










什么是X2Knowledge?
X2Knowledge 是一个高效的开源知识提取器工具,专为企业知识库建设而设计。它支持将PDF、Word、PPT、Excel、WAV、MP3等多种格式的文件智能转换为结构化的TXT或Markdown格式,帮助用户快速将各类文档资料标准化地录入企业知识库系统。通过先进的格式解析和内容提取技术,该项目显著提升知识转换的效率和准确性,是RAG(检索增强生成)应用和企业知识管理的理想预处理工具。
这是一个基于Python Flask的Web应用,可以将各种文档格式(Word、Excel、PowerPoint、PDF、TXT和Markdown)转换为纯文本或结构化的Markdown。
最新更新 (v0.2.1)
- 优化Markdown预览功能:使用marked.js库提供更完善的Markdown渲染,完美支持表格和图片
- 添加图片交互:支持点击图片放大查看
- 增加代码高亮:使用highlight.js提供代码语法高亮
- 增加Docker部署支持:添加Dockerfile和docker-compose配置
- 修复了API文档问题:改进了API文档的Markdown标签切换
功能特点
-
将多种文件格式转换为文本或Markdown
- 支持Word (.doc, .docx)、Excel (.xls, .xlsx)、PowerPoint (.ppt, .pptx)、PDF、文本文件等
- 在Markdown转换模式下保持文档结构
- 通过OCR从图像中提取文本
-
Markdown转换
- 保留文档结构,包括标题、列表和表格
- 保持链接和格式
- 提供转换后的Markdown预览功能
-
OCR支持
- 自动从文档中嵌入的图像提取文本
- 适用于Word、PowerPoint和PDF文件中的图像
-
音频转换 (新功能)
- 将音频文件(.mp3, .wav)转换为文本/Markdown描述
- 提取元数据,包括时长、声道和采样率
-
UTF-8编码
- 自动将文档转换为UTF-8编码
- 解决中文字符显示问题
- 无需手动配置编码
-
大文件支持
- 支持高达50MB的文件
- 高效处理大型文档
使用方法
- 选择转换模式(文本或Markdown)
- 上传您的文档(或拖放)
- 查看、复制或下载转换结果
- 使用Markdown预览功能查看格式化结果(使用Markdown模式时)
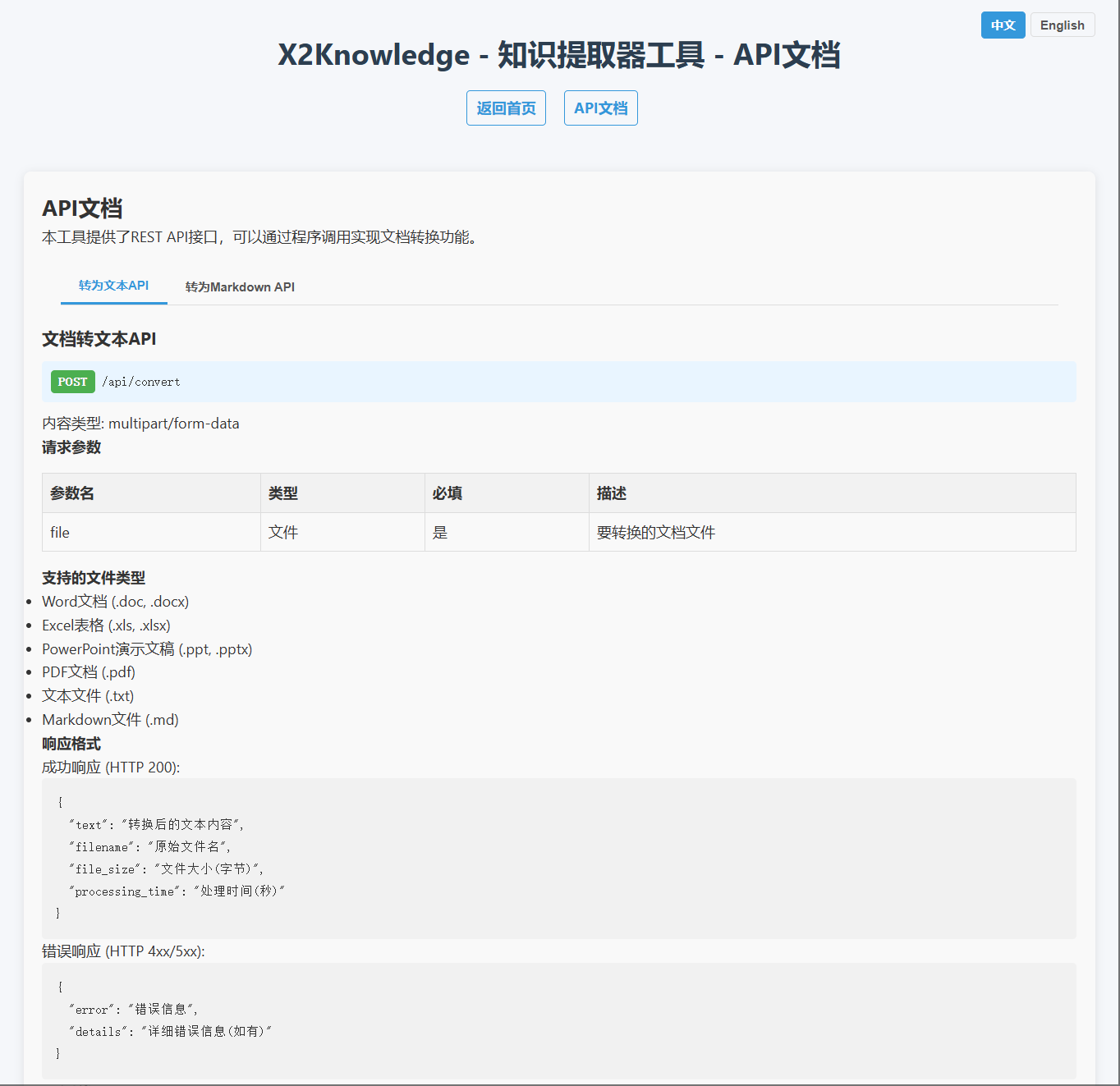
REST API
该工具提供了REST API以供程序访问:
- 文本转换:
POST /api/convert - Markdown转换:
POST /api/convert-to-md
有关详细文档和测试,请通过Web界面访问API文档页面。
系统截图
界面
主页
API调用
原始格式
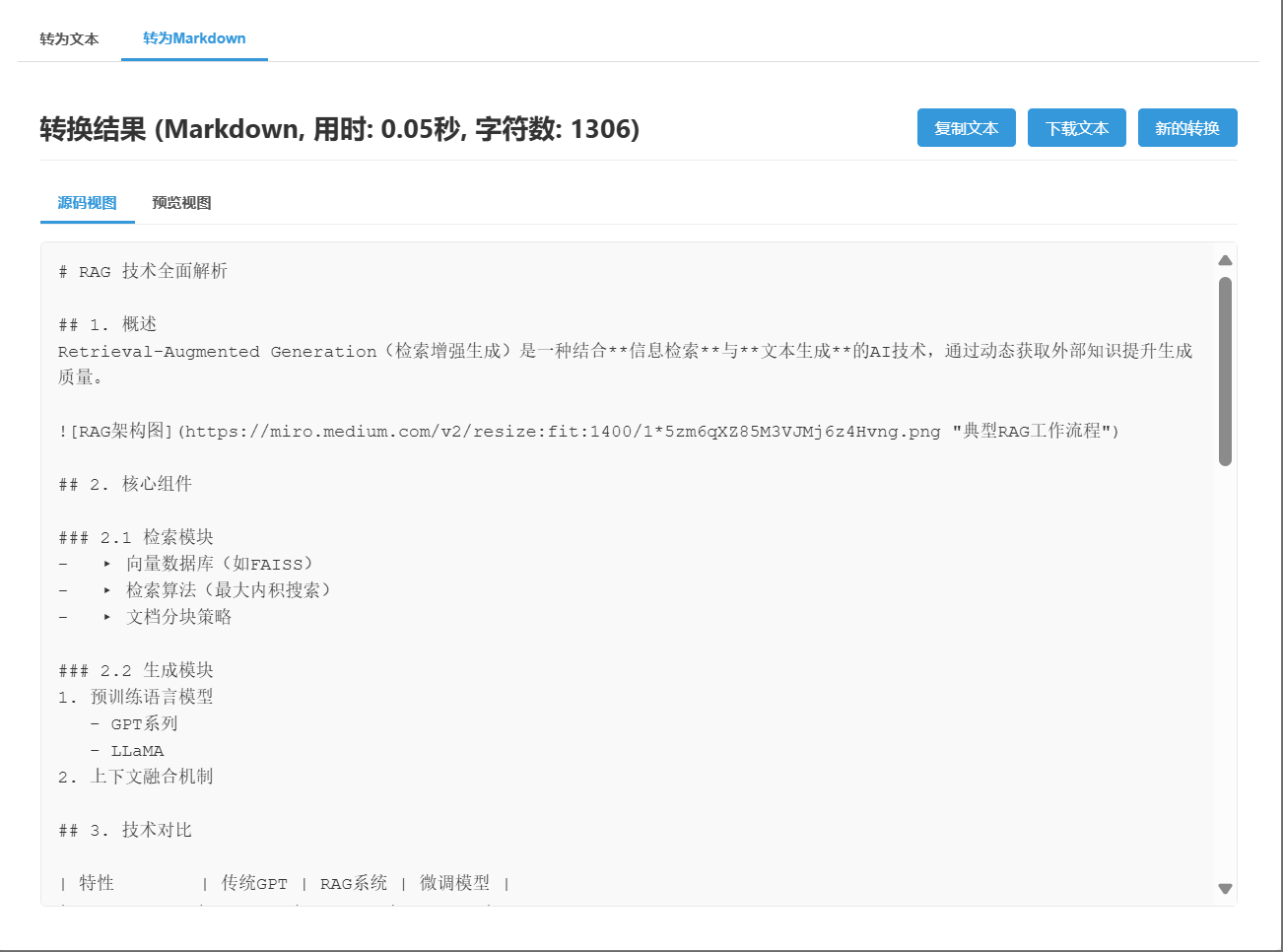
MD格式
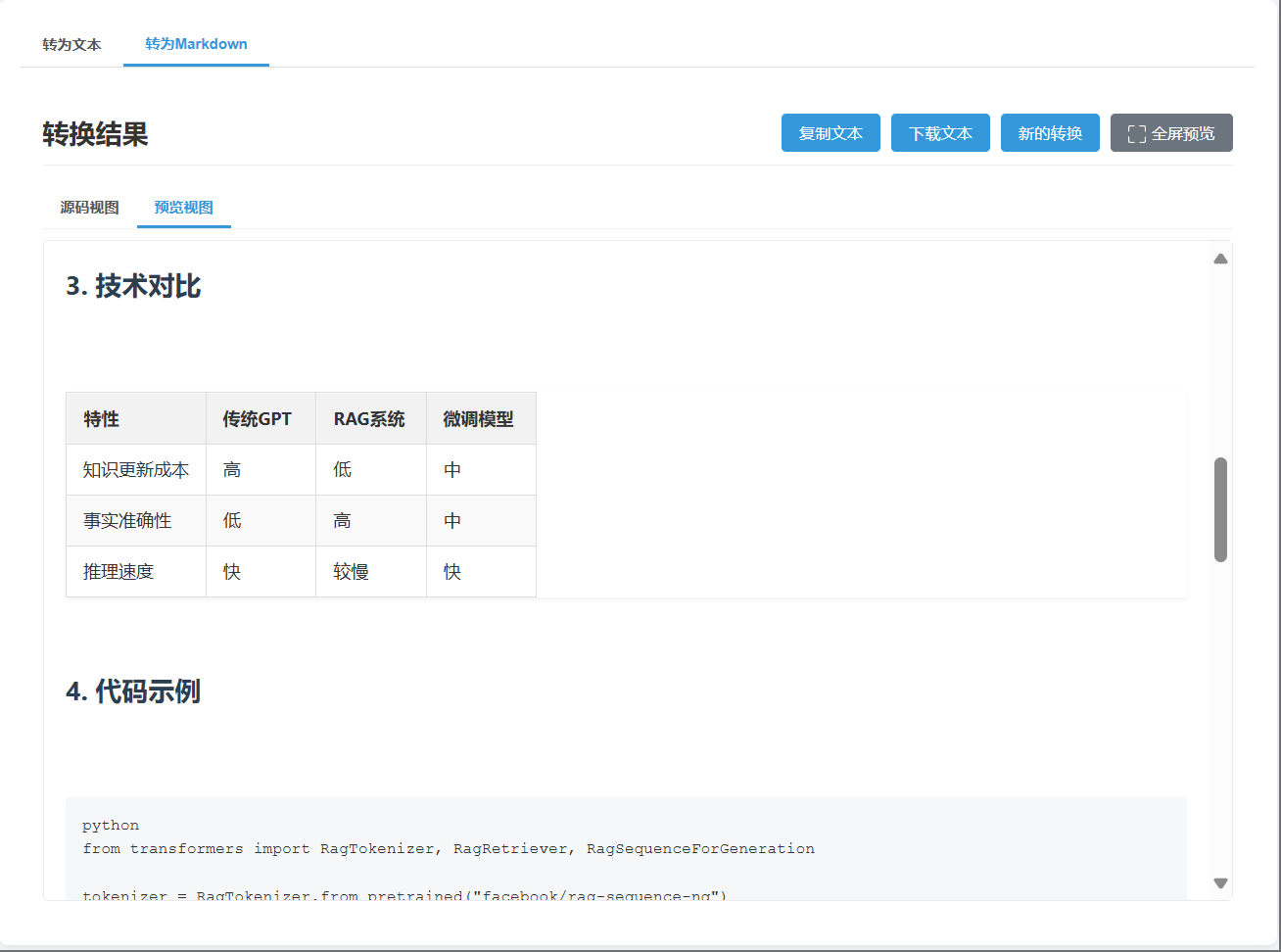
效果
WORD文件
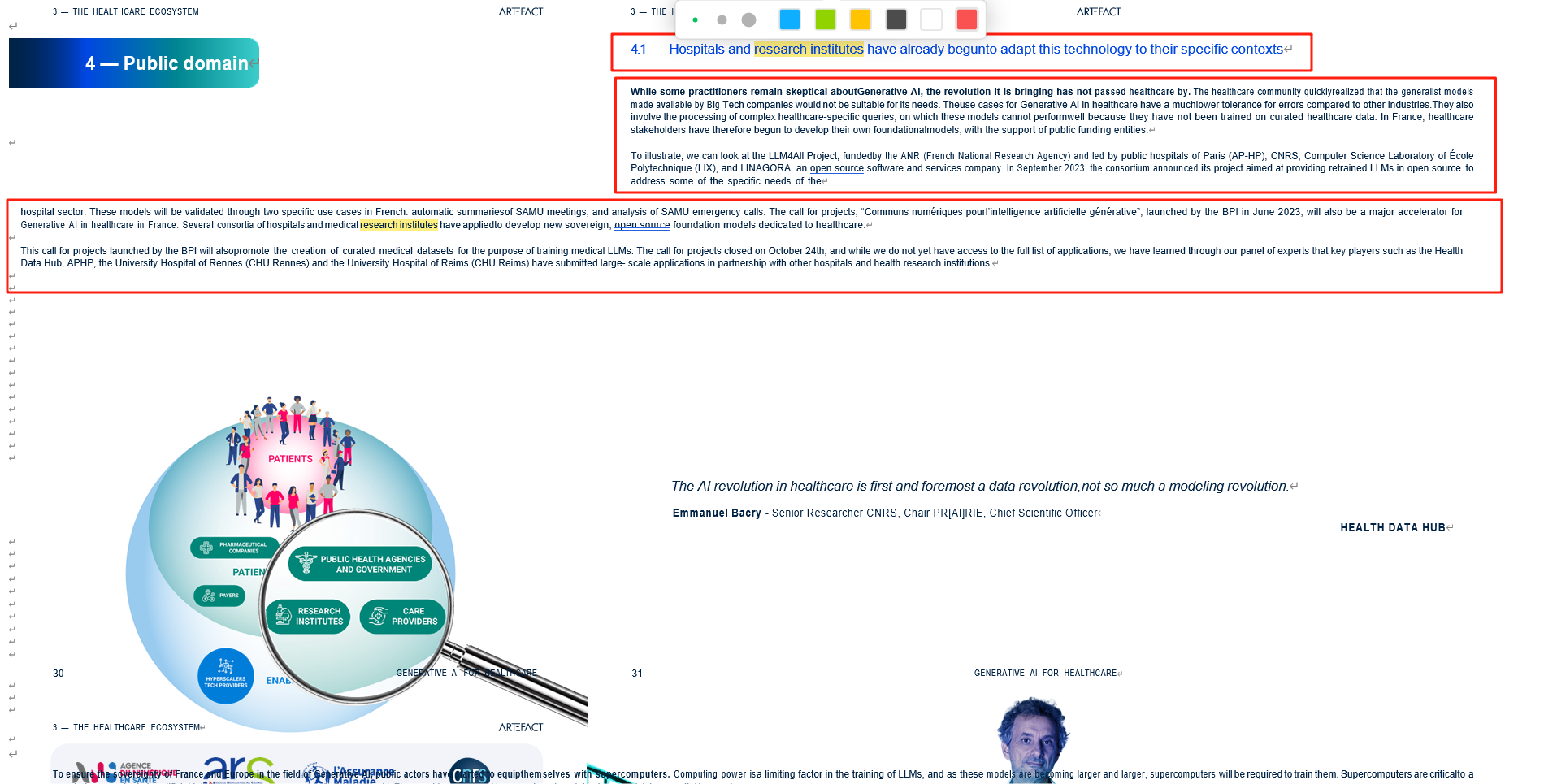
WORD转换效果
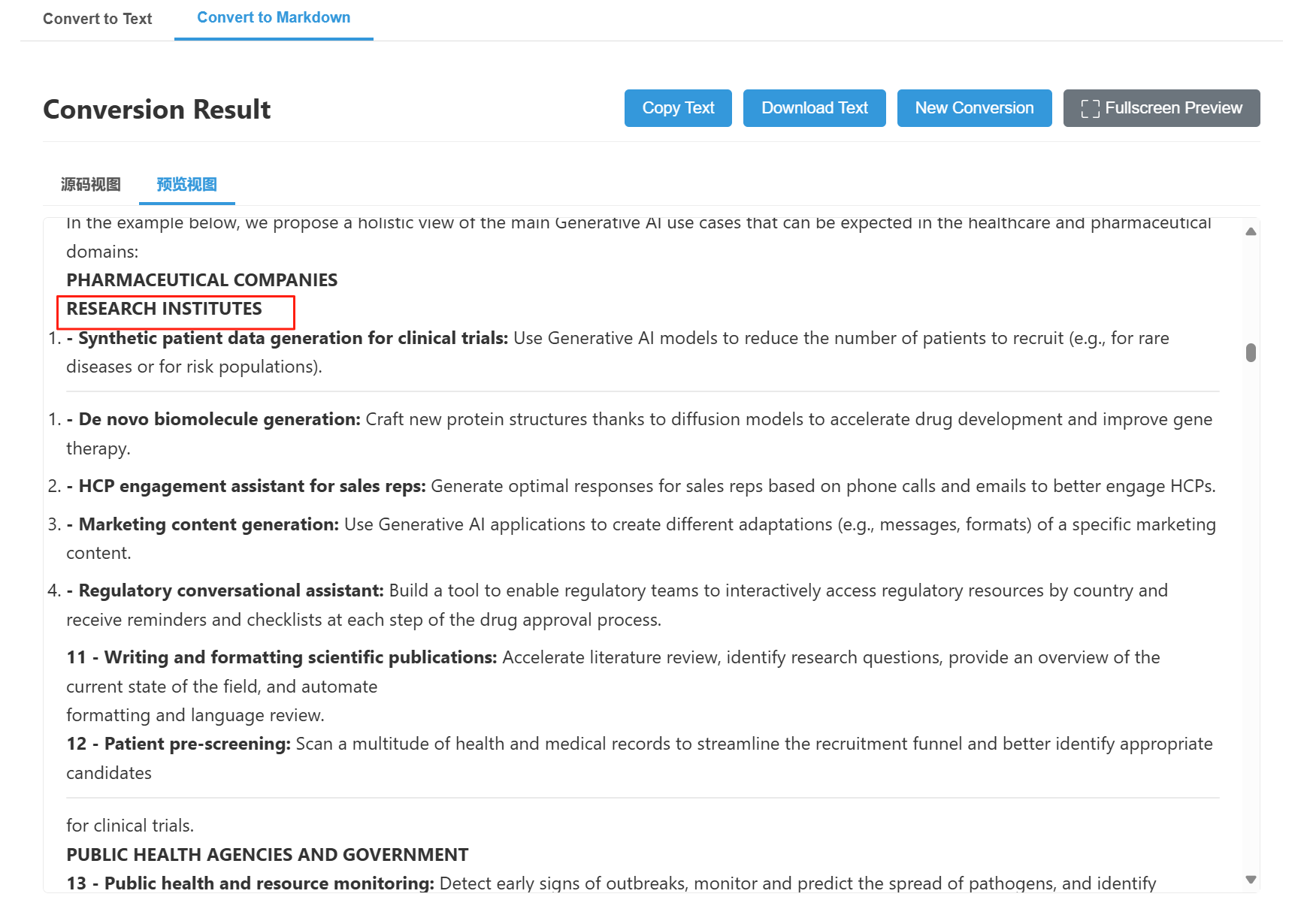
WORD中表格转换效果
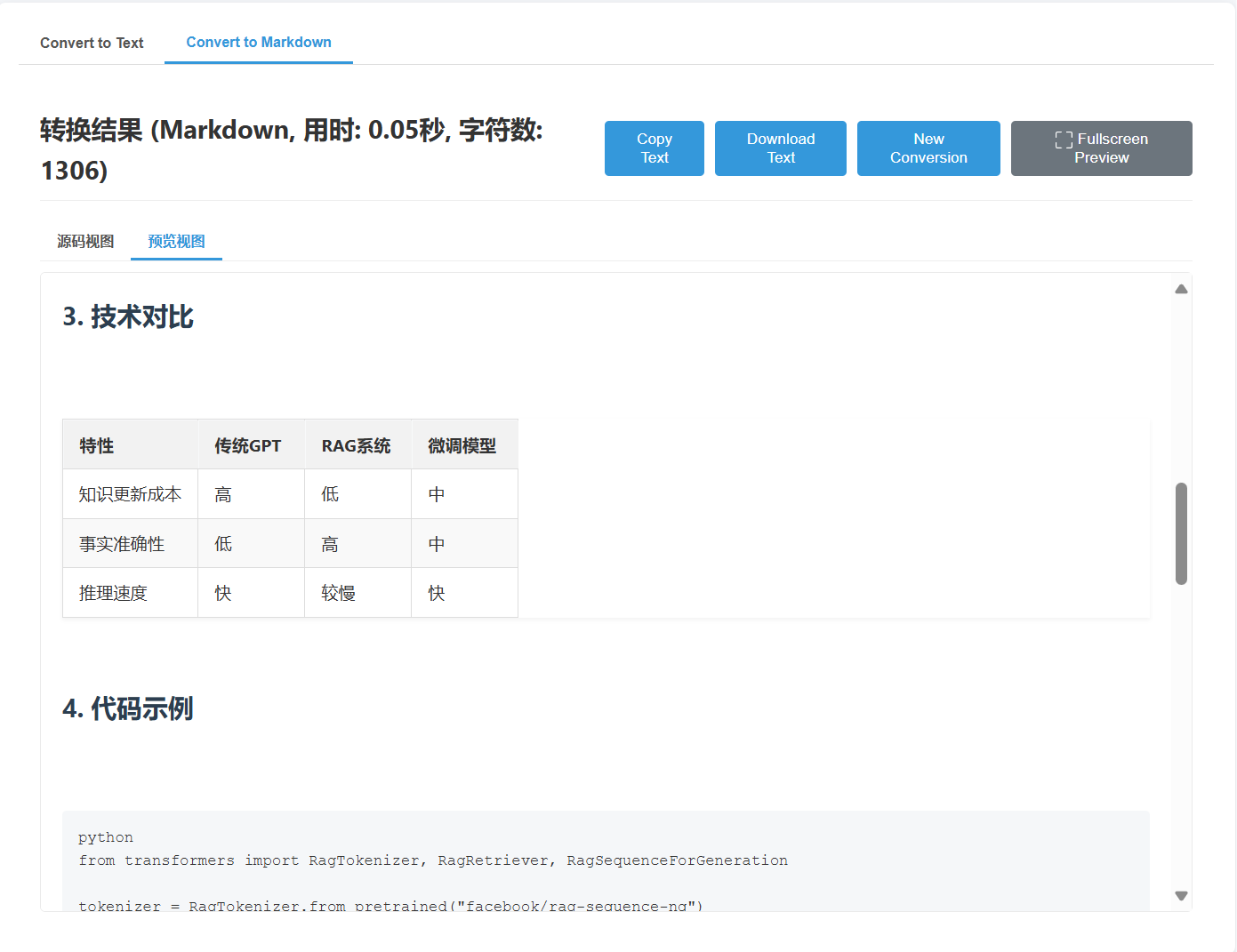
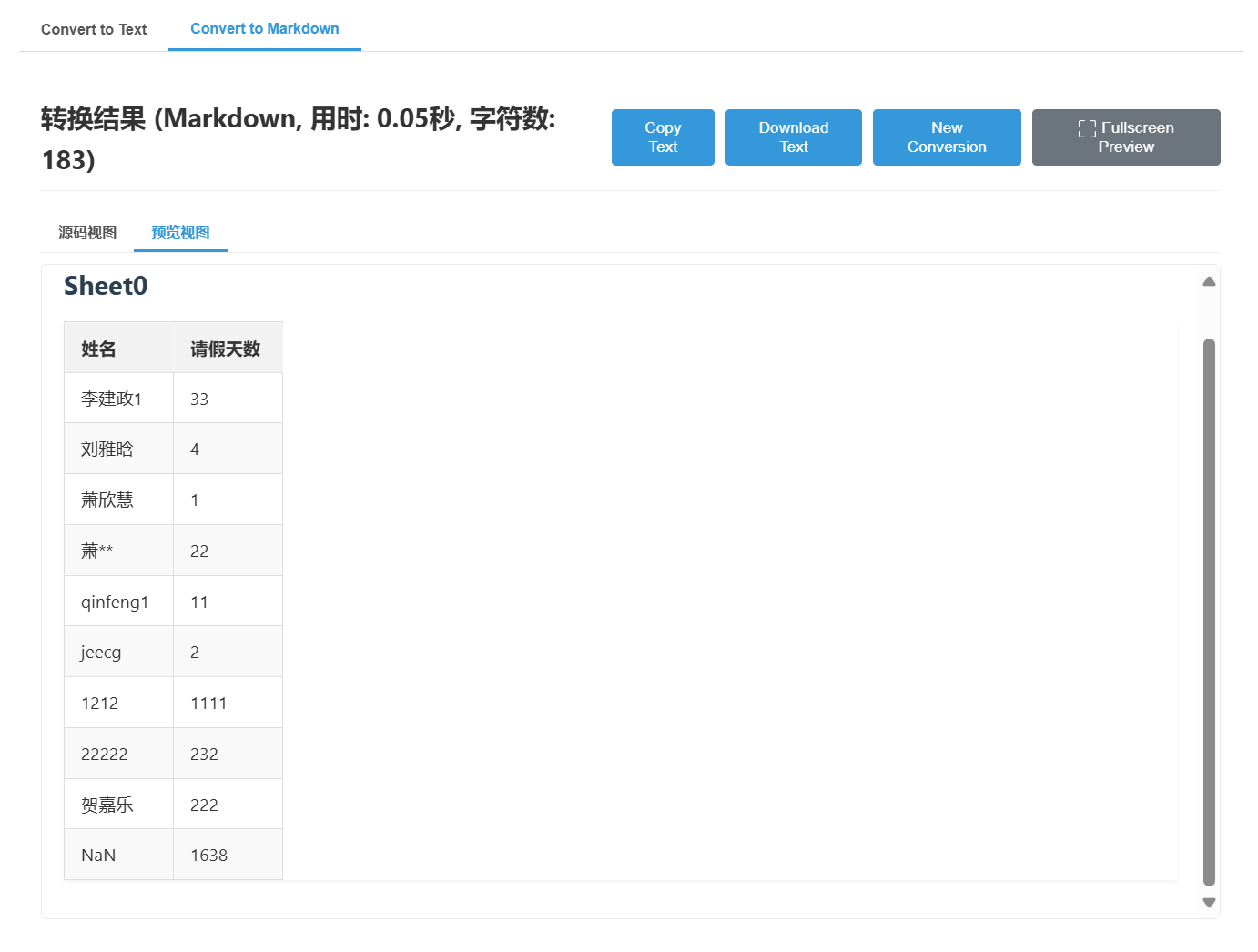
Execel效果
PPT效果
安装与部署
本地安装
要求
- Python 3.6+
- Flask
- pytesseract(用于OCR功能)
- Tesseract OCR引擎
设置
-
克隆仓库:
git clone https://github.com/leonda123/X2Knowledge.git cd X2Knowledge -
创建虚拟环境并安装依赖:
python -m venv venv source venv/bin/activate # 在Windows上:venv\Scripts\activate pip install -r requirements.txt -
安装Tesseract OCR引擎(用于OCR功能):
- Windows:从GitHub Tesseract releases下载并安装
- macOS:
brew install tesseract - Linux:
sudo apt-get install tesseract-ocr
-
运行应用程序:
flask run -
打开Web浏览器并导航至
http://127.0.0.1:5000/
Docker部署
使用Docker可以更方便地部署X2Knowledge,避免环境配置问题。
使用Docker Compose
-
克隆仓库:
git clone https://github.com/leonda123/X2Knowledge.git git clone https://gitee.com/leonda/X2Knowledge.git cd X2Knowledge -
构建并启动容器:
docker-compose up -d -
访问应用程序: 打开Web浏览器并导航至
http://localhost:5000/
手动构建Docker映像
-
构建Docker映像:
docker build -t x2knowledge . -
运行容器:
docker run -d -p 5000:5000 --name x2knowledge -v ./uploads:/app/uploads -v ./logs:/app/logs x2knowledge -
访问应用程序: 打开Web浏览器并导航至
http://localhost:5000/
项目优势
- 高性能文档处理:优化的文档解析引擎,能够高效处理各种格式的文档
- 低资源消耗:即使在配置较低的服务器上也能流畅运行
- 准确的结构保留:特别是在Markdown转换中,能够准确保留文档的原始结构
- 多平台支持:可在Windows、macOS和Linux系统上部署
- 灵活的API接口:提供RESTful API,方便与其他系统集成
- 无外部依赖的部署:除OCR功能外,核心功能无需外部服务支持
- 容器化部署:支持Docker部署,简化环境配置
已知问题
- 较旧的Word文档(.doc格式)处理时间可能较长;建议在上传前将其转换为.docx格式
- 一些复杂的文档布局在Markdown转换中可能无法完美保留
- OCR准确性取决于图像质量和文本复杂性
未来计划
大型语言模型集成
- DeepSeek集成:计划支持使用DeepSeek进行文本语义理解和结构化提取
- GPT模型支持:增加与OpenAI GPT-3.5/4的集成,用于高级文档理解和摘要生成
- 国产开源模型支持:增加对百度文心一言、讯飞星火等国内大模型的支持
推理平台支持
- Ollama本地部署:支持使用Ollama在本地部署开源模型进行文档处理
- vLLM高性能推理:计划集成vLLM以提供更高效的模型推理能力
- 模型量化支持:添加对GPTQ、GGUF等量化模型的支持,降低资源需求
RAG增强功能
- 自动文档切分:智能分段算法,为RAG应用提供最佳检索粒度
- 向量嵌入生成:直接生成文档的向量嵌入,加速知识库构建
- 知识图谱导出:从文档中抽取实体关系,生成初步知识图谱
版本历史
v0.2.1 (当前版本)
- 优化Markdown渲染,完美支持表格和图片
- 增加Docker部署支持
- 改进图片交互体验
- 增加代码高亮功能
v0.1.0
- 添加Markdown转换功能
- 添加Markdown预览功能
- 添加音频文件转换支持
- 将文件大小限制增加到50MB
- 改进错误处理和用户反馈
- 增强文档说明
v0.0.`
- 初始版本,支持文本转换
- OCR功能
- UTF-8编码转换
- 基本Web界面
许可证
本项目基于MIT许可证 - 详情请参阅LICENSE文件。
致谢
- pytesseract提供OCR功能
- FlaskWeb框架
- MarkidownMarkidown工具
- marked.js提供Markdown渲染
- highlight.js提供代码高亮
- 各种文档处理库
使用Flask和JavaScript开发,充满❤️
QQ:176942734
邮箱:dada_jiu45@hotmail.com

















 2699
2699

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









