






在深度学习和自然语言处理(NLP)领域,Transformer 架构已经成为主流模型的核心组件。其中,Scaled Dot-Product Attention 和 Multi-Head Attention(MHA) 是 Transformer 的核心机制之一。本文将从零开始,手写实现这两个关键模块,并深入讲解其原理和实现细节。
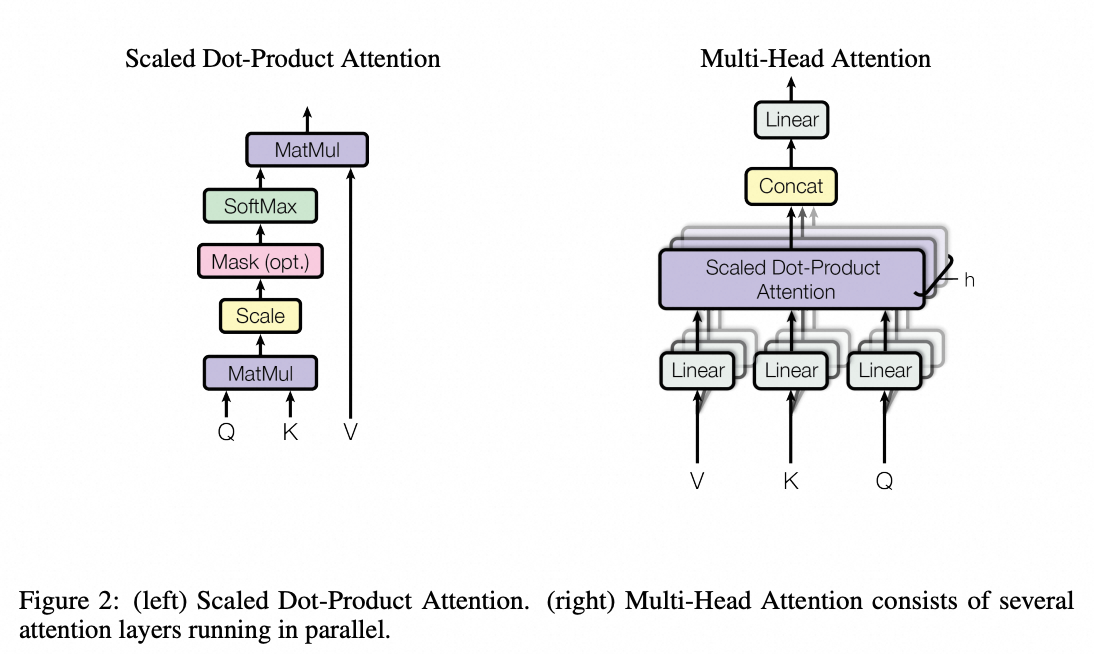
一、Scaled Dot-Product Attention
1.1 原理回顾
Scaled Dot-Product Attention 是注意力机制中最基本的形式,缩放点积注意力,其公式如下:
其中:
-
Q :Query 向量
-
K :Key 向量
-
V :Value 向量
-
:Key 向量的维度
-
缩放因子
是为了防止内积过大导致 softmax 梯度消失
此外,我们还可以通过 mask 来屏蔽无效位置(如 padding 或未来信息),在 softmax 前将无效位置的值设为极小值(如 -1e9)。
1.2 PyTorch 实现
import torch
import torch.nn as nn
# 设置随机种子(固定随机性)
torch.manual_seed(42)
class ScaledDotProductAttention(nn.Module):
def __init__(self, d_k, dropout=None):
super().__init__()
self.scale = d_k
self.softmax = nn.Softmax(dim=2)
# 修改:如果 dropout=None,则使用 nn.Identity() 代替
self.dropout = nn.Dropout(dropout) if dropout is not None else nn.Identity()
def forward(self,q,k,v,mask):
# q: (batch, n_head, seq_len_q, d_k)
# k: (batch, n_head, seq_len_k, d_k)
# v: (batch, n_head, seq_len_v, d_v)
# mask: (batch, n_head, seq_len_q, seq_len_k)
u = torch.matmul(q,k.transpose(-2,-1))/self.scale
# 应用 mask(如果存在)
if mask is not None:
u = u.masked_fill(mask,-1e9)
# softmax 归一化
att_weight = self.softmax(u)
# 应用 dropout(如果存在)
att_weight = self.dropout(att_weight)
output = torch.matmul(att_weight, v)
return att_weight,output1.3 使用示例
batch=1
n_head = 2
n_q, n_k, n_v = 2, 4, 4
d_q, d_k, d_v = 8, 8, 64
q=torch.randn(batch,n_head,n_q,d_q)
k=torch.randn(batch,n_head,n_k,d_k)
v=torch.randn(batch,n_head,n_v,d_v)
mask= torch.zeros(batch,n_head,n_q,n_k).bool()
attention = ScaledDotProductAttention(d_k** 0.5)
attn_weights,output = attention(q,k,v,mask)
print("Output shape:", output.shape)
print("Attention weights shape:", attn_weights.shape)
二、Multi-Head Attention(MHA)
2.1 原理回顾
Multi-Head Attention 的核心思想是将 Q/K/V 投影到多个不同的表示空间中,分别进行注意力计算,再将结果拼接并通过一个线性变换输出最终结果。
其结构如下:
-
通过线性层将输入 Q/K/V 投影到
维度
-
将每个头的 Q/K/V 拆分成多个头(head)
-
对每个头分别调用 Scaled Dot-Product Attention
-
拼接所有头的输出,再通过一个线性层输出最终结果
2.2 PyTorch 实现
class MultiHeadAttention(nn.Module):
def __init__(self, input_dim, n_head, d_model):
super().__init__()
self.n_head = n_head
self.d_model = d_model
self.d_k = d_model // n_head
# 线性投影层
self.linear_q = nn.Linear(input_dim, d_model)
self.linear_k = nn.Linear(input_dim, d_model)
self.linear_v = nn.Linear(input_dim, d_model)
# 注意力机制
self.attention = ScaledDotProductAttention(scale=self.d_k**0.5)
# 输出线性层
self.linear_out = nn.Linear(d_model, d_model)
def forward(self, x, mask=None):
batch_size, seq_len, _ = x.size()
# 线性变换
q = self.linear_q(x) # (batch, seq_len, d_model)
k = self.linear_k(x)
v = self.linear_v(x)
# 拆分成多个头
q = q.view(batch_size, seq_len, self.n_head, self.d_k).permute(0, 2, 1, 3)
k = k.view(batch_size, seq_len, self.n_head, self.d_k).permute(0, 2, 1, 3)
v = v.view(batch_size, seq_len, self.n_head, self.d_k).permute(0, 2, 1, 3)
# 添加 mask 维度
if mask is not None:
mask = mask.unsqueeze(1) # (batch, 1, seq_len_q, seq_len_k)
# 多头注意力计算
attn_weights, output = self.attention(q, k, v, mask)
# 合并多个头
output = output.permute(0, 2, 1, 3).contiguous()
output = output.view(batch_size, seq_len, self.d_model)
# 最终线性层
output = self.linear_out(output)
return output, attn_weights
2.3 使用示例
import torch
# 设置参数
batch_size = 2
seq_len = 10
input_dim = 512
n_head = 8
d_model = 512
# 构建输入
x = torch.randn(batch_size, seq_len, input_dim)
mask = torch.zeros(batch_size, seq_len, seq_len).bool()
# 实例化 MHA
mha = MultiHeadAttention(input_dim, n_head, d_model)
# 前向传播
output, attn_weights = mha(x, mask)
print("Output shape:", output.shape) # (2, 10, 512)
print("Attention weights shape:", attn_weights.shape) # (2, 8, 10, 10)
三、关键点总结
| 模块 | 关键点 |
| Scaled Dot-Product Attention | 缩放因子为 \sqrt{d_k} ,mask 使用 |
| Multi-Head Attention | 拆头使用 |
| 模型结构设计 |
|
| 性能优化建议 | 使用 |
四、附加挑战建议(进阶)
-
支持双向/单向 mask:
-
编码器中使用 padding mask
-
解码器中使用 future mask(防止看到未来信息)
-
-
数值稳定性:在 softmax 前做
x - x.max()操作,防止数值溢出。 -
实现GQA和kv cache版本


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









