






在自然语言处理(NLP)中,Transformer的decoder并不直接输出单词,通常使用Softmax函数来生成下一个词在词表中的概率分布。
Temperature作为超参数,通过影响Softmax函数的输出分布,从而影响生成文本的多样性和确定性。本文将探讨温度参数如何通过调整Softmax函数的输出分布、如何与不同采样策略结合,进而影响模型生成文本的特性。
目录
3. 不同策略影响Top-K、Top-P和Beam Search
1. Softmax函数在Decoder中的位置
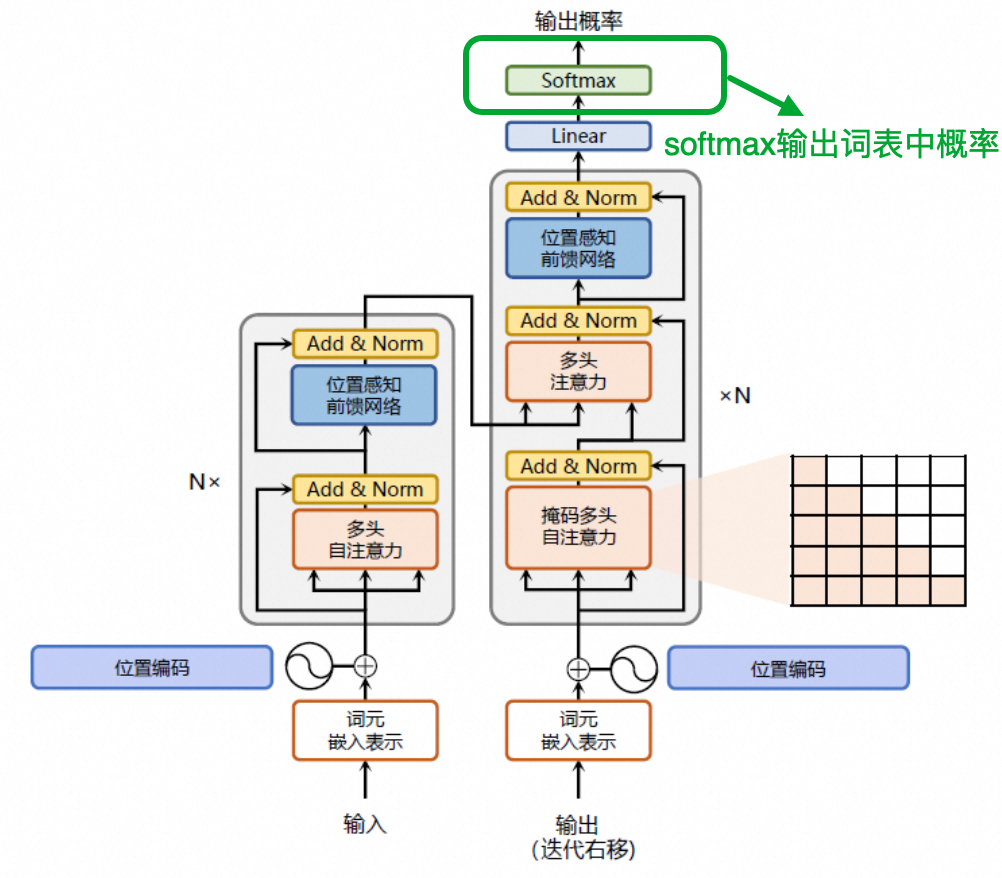
在Transformer模型的解码过程中,模型通过自注意力机制逐步生成目标序列。每一步解码都会输出一个词的logits(未归一化的分数),然后通过Softmax函数将其转化为概率分布,用于选择下一个词。
具体流程如下:
-
Decoder输出一个向量,表示当前时刻对每个词的偏好程度(logits)。
-
使用Softmax函数将logits转化为一个概率分布:
其中, T 就是温度参数
3 .根据这个概率分布,使用采样策略(如贪婪搜索、Top-K采样等)选择下一个词。
因此,Softmax函数在模型中起到了“归一化输出”和“控制选择偏好”的双重作用,而温度参数则是调节这种偏好的关键。
2. 温度如何改变Softmax函数输出
温度参数(Temperature)是一个标量,通常用T 表示。它通过调整Softmax函数的输入logits来改变输出分布的形状。引入温度参数后的Softmax函数公式如下:
温度参数 T 的作用如下:
-
当 T > 1 时,Softmax函数的输出分布变得更加平滑,概率分布中的差异减小。这意味着模型生成文本时,更倾向于选择概率较低但多样的词汇,从而增加文本的多样性。
-
当 T < 1 时,Softmax函数的输出分布变得更加尖锐,概率分布中的差异增大。这意味着模型生成文本时,更倾向于选择概率最高的词汇,从而增加文本的确定性。
例子
假设模型输出的logits为 [2.0, 1.0, 0.5] ,词汇表大小为3。我们分别计算 T = 1 、 T = 0.5 和 T = 2 时的概率分布。

代码示例
以下是一个简单的代码示例,展示温度参数如何影响生成结果:
import torch
import torch.nn.functional as F
# 假设模型的原始输出(logits)
logits = torch.tensor([[1.0, 2.0, 3.0]])
def generate_text(logits, temperature=1.0):
# 应用温度参数
logits = logits / temperature
# 计算概率分布
probs = F.softmax(logits, dim=-1)
# 从概率分布中采样
next_token = torch.multinomial(probs, num_samples=1)
return next_token.item()
# 低温(确定性高)
print("低温 (T=0.1):", generate_text(logits, temperature=0.1)) # 总是选择概率最高的词
# 默认温度
print("默认温度 (T=1.0):", generate_text(logits, temperature=1.0)) # 按原始概率分布采样
# 高温(多样性高)
print("高温 (T=2.0):", generate_text(logits, temperature=2.0)) # 更有可能选择低概率词3. 不同采样策略影响:Top-K、Top-P和Beam Search
温度参数不仅影响Softmax函数的输出分布,还与其他生成策略如Top-K、Top-P和Beam Search相互作用,进一步影响生成文本的特性。
1. 贪婪搜索(Greedy Search)
-
机制:每一步只选择概率最高的词。
-
温度影响:Temperature变化对贪婪搜索影响较小,因为无论分布如何,模型始终选择最大概率的词。
-
结论:Temperature在此策略下作用有限,生成结果最确定但最缺乏多样性。
2. 采样(Sampling)
-
机制:根据Softmax输出的概率分布进行采样。
-
采样是什么:参考[特殊字符]LLM中随机采样真的是“瞎选”吗-CSDN博客)
-
-
温度影响:
-
低温度(<1):采样集中在高概率词,生成更保守。
-
高温度(>1):采样分布更均匀,生成更随机、更创新。
-
-
结论:温度是调节采样策略多样性的重要参数,适合用于需要创造性输出的场景(如写故事、诗歌)。
3. 🚩Top-K 采样(常用)
-
机制:Top-K策略在每个时间步只保留概率最高的K个词,然后从这K个词中随机选择下一个词。温度参数通过调整Softmax函数的输出分布,间接影响Top-K策略的选择。当 T 较大时,概率分布平滑,Top-K策略可能选择更多样的词;当 T 较小时,概率分布尖锐,Top-K策略更倾向于选择概率最高的词。
-
温度影响:
-
高温度:Top-K范围内分布更均匀,增加多样性。
-
低温度:Top-K中高概率词被选中概率更高,生成更确定。
-
-
结论:温度与K值共同控制生成的多样性与合理性,适合在质量和多样性之间取得平衡。
4. 🚩Top-P(Nucleus)采样(常用)
-
机制:选择累计概率超过阈值P的最小词集进行采样。
-
温度影响:
-
高温度:Top-P集合中各词概率更接近,采样更随机。
-
低温度:集合中某个词可能占主导,生成更稳定。
-
-
结论:Top-P对温度敏感,能自适应词表分布,是目前广泛使用的生成策略之一。
5. Beam Search(束搜索)
-
机制:保留多个候选序列,每一步扩展并保留最优的K个路径。
-
温度影响:
-
通常不直接应用温度参数,因为Beam Search基于确定性策略,基于排序
-
但在一些变体中(如Soft Beam Search),温度可被引入以增加路径多样性。
-
-
结论:温度对标准Beam Search影响有限,但可作为增强多样性的辅助手段。
4 总结
温度参数是控制文本生成过程中确定性与多样性之间平衡的重要工具。它通过调节Softmax函数输出的概率分布,影响模型在不同解码策略下的输出行为:
对贪婪算法、beam search更更注重概率之间排序这类算法影响不大,但是对随机采样、topK、topP这类按照概率的采样算法影响较大
选择策略
-
低温度:生成更确定、更保守,适合任务导向型场景(如问答、摘要)。
-
高温度:生成更随机、更具创造性,适合创意写作、对话生成等任务。
-
结合不同策略:温度与Top-K、Top-P等策略结合使用,可以在生成质量与多样性之间取得良好平衡。
通过合理使用温度参数,我们可以更好地掌控模型生成文本的风格与质量,从而更好地服务于不同的应用场景。
延伸问题:为什么使用大模型时候,相同的输入可能有不同输出
大模型在生成文本时,通常会基于概率分布选择下一个词。这种概率分布是通过 Softmax 函数对模型的输出进行归一化得到的。因此,生成过程本身是 随机的,具体体现在以下几个方面:
采样方法(Sampling)
-
在生成文本时,模型可以通过 采样 的方式选择下一个词。例如,从概率分布中随机选择一个词,而不是总是选择概率最高的词。这种随机性会导致相同的输入产生不同的输出。(Temperature会改变概率分布平滑还是尖锐,从而改变低频次出现概率)
Beam Search 的随机
-
即使使用 Beam Search(一种贪婪搜索算法),如果设置了
num_beams > 1,模型也会探索多个候选序列,这可能导致不同的输出。
Dropout 和随机初始化
-
在训练和推理时,Dropout 和随机初始化也会引入一定的随机性。

















 274
274

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









