






本研究旨在构建一个基于Python的网络小说榜单数据采集与分析系统,通过对17k网站海量的小说信息进行深度挖掘和分析,为小说行业提供数据支持和决策依据。系统采用Python编程语言、Django、Vue框架,结合大数据处理技术Spark、hadoop、MySQL数据库技术以及数据可视化工具,实现了数据爬取、清洗、存储、分析和可视化等一系列功能。通过对作者信息,类别信息,小说信息,小说名称,标签,字数等多维度信息的分析,系统展现了小说市场的整体趋势、用户偏好以及出版社表现,为17k网站及整个小说行业提供了有价值的市场洞察。
该系统不仅提升了17k网站的业务运营效率,优化了营销策略和库存管理,还增强了用户体验和市场竞争力。同时,系统为出版社、作者和读者提供了丰富的数据资源和分析工具,有助于他们更好地了解市场动态、把握创作方向和满足阅读需求。未来,随着大数据技术的不断进步和应用的深入,系统将进一步拓展功能、提升性能,成为小说行业乃至整个文化产业的重要数据支撑平台,推动行业的持续创新和发展。
关键词:Python技术;17k网站小说;网络小说榜单数据采集与分析系统;数据可视化实现
系统使用收集小说的作者信息,类别信息,小说信息,小说名称,标签,字数等行为数据的公开数据集,来构建小说的数据分析。用户可以通过查询条件的方式,让系统实现对相关数据的筛选和查询,并将查询结果在前端以图表的可视化方式展示出来,进而帮助用户理解数据。系统通过对用户数据的分析与挖掘,实现了对于用户评论的解析和分类,系统提供了直观的17k网站小说数据展示界面,查看到相应的分析结果。数据采集功能实现对17k网站平台公共数据的采集,识别数据来源、区分数据类型,并进行数据完整性的验证,确保数据的准确性以及可靠性。
分布式存储功能实现对已经处理过的数据进行分布式存储,采用MySQL、HDFS进行对数据的存储,以及支持异构端存储和具备高容错性,高可用性以及易扩展性。数据分析功能基于Spark分布式计算框架,实现对存储的数据进行了数据分析和挖掘。
数据可视化功能使用ECharts、Vue、BootStrap等前端技术,对数据分析结果进行了可视化展示,以图表等可视化方式将数据展示,方便了用户分析和观察。系统功能模块图如图3-1所示。
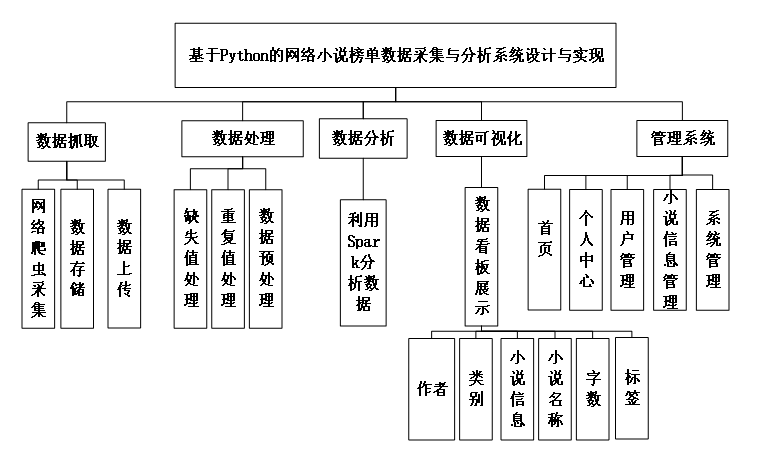
图3-1 系统功能模块图
数据可视化就是运用各种图表和图形化设计手段进行设计,把纷繁复杂的非直观数据进行合乎逻辑的展示,揭示资料潜在的规律及其价值,用真实数据反映市场问题,把海量的数据变成图表,以更加直观的方式呈现出来,以帮助企业决策。通过对用户评论的分析来实现精准营销。
在数据可视化面板界面可以查看到所有数据的详情。数据看板集成了多个功能模块,为用户提供直观的数据展示和分析能力。数据可视化模块的实现依赖于多种技术的协同工作,使用Python编写的爬虫程序负责从17k网站上抓取海量小说和评论数据,将这些非结构化数据导入到Hadoop分布式文件系统中进行存储和管理,利用Spark框架对这些大规模数据进行快速的计算和分析,将处理后的结果存入Hive数据库中以方便后续查询和检索,后端采用Django框架搭建Web应用服务器,前端则使用Vue.js库来创建交互式界面,并通过Echarts图表库绘制各种可视化图形。
基于Python的网络小说榜单数据采集与分析系统的数据可视化面板实现了多个功能模块。作者分布模块展示了不同作者的占比情况;类别统计模块比较了不同类别的小说数量和受欢迎程度;小说信息总览模块列出了小说的基本信息;标签云模块展示了热门标签的频率和重要性;字数统计模块展示了不同小说的字数变化趋势;标签热度模块比较了不同标签的热度差异。这些模块共同构成了一个全面、直观且易于操作的分析平台。可视化效果图如下所示:
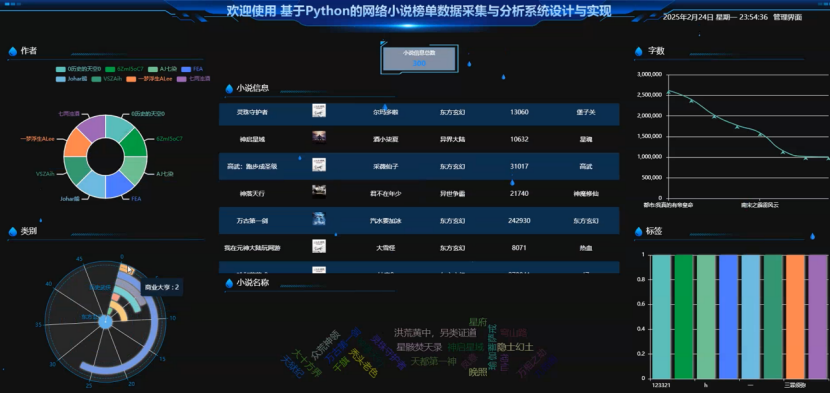
图5-1 数据可视化看板

















 170
170

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









