







系列篇章💥
一、前言
在信息多元且海量的当下,视频凭借强大表现力与信息承载量,广泛用于娱乐、商业分析、科研数据记录等领域,其蕴含的丰富信息极具价值。如何高效精准提取这些信息,成为各界关注焦点。Qwen2.5-Omni 作为先进的多模态大模型,能理解视频的视觉、音频及相关文本信息,解答复杂问题,满足多样化信息提取需求。接下来,让我们深入体验如何巧用 Qwen2.5-Omni 从视频流中获取关键信息。
二、环境准备
如果在此之前,已经成功完成了相关的安装和准备工作,可以直接跳过此章节,快速进入到模型的实战应用环节。
(一)安装相关依赖
首先需要安装一系列关键的依赖库。这些依赖库共同为模型的运行提供支持。以下是具体的安装步骤:
pip uninstall transformers
pip install git+https://github.com/huggingface/transformers@f742a644ca32e65758c3adb36225aef1731bd2a8
pip install accelerate
pip install triton
pip install qwen-omni-utils
pip install -U flash-attn --no-build-isolation
# 用于从魔塔模型库下载模型
pip install modelscope
(二)模型下载准备
为了确保在后续的音频处理任务中能够顺畅地使用Qwen2.5-Omni模型,我们需要提前将模型下载到本地备用。这里,我们借助modelscope库中的snapshot_download函数来完成这一重要任务。代码如下:
from modelscope import snapshot_download
model_dir = snapshot_download('Qwen/Qwen2.5-Omni-7B', cache_dir='/root/autodl-tmp', revision='master')
代码中,snapshot_download函数的第一个参数'Qwen/Qwen2.5-Omni-7B'明确指定了我们要下载的模型名称,这个名称在modelscope平台上是唯一标识该模型的。cache_dir='/root/autodl-tmp'参数则用于指定模型下载后存储的路径,你可以根据自己的实际情况修改这个路径,但务必确保指定的目录具有足够的存储空间来容纳模型文件。因为Qwen2.5-Omni模型文件相对较大,充足的存储空间是保证下载成功的关键。revision='master'表示我们要下载模型的最新版本,这样可以获取到模型的最新特性和优化,以获得最佳的使用体验。
三、加载模型 & 导入依赖
当环境搭建完毕,模型也成功下载到本地后,接下来的核心步骤便是加载模型并导入相关依赖,为智能信息交互做好最后的准备工作。具体代码如下:
import torch
from transformers import Qwen2_5OmniModel, Qwen2_5OmniProcessor
from IPython.display import Video
model_path = "/root/autodl-tmp/Qwen/Qwen2.5-Omni-7B"
model = Qwen2_5OmniModel.from_pretrained(
model_path,
torch_dtype=torch.bfloat16,
device_map="auto",
attn_implementation="flash_attention_2",
)
processor = Qwen2_5OmniProcessor.from_pretrained(model_path)
在这段代码中,启用了flash_attention_2技术,这是一种高效的注意力机制实现方式,能进一步提升模型处理视频数据时的计算效率,使模型在信息交互场景中响应更迅速、准确。
四、定义推理函数
为高效处理视频输入和文本提示,并生成精准的文本输出,我们需定义一个专属推理函数。此函数协调模型与各类工具,确保任务顺利推进。以下是推理函数的详细代码:
from qwen_omni_utils import process_mm_info # 导入用于处理多模态信息的工具函数
# @title inference function
def inference(video_path, prompt, sys_prompt):
"""
推理函数,用于处理视频输入和文本提示,并生成文本输出。
参数:
- video_path: 视频文件路径
- prompt: 用户提供的文本提示
- sys_prompt: 系统提示,用于定义模型的角色和行为
返回值:
- text: 模型生成的文本输出
"""
# 构建输入消息,包括系统消息和用户消息
messages = [
{"role": "system", "content": sys_prompt}, # 系统消息,定义模型的角色和行为
{"role": "user", "content": [ # 用户消息,包含文本提示和视频输入
{"type": "text", "text": prompt}, # 文本提示
{"type": "video", "video": video_path}, # 视频输入路径
]
},
]
# 使用 processor 应用聊天模板,将消息转换为模型可处理的文本格式
# 参数 tokenize=False 表示不对文本进行分词处理,add_generation_prompt=True 表示添加生成提示
text = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
# 调用 process_mm_info 函数处理多模态信息
# 提取音频、图像和视频信息,use_audio_in_video=False 表示不从视频中提取音频信息
audios, images, videos = process_mm_info(messages, use_audio_in_video=False)
# 使用 processor 将文本、音频、图像和视频信息转换为模型输入张量
# return_tensors="pt" 表示返回 PyTorch 张量,padding=True 表示对输入进行填充以匹配最大长度
inputs = processor(text=text, audios=audios, images=images, videos=videos, return_tensors="pt", padding=True, use_audio_in_video=False)
# 将输入张量移动到模型所在的设备和数据类型
inputs = inputs.to(model.device).to(model.dtype)
# 调用模型的 generate 方法生成输出
# use_audio_in_video=False 表示在生成过程中不使用音频信息,return_audio=False 表示不返回音频输出
output = model.generate(**inputs, use_audio_in_video=False, return_audio=False)
# 解码生成的文本输出
# skip_special_tokens=True 表示跳过特殊标记,clean_up_tokenization_spaces=False 表示不清理多余的空格
text = processor.batch_decode(output, skip_special_tokens=True, clean_up_tokenization_spaces=False)
# 返回生成的文本结果
return text
五、基于视频提问(一)
以下代码通过 Qwen2.5-Omni 对视频文件进行推理,并生成文本输出,实现对视频中饮品种类数量的查询:
#video_path = "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2.5-Omni/shopping.mp4"
video_path = "files/shopping.mp4"
prompt = "How many kind of drinks can you see in the video?"
display(Video(video_path, width=640, height=360))
## Use a local HuggingFace model to inference.
response = inference(video_path, prompt=prompt, sys_prompt="You are a helpful assistant.")
print(response[0])
代码执行如下:
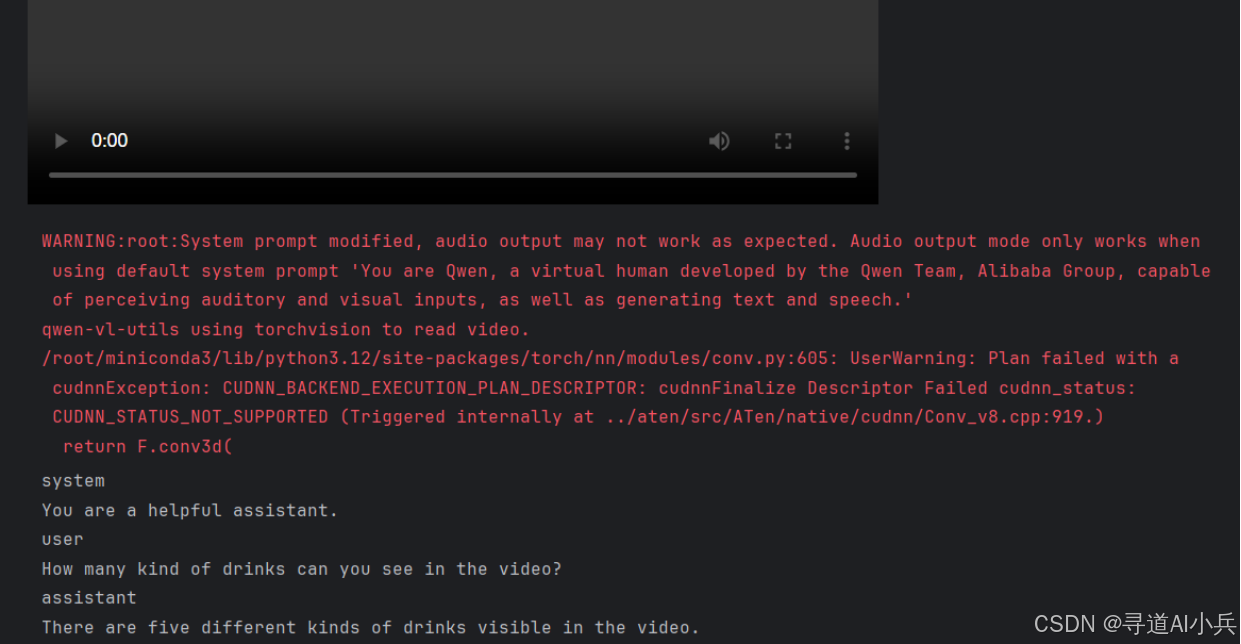
资源消耗如下:
六、基于视频提问(二)
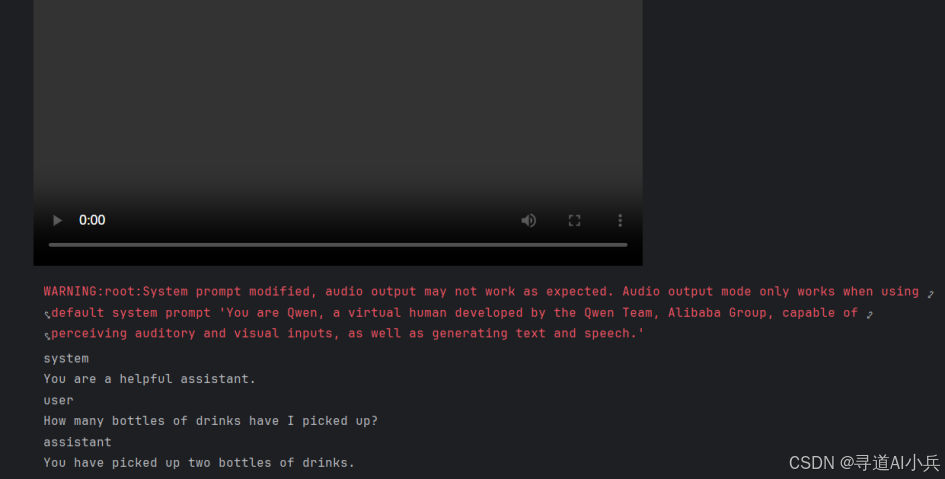
以下代码通过 Qwen2.5-Omni 对视频文件进行推理,并生成文本输出,用于查询视频中拿起饮品的瓶数:
#video_path = "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2.5-Omni/shopping.mp4"
video_path = "files/shopping.mp4"
prompt = "How many bottles of drinks have I picked up?"
display(Video(video_path, width=640, height=360))
## Use a local HuggingFace model to inference.
response = inference(video_path, prompt=prompt, sys_prompt="You are a helpful assistant.")
print(response[0])
代码执行如下:
七、基于视频提问(三)
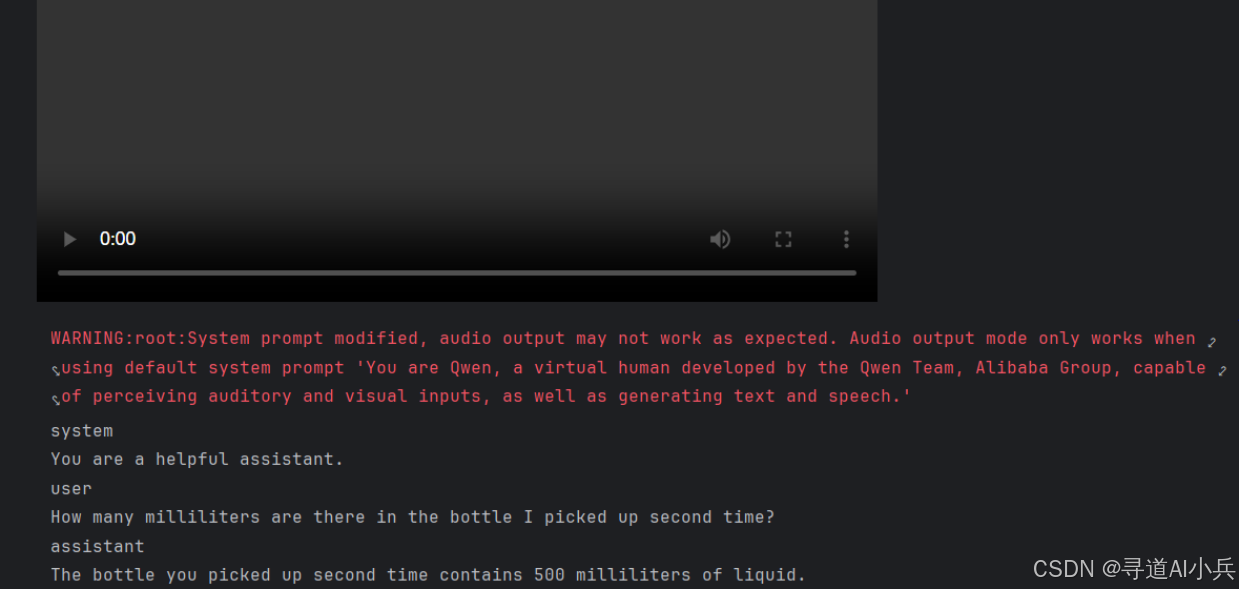
以下代码通过 Qwen2.5-Omni 对视频文件进行推理,并生成文本输出,旨在获取视频中第二次拿起饮品的瓶身容量信息:
#video_path = "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2.5-Omni/shopping.mp4"
video_path = "files/shopping.mp4"
prompt = "How many milliliters are there in the bottle I picked up second time?"
display(Video(video_path, width=640, height=360))
## Use a local HuggingFace model to inference.
response = inference(video_path, prompt=prompt, sys_prompt="You are a helpful assistant.")
print(response[0])
代码执行如下:
八、总结
通过本文的详细介绍,我们全面展示了如何运用 Qwen2.5-Omni 模型从视频流中精准提取信息。在实际操作过程中,通过灵活定义不同的系统提示和用户提示,我们能够巧妙地调控模型的行为,使其完美适配各类复杂多变的应用场景。无论是在商业领域对市场调研视频进行数据分析,精准洞察消费者行为;还是在教育场景中,从教学视频里提取关键知识点,辅助教学评估与优化;亦或是在安防监控方面,对监控视频进行智能分析,及时发现异常事件等,Qwen2.5-Omni 都能凭借其卓越的多模态处理能力,提供高效且准确的信息提取服务。

🎯🔖更多专栏系列文章:AI大模型提示工程完全指南、AI大模型探索之路(零基础入门)、AI大模型预训练微调进阶、AI大模型开源精选实践、AI大模型RAG应用探索实践🔥🔥🔥 其他专栏可以查看博客主页📑
😎 作者介绍:资深程序老猿,从业10年+、互联网系统架构师,目前专注于AIGC的探索(CSDN博客之星|AIGC领域优质创作者)
📖专属社群:欢迎关注【小兵的AI视界】公众号或扫描下方👇二维码,回复‘入群’ 即刻上车,获取邀请链接。
💘领取三大专属福利:1️⃣免费赠送AI+编程📚500本,2️⃣AI技术教程副业资料1套,3️⃣DeepSeek资料教程1套🔥(限前500人)
如果文章内容对您有所触动,别忘了点赞、⭐关注,收藏!加入我们,一起携手同行AI的探索之旅,开启智能时代的大门!



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











