






并行智算云平台介绍
并行智算云(ai.paratera.com)是由北京并行科技股份有限公司推出的面向人工智能(AI)与高性能计算(HPC)场景的GPU算力服务平台,主要服务于高校、科研院所、企事业单位,提供灵活、高效、专业的GPU算力资源,支持大规模AI训练、推理及科学计算任务。
一、使用前准备
-
注册与登录:访问并行智算云官网,完成注册并登录。
-
了解计费方式:并行智算云有多种计费方式,如按使用时长计费、按计算资源用量计费等。在使用前需了解计费规则,以便合理规划资源使用。
-
熟悉控制台界面:
-
资源管理模块:可查看和管理计算资源,如虚拟机实例、GPU资源等。
-
任务管理模块:用于提交、监控和管理计算任务。
-
数据存储模块:提供云存储服务,用于存储数据和代码。
-
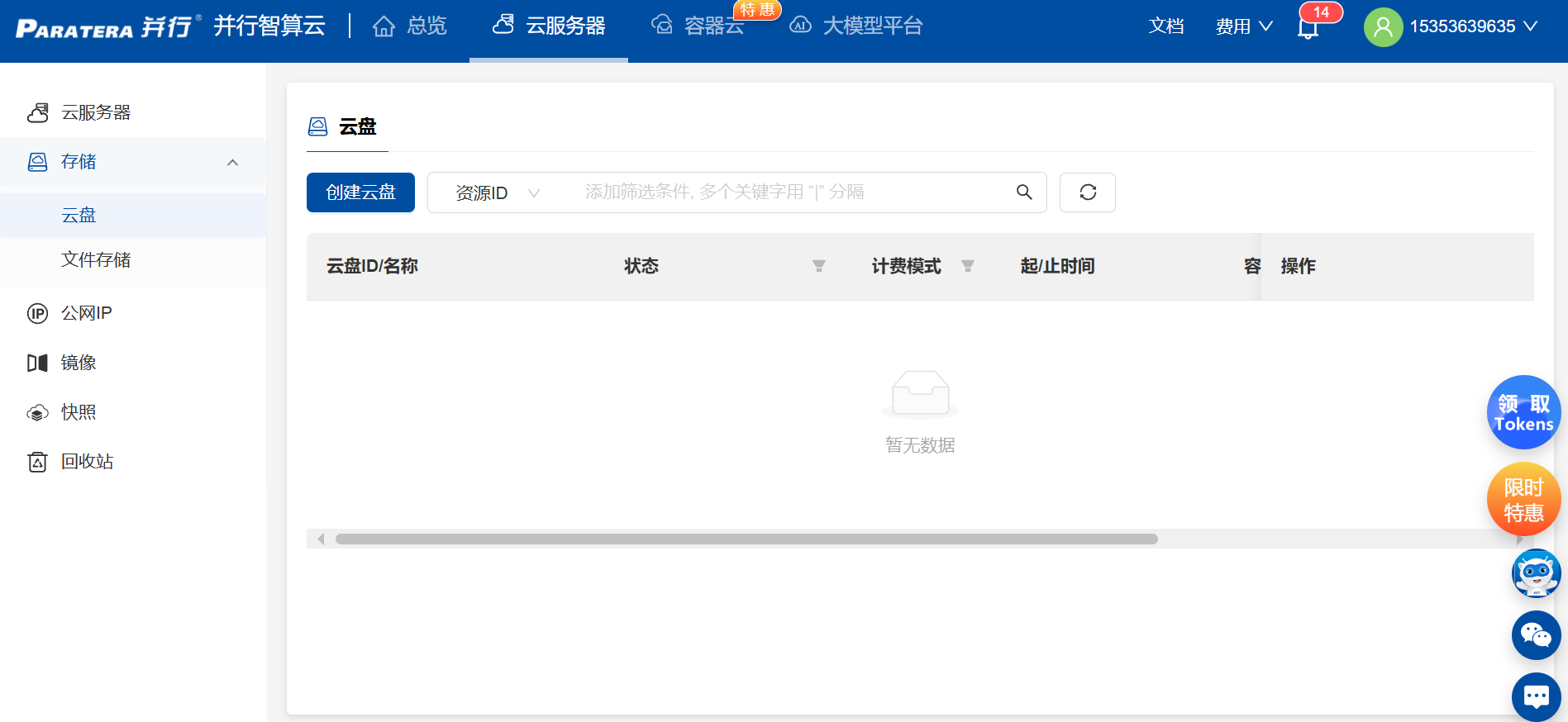
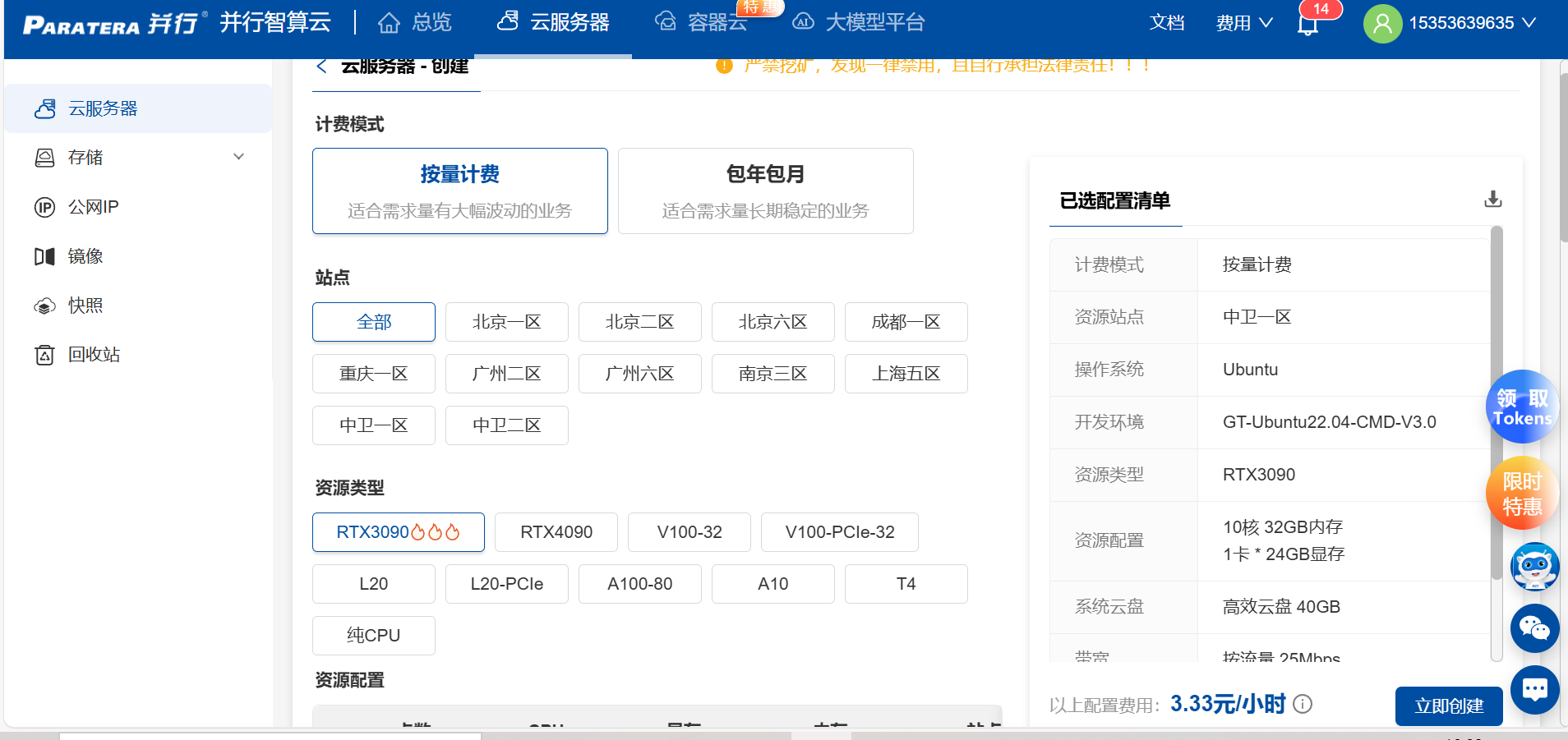
二、创建计算资源
-
进入“算力市场”,选择适合的GPU机型,如A100/V100。
-
根据模型大小调整显存和计算节点数量,小模型可用单卡,大模型可多卡并行。
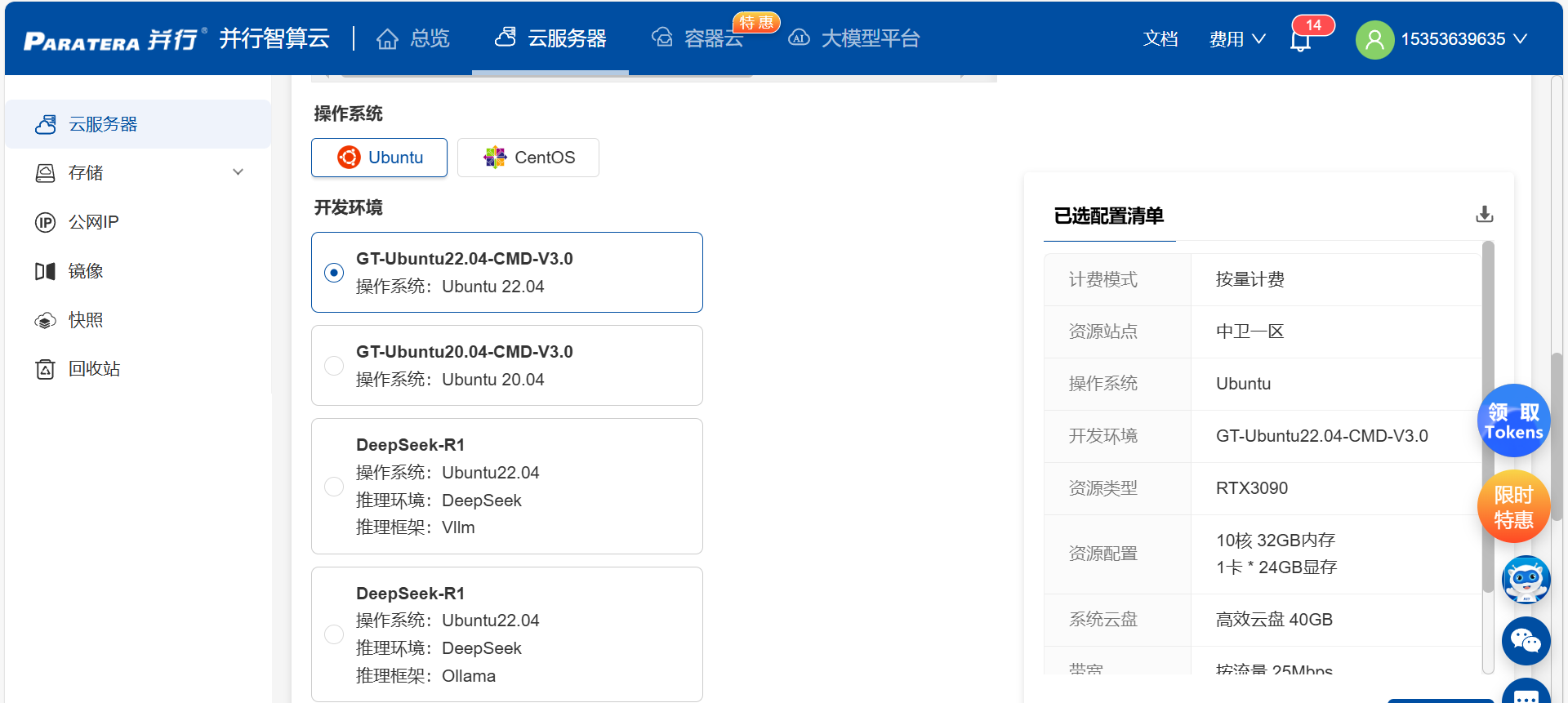
三、配置开发环境
-
平台支持JupyterLab/VS Code Remote,预装主流AI框架(PyTorch、TensorFlow)。
-
也可通过SSH连接服务器,进行自定义环境配置。
四、上传数据集与训练代码
-
上传数据:
-
支持本地文件上传或挂载云端存储(如AWS S3、阿里云OSS)。
-
示例(使用命令行上传):
复制
curl -X POST "https://api.paratera.com/upload" -F "file=@dataset.zip" -
-
准备训练脚本:
-
示例(PyTorch训练MNIST手写数字识别):
复制
import torch import torch.nn as nn import torch.optim as optim from torchvision import datasets, transforms # 数据加载 transform = transforms.Compose([transforms.ToTensor()]) train_data = datasets.MNIST('./data', train=True, download=True, transform=transform) train_loader = torch.utils.data.DataLoader(train_data, batch_size=64, shuffle=True) # 定义模型 model = nn.Sequential( nn.Linear(784, 128), nn.ReLU(), nn.Linear(128, 10) ) # 训练 optimizer = optim.Adam(model.parameters(), lr=0.001) criterion = nn.CrossEntropyLoss() for epoch in range(10): for batch_idx, (data, target) in enumerate(train_loader): data = data.view(data.shape[0], -1) # 展平输入 optimizer.zero_grad() output = model(data) loss = criterion(output, target) loss.backward() optimizer.step() print(f"Epoch {epoch}, Loss: {loss.item()}")-
保存为
train.py,上传至平台。
-
五、启动训练任务
-
进入“任务管理”,点击“新建训练任务”。
-
选择计算资源(如1×A100)。
-
设置启动命令(示例):
bash复制
python train.py -
点击“提交”,任务开始执行,GPU资源自动分配。
六、监控训练与下载模型
-
实时日志:在任务面板查看训练进度。
-
资源监控:观察GPU利用率、显存占用。
-
模型保存:训练完成后,模型自动存储至云端模型仓库,可下载或部署为API。
七、进阶功能
-
多机多卡训练(PyTorch DDP):
Python复制
import torch.distributed as dist dist.init_process_group(backend='nccl') # 初始化多卡通信 model = nn.parallel.DistributedDataParallel(model)-
提交任务时选择多节点GPU(如4×A100)。
-
-
自动超参优化(Optuna + MaaS):
Python复制
import optuna def objective(trial): lr = trial.suggest_float("lr", 1e-5, 1e-2, log=True) optimizer = optim.Adam(model.parameters(), lr=lr) # ...训练代码... return loss study = optuna.create_study(direction="minimize") study.optimize(objective, n_trials=20)-
并行智算云支持超参搜索任务,自动寻找最佳参数组合。
-
八、性能优化
-
合理配置计算资源:
-
根据任务类型选择合适的CPU和GPU搭配。
-
动态调整资源,根据资源使用情况优化分配。
-
-
优化代码性能:
-
合理使用分布式训练技术,如PyTorch的
torch.distributed。 -
优化数据加载和预处理流程,使用高效的数据加载库,如DALI。
-
九、成本优化
-
使用Spot实例:抢占式GPU,价格更低,适合非紧急任务。
-
监控Tokens消耗:在控制台查看算力使用情况,避免超额。
-
早鸟优惠:新用户注册再领额外Tokens。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









