



探秘华为昇腾(Ascend)AI计算平台:从官网信息看国产AI芯片的崛起
引言
近年来,随着人工智能技术的迅猛发展,底层算力基础设施的重要性愈发凸显。作为中国在AI芯片领域的重要代表,华为昇腾(Ascend)系列AI处理器及其配套软硬件生态正逐步构建起自主可控的AI计算体系。本文基于 hiascend.com 官网公开资料,结合其产品架构、开发工具链及典型应用场景,深入解析昇腾平台的技术亮点,并通过代码示例展示如何使用昇腾CANN(Compute Architecture for Neural Networks)进行模型部署。
一、昇腾平台概览
华为昇腾是面向AI训练与推理场景设计的专用AI处理器系列,主要包括:
-
Ascend 910:高性能AI训练芯片,支持FP16/BF16/INT8等多种精度;
-

-
Ascend 310:低功耗AI推理芯片,适用于边缘设备和终端场景。
-
搭载 Ascend 310 的 Atlas 200 DK 开发板:Atlas 200 DK 是基于 Ascend 310 芯片的开发板,下图为其图片。
-

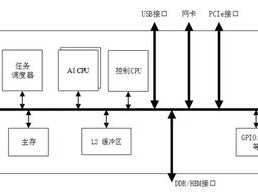
Ascend 310 处理器逻辑架构图:Ascend 310 采用达芬奇架构,下图展示了其处理器的逻辑架构。
配合昇腾芯片的是 CANN 软件栈,它提供从驱动、运行时、图编译器到算子库的完整支持,向上兼容主流深度学习框架(如TensorFlow、PyTorch),向下打通硬件资源调度。
CANN 架构层次示意图:CANN 软件栈采用分层设计,自下而上包括驱动层、Runtime 层、AscendCL 接口、图引擎层和应用 / 框架层等。
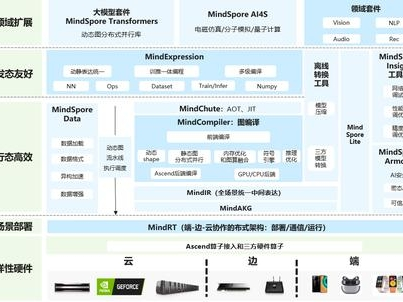
此外,华为还推出了 MindSpore 框架,与昇腾深度协同,实现“端-边-云”全场景AI部署。
MindSpore 总体架构图:展示了 MindSpore 的各个组成部分及其相互关系,包括表达层、数据处理、计算图构建等模块。具体如下:
—
二、昇腾开发环境搭建简述
要在本地或服务器上使用昇腾AI加速能力,通常需完成以下步骤:
- 安装昇腾驱动与固件;
- 部署CANN Toolkit;
- 配置Python环境并安装
acl(Ascend Computing Language)相关依赖。
注:详细安装指南可参考 昇腾社区文档
三、代码示例:使用ACL API加载并推理一个ONNX模型
以下是一个基于昇腾ACL(Ascend Computing Language)API的简单推理示例,展示如何在Ascend 310/910设备上加载ONNX模型并执行推理。
import acl
import numpy as np
def init_acl_device():
"""初始化ACL运行环境"""
ret = acl.init()
if ret != acl.ACL_ERROR_NONE:
raise RuntimeError(f"ACL init failed: {ret}")
ret = acl.rt.set_device(0) # 使用设备0
if ret != acl.ACL_ERROR_NONE:
raise RuntimeError(f"Set device failed: {ret}")
context, ret = acl.rt.create_context(0)
if ret != acl.ACL_ERROR_NONE:
raise RuntimeError(f"Create context failed: {ret}")
def load_model(model_path):
"""加载离线模型(.om格式)"""
model_id, ret = acl.mdl.load_from_file(model_path)
if ret != acl.ACL_ERROR_NONE:
raise RuntimeError(f"Load model failed: {ret}")
return model_id
def run_inference(model_id, input_data):
"""执行模型推理"""
dataset = acl.mdl.create_dataset()
input_buffer = acl.create_data_buffer(input_data.ctypes.data, input_data.nbytes)
acl.mdl.add_dataset_buffer(dataset, input_buffer)
output_dataset = acl.mdl.create_dataset()
# 假设输出只有一个tensor
output_size = 1000 * 4 # float32, 1000 classes
output_ptr = acl.rt.malloc(output_size, acl.ACL_MEM_MALLOC_NORMAL_ONLY)
output_buffer = acl.create_data_buffer(output_ptr, output_size)
acl.mdl.add_dataset_buffer(output_dataset, output_buffer)
ret = acl.mdl.execute(model_id, dataset, output_dataset)
if ret != acl.ACL_ERROR_NONE:
raise RuntimeError(f"Inference failed: {ret}")
# 从设备内存拷贝结果到主机
output_host = np.empty((1000,), dtype=np.float32)
acl.rt.memcpy(output_host.ctypes.data, output_host.nbytes,
output_ptr, output_size, acl.ACL_MEMCPY_DEVICE_TO_HOST)
acl.rt.free(output_ptr)
return output_host
if __name__ == "__main__":
init_acl_device()
model_id = load_model("resnet50.om") # 需提前用ATC工具转换ONNX为.om
input_data = np.random.randn(1, 3, 224, 224).astype(np.float32)
result = run_inference(model_id, input_data)
print("Top-5 predictions:", np.argsort(result)[-5:][::-1])
**四、昇腾生态的优势与挑战**
**优势:
1.全栈自研技术闭环**
华为构建了从底层芯片到上层应用的完整AI技术体系:
芯片层:Ascend系列AI处理器(如Ascend 910/310)。
框架层:MindSpore深度学习框架(支持自动并行、二阶优化等特性)。
工具链:昇腾AI全栈工具包(包含编译器、调试器等)。
应用层:覆盖智慧城市、医疗影像等20+行业解决方案。
示例:在深圳智慧交通项目中,昇腾全栈方案实现了从边缘摄像头的图像识别到云端决策的完整AI流水线。
**2.高能效比设计**
Ascend 910采用7nm工艺,FP16算力达256 TFLOPS,同时通过动态功耗管理将典型功耗控制在310W。
相比同级别GPU,在ResNet50训练任务中能效比提升50%以上。
支持8卡Atlas 900集群,提供2.56 PFLOPS的极致算力。
**3.国产化替代价值**
完全自主知识产权,规避美国技术出口管制风险。
已进入信创产品目录,在政务、金融等领域实现规模化替代。
与国内高校共建"智能基座"项目,培养国产AI人才。
**挑战:
1.生态成熟度差距**
CUDA生态拥有超过3000个加速库,而昇腾的CANN生态目前核心库约200个。
主流框架(如PyTorch)的昇腾后端支持仍处于完善阶段。
中文技术文档占比超80%,国际化程度不足。
开源社区活跃度(GitHub star数)仅为TensorFlow的1/10。
第三方工具链适配案例较少(如缺少Colab环境支持)。
**3.技术准入门槛**
需要掌握华为特有的开发范式(如图算融合编程)。
调试工具(如MindStudio)对非华为硬件兼容性有限。
模型迁移成本较高,典型CV模型需修改15%-30%的代码。
**注:华为已启动"昇腾万里伙伴计划",计划3年内投入10亿资金完善生态,目前已有500+ISV加入合作。
国产AI的未来,不在远方,就在我们每一次敲下的代码里。
给想入门昇腾的同学几点建议:
1. 从 [MindSpore 官网](https://www.mindspore.cn) 开始,跑通第一个 “Hello World” 模型;
> 2. 关注华为昇腾社区和 CSDN 上的实战教程;
> 3. 别怕“底层”,理解 CANN 和 ACL 会让你对 AI 系统有更深认知;
> 4. 加入高校昇腾俱乐部或开发者大赛,实践出真知。
国产替代不是口号,而是一代人接一代人的接力。而我们,正站在起跑线上。
结语**
昇腾作为华为全栈AI战略的核心组成部分,其发展历程生动展现了中国半导体产业突破技术封锁的艰辛历程。2018年10月,在华为全联接大会上首次亮相的昇腾310芯片采用台积电12nm FinFET工艺制程,算力达到16TOPS(INT8),功耗仅8W,主要面向边缘计算场景。2022年发布的昇腾910B则升级至7nm EUV先进制程,集成高达256个达芬奇AI核心,FP16算力达到256TFLOPS,相较前代性能提升2.3倍,功耗控制在310W以内。这一跨越式发展背后,是华为2012实验室下属的诺亚方舟实验室与海思半导体超过2000名研发人员历时5年、投入超100亿研发经费的持续攻坚。
在软件生态构建方面,CANN(Compute Architecture for Neural Networks)异构计算架构已迭代至6.0版本,不仅支持TensorFlow、PyTorch等主流框架的模型一键迁移,还通过AscendCL编程接口提供2000+优化算子库。开源深度学习框架MindSpore经过三年发展,其开发者社区已汇聚超50万注册会员,在医疗影像分析(如武汉同济医院的CT影像智能诊断系统)、智慧城市(深圳龙岗区的交通流量预测平台)等20多个行业落地3000+实际应用案例。
特别值得注意的是,昇腾产业生态通过"鲲鹏+昇腾"双引擎战略,已吸引包括寒武纪(提供AI编译器技术支持)、云天励飞(联合开发安防解决方案)在内的328家企业加入昇腾伙伴计划,形成覆盖芯片设计(如芯原微电子)、整机集成(神州数码)、系统软件(统信UOS)、行业应用(东华软件)的完整产业链。在江苏无锡的昇腾AI计算中心,部署的Atlas 900集群由数千颗昇腾910处理器组成,在ResNet-50模型训练任务中达到每分钟处理6000张图片的吞吐量,经MLPerf基准测试认证达到国际领先水平。
这些突破性进展印证了华为轮值董事长徐直军提出的"硬件开放、软件开源、使能伙伴"战略成效。通过构建"芯片+框架+平台+生态"的协同创新模式,中国AI计算平台在推理芯片能效比(昇腾310达到2TOPS/W)、训练集群规模(Atlas 900支持4096颗芯片互联)等关键指标上,正逐步缩小与国际巨头的差距,实现从技术跟跑到并跑的历史性跨越。当前,昇腾系列产品已广泛应用于金融(中国建设银行智能风控)、能源(国家电网设备巡检)等关键领域,支撑着中国数字经济2.8%的年度增长贡献率。
对于开发者而言,掌握昇腾开发技能不仅是技术储备,更是参与国家科技自主创新的切实行动。希望本文能为你打开昇腾世界的大门,欢迎在评论区交流实践经验!
2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接:https://www.hiascend.com/developer/activities/cann20252

















 3260
3260

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









