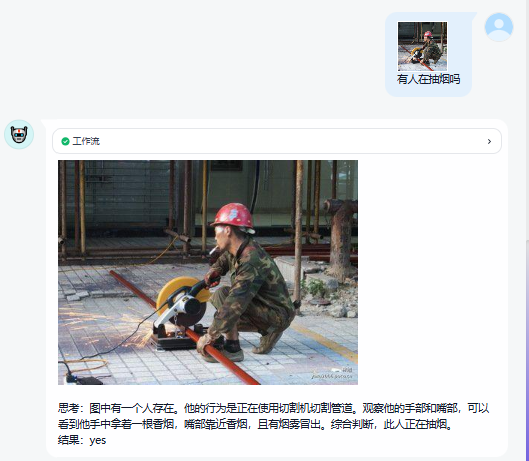
训练目标:让模型学会理解安防场景中的典型语义,例如“有人未佩戴安全帽”、“存在高空作业未佩戴安全带或安全绳”等
监督微调采用标准的 cross-entropy 损失进行训练,训练后模型能力大大提升,具备微调场景的识别能力。
四、后训练
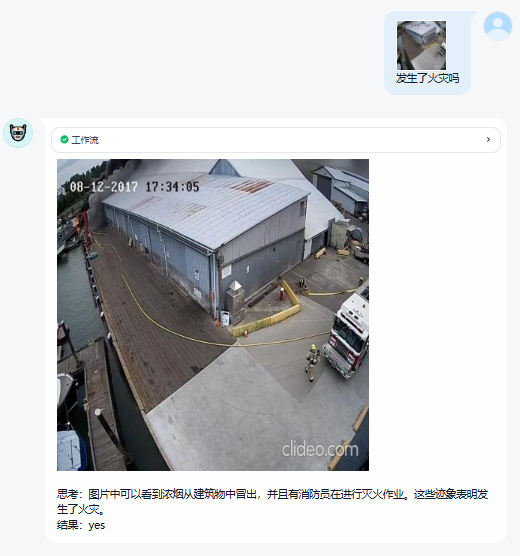
SFT 模型已具备基本能力,但在复杂场景、遮挡、模糊、夜间等难例上仍有明显短板。为此,我们进一步引入 强化训练,提升模型的泛化与鲁棒性。
2、强化训练优势
-
使用奖励信号指导策略学习;
-
可用于持续迭代强化模型对难例的处理能力;
3、强化微调难例收集策略
强化训练前的一个关键步骤是难例筛选与采集,我们采用以下方式构建训练样本:
-
真实安防视频中模型失败样本回溯;
-
大模型在测试集上的预测偏差;
-
使用图像变换、光照/遮挡模拟生成“对抗样本”;
在安防等垂直领域,如何结合有限的场景数据进行模型适配与强化,是落地的关键。本篇文章分享我们在安防场景下的一套多模态微调流程,涵盖了从监督微调(SFT)到强化训练,以及数据合成与筛选的完整闭环。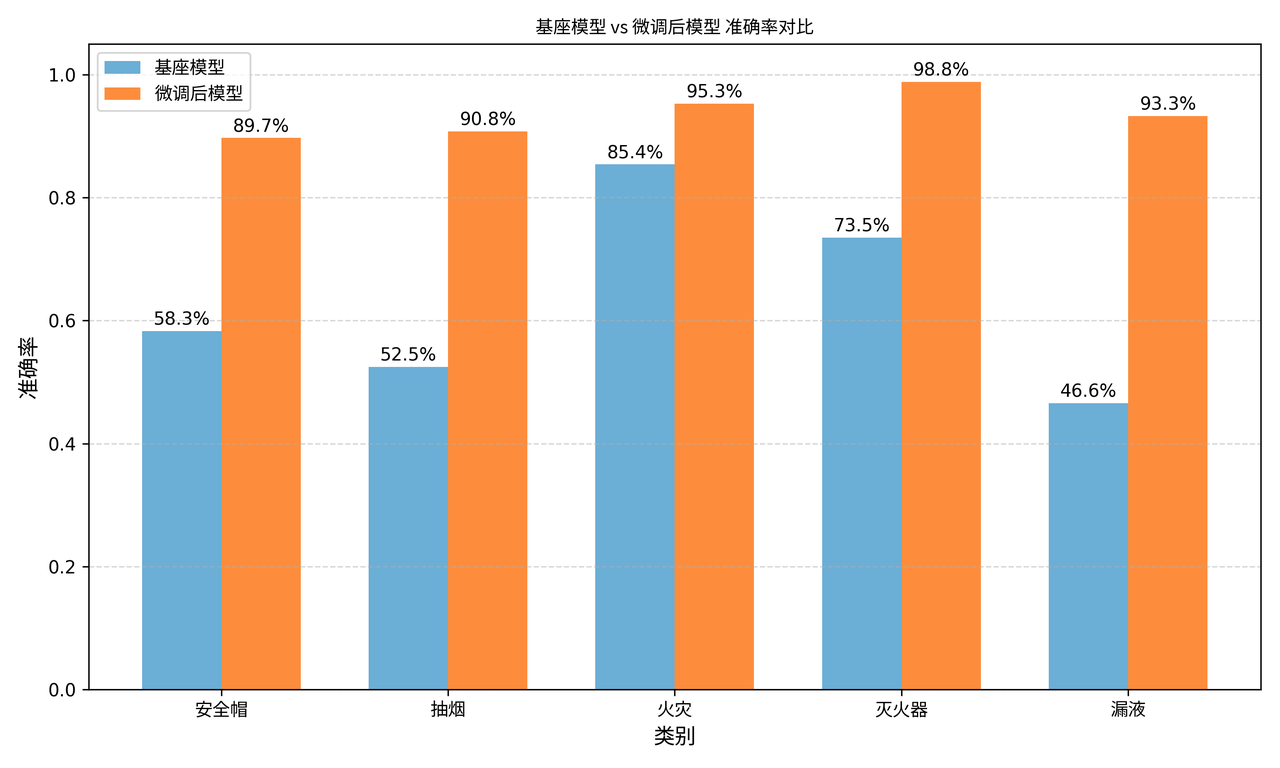


















 1173
1173

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









