



目录
3.1 Masked Language Model(MLM)
3.2 Next Sentence Prediction(NSP)
4.2 单词分类(Token Classification)
一、BERT 简介
BERT 是 Google 在 2018 年提出的预训练语言模型,其全称是 Bidirectional Encoder Representations from Transformers。它是首个真正意义上的 双向语言模型,能够同时利用一个词的左右上下文来理解其含义。
核心设计理念:
-
基于 Transformer 编码器构建,encoder-only
-
使用 掩码语言模型(Masked Language Model, MLM) 进行训练;
-
引入 下一句预测(Next Sentence Prediction, NSP) 任务,以增强句子间关系的理解;
-
强大的迁移学习能力
-
强大的迁移学习能力,可通过微调(fine-tuning)适配多种下游任务。
BERT 的提出标志着语言模型进入了“预训练 + 微调”的新时代。
二、NLP的发展历程
2.1 One-Hot 编码
早期的 NLP 中,One-Hot 编码是最简单的词表示方法。每个词被表示为一个长度等于词汇表大小的向量,其中只有对应位置为 1,其余为 0。
局限性:
-
无法计算词相似度:One-Hot 向量之间都是正交的,因此不能反映词语之间的语义相似性。
-
Sparsity(稀疏性):由于维度高且只有一个位置有值,导致存储和计算效率低下。
2.2 Word2vec
Word2vec 是由 Google 提出的一种词嵌入技术,它将词语映射到低维稠密向量空间中,从而能够表达词语之间的语义关系。
主要优点:
-
能够捕捉词与词之间的语义和语法关系;
-
支持类比推理(如 king - man + woman ≈ queen);
-
向量稠密,便于后续模型处理。
尽管 Word2vec 是一项重大进步,但它仍是 静态词向量,即同一个词在不同上下文中具有相同的向量表示,无法解决一词多义问题。
2.3 BERT 的诞生
BERT 的诞生解决了传统词向量的局限性,它引入了 上下文感知的动态词向量表示。通过使用 Transformer 编码器结构和大规模无监督预训练,BERT 能够根据上下文动态地调整词的表示。
三、BERT 的训练过程
BERT 的训练主要包括两个任务:掩码语言模型(MLM) 和 下一句预测(NSP)。
3.1 Masked Language Model(MLM)
在 MLM 中,BERT 随机遮盖输入文本中约 15% 的词,并尝试根据上下文预测这些被遮盖的词。
实现细节:
-
80% 的被遮盖词用
[MASK]替代; -
10% 的词用随机词替代;
-
10% 的词保持不变(防止模型过于依赖
[MASK]); -
最终目标是最大化被遮盖词的预测准确率。
MLM 的设计使得 BERT 能够更准确地理解词语的上下文含义。
3.2 Next Sentence Prediction(NSP)
为了增强 BERT 对句子间关系的理解,作者引入了 NSP 任务。该任务的目标是判断两个句子 A 和 B 是否构成连贯的一段话。
训练方式:
-
50% 的样本中,B 是 A 的下一句;
-
50% 的样本中,B 是随机选取的其他句子;
-
模型最终输出这两个句子是否连续的概率。
NSP 任务帮助 BERT 更好地理解句子之间的逻辑关系,对于问答、自然语言推理等任务尤为重要。
四、BERT 的用途
BERT 凭借其强大的语言理解能力,已被广泛应用于多个下游 NLP 任务中。
4.1 文本分类
BERT 可用于情感分析、新闻分类、垃圾邮件检测等任务。通常做法是:
-
在
[CLS]标记对应的隐藏状态上接一个分类层; -
使用 softmax 或 sigmoid 进行分类;
-
微调整个模型以适配特定任务。
例如,在 IMDb 数据集上,BERT 能轻松达到 90% 以上的准确率
4.2 单词分类(Token Classification)
BERT 也适用于命名实体识别(NER)、词性标注(POS tagging)等单词级别的分类任务。
方法:
-
每个 token 的隐藏状态直接用于分类;
-
不再只依赖
[CLS]的全局表示; -
输出每个 token 的标签(如 PER、LOC、ORG 等);
BERT 的上下文敏感表示使其在这些任务中表现优异。
4.3 判断两个句子之间的关系
BERT 擅长理解句子之间的关系,可用于自然语言推理(NLI)、文本蕴含(Textual Entailment)等任务。
方法:
-
输入两个句子,分别加上特殊标记
[SEP]分隔; -
使用
[CLS]的输出作为句子对的整体表示; -
接一个分类层判断它们的关系(如矛盾、中立、蕴含)。
4.4 QA(问答系统)
BERT 在问答系统中也有出色表现,特别是在 SQuAD 等阅读理解数据集上取得了突破性成绩。
工作流程:
-
输入包含问题和文档的拼接文本;
-
模型输出两个位置:答案的开始和结束位置;
-
通过 Softmax 分别预测 start 和 end 的索引;
-
最终提取出答案片段。
BERT 的这种灵活结构使其非常适合端到端的问答任务。
五、BERT文本分类实战
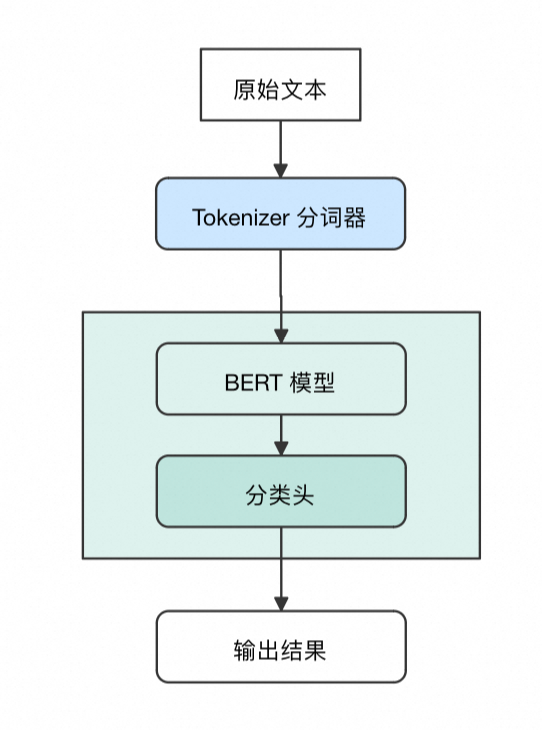
流程:原始文本--》BERT Tokenizer分词器--》BERT Model +分类头 --》分类
1、环境安装
因为本地配置环境麻烦,所以笔者直接使用kaggle资源,创建notebook跑线上。
在notebooke中,安装必要依赖
!pip install datasets transformers2、数据集处理
# 导入必要的库
from transformers import AutoTokenizer, AutoModelForSequenceClassification
from datasets import load_dataset
# 定义数据集名称和任务类型
dataset_name = "imdb"
# 下载数据集并打乱数据
dataset = load_dataset(dataset_name)
dataset = dataset.shuffle()
input = dataset["train"]["text"][:10]-
load_dataset函数
-
输入参数huggingface中数据集名字,输出为导入的数据集对象,key是数据集的子项、对应列的数组。比如数据集imdb:数据集分成三部分。此处引用的是"train"部分,列"text",返回前10项
-
-
shuffle函数
-
打乱数据集中元素顺序,防止返回的前10项数据label都是一样的
-
3、分词器解析
# 初始化分词器和模型
model_name = "bert-base-cased"
tokenizer = AutoTokenizer.from_pretrained(model_name)
# 将文本编码为模型期望的张量格式
inputs = tokenizer(input, padding=True, truncation=True, return_tensors="pt")-
AutoTokenizer作用
-
AutoTokenizer是 Hugging Face 提供的一个自动选择合适分词器的类。它可以根据模型名称(如"bert-base-cased")自动加载对应的 tokenizer。也就是说,不需要手动判断应该使用哪种分词器(比如BertTokenizer,RobertaTokenizer等),只要用AutoTokenizer.from_pretrained(...),它会根据预训练模型的配置自动匹配合适的分词器。
-
-
tokenizer函数使用
-
原始文本 → WordPiece 分词 → 添加特殊标记 → 编码为 ID → 填充/截断
-
输入参数:
-
| 参数 | 含义 |
|
| 要编码的文本,可以是一个字符串或者字符串列表 |
|
| 自动将文本填充到统一长度 |
|
| 如果文本太长,会被截断 |
|
| 返回 PyTorch 张量("pt" 表示 PyTorch,也可以是 "tf" 表示 TensorFlow) |
-
输出内容:
返回的是一个 BatchEncoding 对象,本质是一个字典,包含以下常用 key
| key | value | 含义 |
|
|
| 每个 token 被转换成对应的 ID(基于模型词汇表) |
|
|
| 表示哪些 token 是真实内容,哪些是 padding(1 表示有效,0 表示 padding) |
|
| 无 (可选,可能有/没有) | 区分句子对中的第一个句子和第二个句子(如在问答任务中) |
一个🌰例子
输入两条用户评价input= ["电影好看","不喜欢这电影"];我们来一步一步地分析:句子1:"电影好看"句子2:"不喜欢这电影",使用 BERT 的中文 tokenizer(如 bert-base-chinese) 来对它们进行编码,得到 input_ids 和 attention_mask。
第一步:Tokenization 切割
1. "电影好看" 分词为:"电"、"影"、"好"、"看" (BERT 的 tokenizer 是基于字的)
加上 [CLS] 和 [SEP] 标记后变成:[CLS] 电 影 好 看 [SEP],长度是 6。
2. "不喜欢这电影" 分词为:"不"、"喜"、"欢"、"这"、"电"、"影"
加上 [CLS] 和 [SEP] 后变成:[CLS] 不 喜 欢 这 电 影 [SEP],长度是 8。
第二步:填充后统一长度(padding=True)
所以会统一填充到最大长度 8。
第三步:输出结果
input_ids:
[
[ 101, 7289, 4638, 2199, 1158, 102, 0, 0], # "电影好看"
[ 101, 176, 2115, 2769, 1755, 7289, 4638, 102] # "不喜欢这电影"
]attention_mask:
[
[1, 1, 1, 1, 1, 1, 0, 0], # 对应第一个句子的有效位置
[1, 1, 1, 1, 1, 1, 1, 1] # 所有位置都有效
]4、加载模型
# 初始化分词器和模型
model_name = "bert-base-cased"
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=2)注意此处用的是:bert模型+分类头,num_labels=2,所以是二分类
模型结构概览
# 调用print model可以打印出模型结构
print(model)| 组件 | 参数规模 | 作用 |
| Token Embeddings | 512-dim | 词向量+位置向量+句子类型向量 |
| Transformer Encoder | 12层 | 自注意力机制提取上下文特征 |
| Pooler Layer | 768-dim |
|
# 打印模型参数的名字和是否需要梯度
for name, param in model.named_parameters():
print(f"{name}: requires_grad={param.requires_grad}")分类头机制
class BERTForClassification(nn.Module):
def __init__(self, num_labels=2):
self.classifier = nn.Linear(768, num_labels)
注意AutoModelForSequenceClassification在bert模型下面接了一个SequenceClassification分类头,bert中的参数采用和预训练一致,分类头的参数完全是全新的,新随机初始化的
5、模型预测
# 将编码后的张量输入模型进行预测
outputs = model(**inputs)模型输入输出
# 输入格式
{
"input_ids": tensor([[101, 2345, ..., 102]]),
"attention_mask": tensor([[1, 1, ..., 1]]),
"token_type_ids": tensor([[0, 0, ..., 0]]) # 可选
}
# 输出格式
{
"logits": tensor([[2.3, -1.1]]), # [正面得分, 负面得分]
"hidden_states": tuple(...), # 各层隐藏状态
"attentions": tuple(...) # 注意力权重矩阵
}6、输出解析
# 获取预测结果和标签
predictions = outputs.logits.argmax(dim=-1)
labels = dataset["train"]["label"][:10]
# 打印预测结果和标签
for i, (prediction, label) in enumerate(zip(predictions, labels)):
prediction_label = "正面评论" if prediction == 1 else "负面评论"
true_label = "正面评论" if label == 1 else "负面评论"
print(f"Example {i+1}: Prediction: {prediction_label}, True label: {true_label}")-
logits:未归一化的预测分数。模型直接输出的向量,还未进行softmax或者sigmoid
-
argmax是求数组中最大值的下标
{
'logits': tensor([[2.3, -1.1], # 样本1:正面概率更高
[-0.5, 3.2]]) # 样本2:负面概率更高
}
最后输出

7、总体代码
# 导入必要的库
from transformers import AutoTokenizer, AutoModelForSequenceClassification
from datasets import load_dataset
# 定义数据集名称和任务类型
dataset_name = "imdb"
# 下载数据集并打乱数据
dataset = load_dataset(dataset_name)
dataset = dataset.shuffle()
# 初始化分词器和模型
model_name = "bert-base-cased"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=2)
# 将文本编码为模型期望的张量格式
inputs = tokenizer(dataset["train"]["text"][:10], padding=True, truncation=True, return_tensors="pt")
# 将编码后的张量输入模型进行预测
outputs = model(**inputs)
# 获取预测结果和标签
predictions = outputs.logits.argmax(dim=-1)
labels = dataset["train"]["label"][:10]
# 打印预测结果和标签
for i, (prediction, label) in enumerate(zip(predictions, labels)):
prediction_label = "正面评论" if prediction == 1 else "负面评论"
true_label = "正面评论" if label == 1 else "负面评论"
print(f"Example {i+1}: Prediction: {prediction_label}, True label: {true_label}")完整技术栈
五、分类实战总结
直接用bert模型进行分类,准确率待提升
因为是bert模型直接接分类头,分类头的参数完全随机初始化,没有被影评数据集微调过,所以结果并不好,需要对分类头、甚至bert模型进行微调。
在实际公司的应用中,我们也会根据业务需要,使用业务数据集对bert进行微调
下一篇文章将具体讲解如何微调bert,来提高它在文本分类任务上的准确率

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









