







系列文章目录
目录
前言
英伟达™ Isaac GR00T N1 是世界上首个用于通用仿人机器人推理和技能的开放式基础模型。该跨体模型采用多模态输入(包括语言和图像)在不同环境中执行操作任务。
GR00T N1 在一个庞大的仿人机器人数据集上进行训练,该数据集包括真实捕获数据、使用英伟达 Isaac GR00T Blueprint 组件生成的合成数据(神经生成轨迹示例)以及互联网规模的视频数据。通过后期训练,它可以适应特定的应用、任务和环境。
GR00T N1 的神经网络架构是视觉语言基础模型与扩散变换器头的结合,可对连续动作进行去噪处理。以下是该架构的示意图:
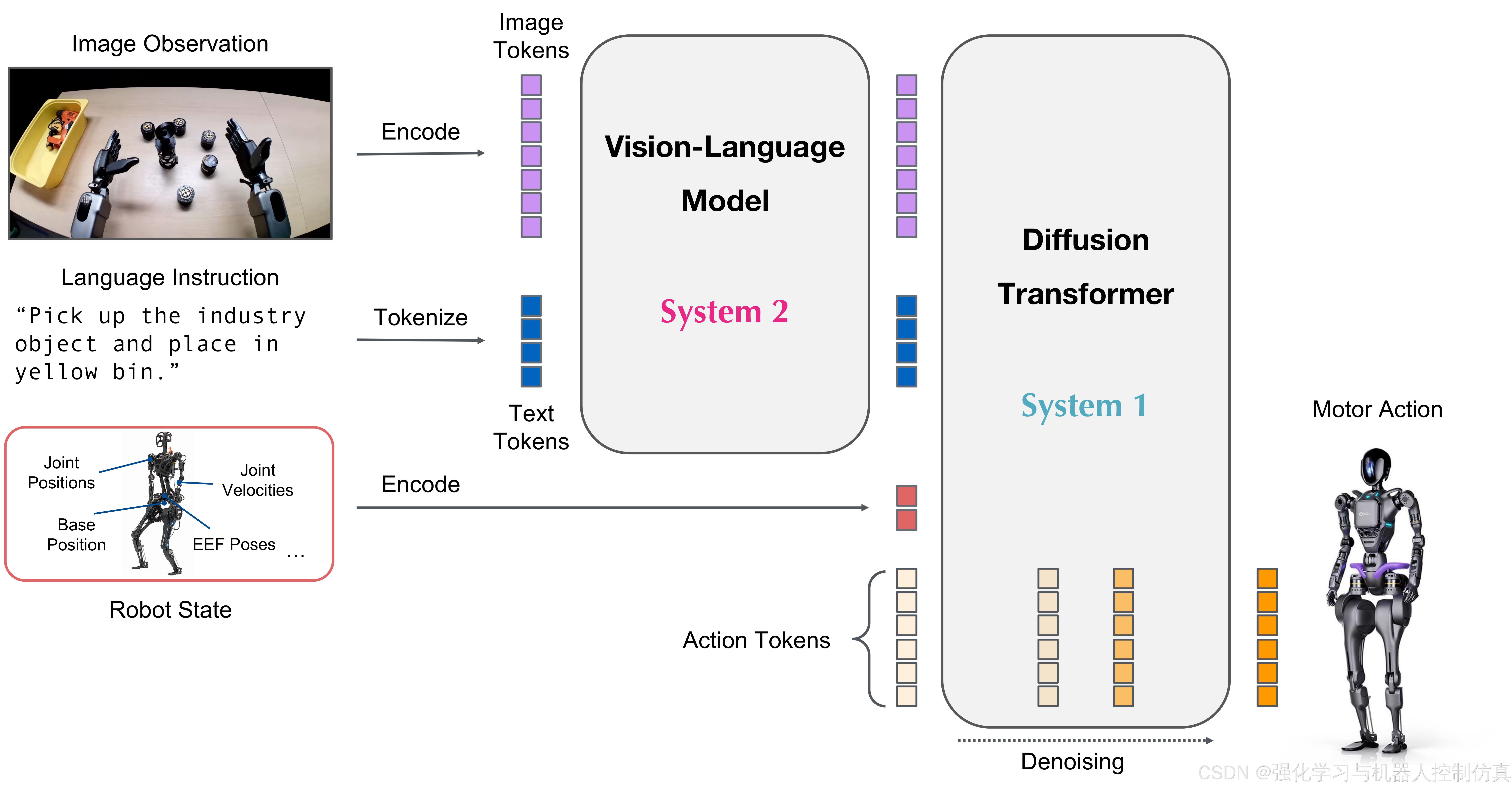
以下是使用 GR00T N1 的一般流程:
- 假设用户已经收集了一个机器人演示数据集,其形式为(视频、状态、动作)三元组。
- 用户首先要将演示数据转换为与 LeRobot 兼容的数据模式(更多信息请参见 getting_started/LeRobot_compatible_data_schema.md),该模式与上游的 Huggingface LeRobot 兼容。
- 我们的软件仓库提供了一些示例,用于配置不同的配置,以便使用不同的机器人体现形式进行训练。
- 我们的软件仓库提供了方便的脚本,可在用户数据上对预训练的 GR00T N1 模型进行微调,并运行推理。
- 用户将把 Gr00tPolicy 连接到机器人控制器,以便在目标硬件上执行操作。
一、目标受众
GR00T N1 面向仿人机器人领域的研究人员和专业人员。该资源库提供以下工具
- 利用预训练的基础模型进行机器人控制
- 在小型定制数据集上进行微调
- 用最少的数据使模型适应特定的机器人任务
- 部署推理模型
重点是通过微调实现机器人行为的定制化。
二、前提条件
- 我们已在 Ubuntu 20.04 和 22.04、GPU: H100、L40、RTX 4090 和 A6000 用于微调,Python==3.10,CUDA 版本 12.4。
- 在推理方面,我们在 Ubuntu 20.04 和 22.04 上进行了测试,GPU:H100、L40、RTX 4090 和 A6000: RTX 4090 和 A6000
- 如果尚未安装 CUDA 12.4,请按照此处的说明进行安装。
- 请确保系统中已安装以下依赖项:ffmpeg、libsm6、libxext6
三、安装指南
克隆版本库
git clone https://github.com/NVIDIA/Isaac-GR00T
cd Isaac-GR00T创建新的 conda 环境并安装依赖项。我们推荐使用 Python 3.10:
请注意,请确保您的 CUDA 版本为 12.4。否则,您可能很难正确配置 flash-attn 模块。
conda create -n gr00t python=3.10
conda activate gr00t
pip install --upgrade setuptools
pip install -e .
pip install --no-build-isolation flash-attn==2.7.1.post4 四、开始使用本软件仓库
我们在 ./getting_started 文件夹中提供了可访问的 Jupyter 笔记本和详细文档。实用脚本可在 ./scripts 文件夹中找到。
4.1 数据格式与加载
为了加载和处理数据,我们使用 Huggingface LeRobot 数据,但使用了更详细的模式和注释模式(我们称之为 “LeRobot 兼容数据模式”)。
LeRobot 数据集的示例存储在这里:./demo_data/robot_sim.PickNPlace. (附带附加 modality.json 文件)
数据集格式的详细说明请参阅 getting_started/LeRobot_compatible_data_schema.md
一旦数据以这种格式整理好,就可以使用 LeRobotSingleDataset 类加载数据。
from gr00t.data.dataset import LeRobotSingleDataset
from gr00t.data.embodiment_tags import EmbodimentTag
from gr00t.data.dataset import ModalityConfig
from gr00t.experiment.data_config import DATA_CONFIG_MAP
# get the data config
data_config = DATA_CONFIG_MAP["gr1_arms_only"]
# get the modality configs and transforms
modality_config = data_config.modality_config()
transforms = data_config.transform()
# This is a LeRobotSingleDataset object that loads the data from the given dataset path.
dataset = LeRobotSingleDataset(
dataset_path="demo_data/robot_sim.PickNPlace",
modality_configs=modality_config,
transforms=None, # we can choose to not apply any transforms
embodiment_tag=EmbodimentTag.GR1, # the embodiment to use
)
# This is an example of how to access the data.
dataset[5]getting_started/0_load_dataset.ipynb 是一个交互式教程,介绍如何加载数据并进行处理,以便与 GR00T N1 模型连接。
scripts/load_dataset.py 是一个可执行脚本,内容与笔记本相同。
4.2 推理
GR00T N1 模型托管在 Huggingface 上。
交叉体现数据集示例见 demo_data/robot_sim.PickNPlace
from gr00t.model.policy import Gr00tPolicy
from gr00t.data.embodiment_tags import EmbodimentTag
# 1. Load the modality config and transforms, or use above
modality_config = ComposedModalityConfig(...)
transforms = ComposedModalityTransform(...)
# 2. Load the dataset
dataset = LeRobotSingleDataset(.....<Same as above>....)
# 3. Load pre-trained model
policy = Gr00tPolicy(
model_path="nvidia/GR00T-N1-2B",
modality_config=modality_config,
modality_transform=transforms,
embodiment_tag=EmbodimentTag.GR1,
device="cuda"
)
# 4. Run inference
action_chunk = policy.get_action(dataset[0])getting_started/1_gr00t_inference.ipynb是建立推理管道的交互式Jupyter笔记本教程。
用户还可以使用提供的脚本运行推理服务。推理服务可在服务器模式或客户端模式下运行。
python scripts/inference_service.py --model_path nvidia/GR00T-N1-2B --server在另一个终端上运行客户端模式,向服务器发送请求。
python scripts/inference_service.py --client4.3 微调
用户可以运行下面的微调脚本,利用示例数据集对模型进行微调。相关教程请参见 getting_started/2_finetuning.ipynb。
然后运行微调脚本:
# first run --help to see the available arguments
python scripts/gr00t_finetune.py --help
# then run the script
python scripts/gr00t_finetune.py --dataset-path ./demo_data/robot_sim.PickNPlace --num-gpus 1您还可以从我们发布的 huggingface 模拟数据中下载样本数据集。
huggingface-cli download nvidia/PhysicalAI-Robotics-GR00T-X-Embodiment-Sim \
--repo-type dataset \
--include "gr1_arms_only.CanSort/**" \
--local-dir $HOME/gr00t_dataset建议的微调配置是将批次规模提升到最大,并进行 20k 步的训练。
硬件性能考虑因素
- 微调性能: 我们使用 1 个 H100 节点或 L40 节点进行最佳微调。其他硬件配置(如 A6000、RTX 4090)也可以使用,但收敛时间可能更长。具体的批量大小取决于硬件以及正在调整的模型组件。
- 推理性能: 对于实时推理,大多数现代 GPU 在处理单个样本时的性能都差不多。我们的基准测试表明,L40 和 RTX 4090 的推理速度差异很小。
关于新的体现微调,请查看我们的笔记本 getting_started/3_new_embodiment_finetuning.ipynb。
4.4 评估
为了对模型进行离线评估,我们提供了一个脚本,可以在数据集上对模型进行评估,并绘制出评估图。
运行新训练的模型
python scripts/inference_service.py --server \
--model_path <MODEL_PATH> \
--embodiment_tag new_embodiment运行离线评估脚本
python scripts/eval_policy.py --plot \
--dataset_path <DATASET_PATH> \
--embodiment_tag new_embodiment然后,您将看到 “地面实况 ”与 “预测行动 ”的对比图,以及行动的非规范 MSE。这将表明该策略在数据集上的表现是否良好。
五、常见问题
5.1 我有自己的数据,下一步该如何微调?
- 本软件包假定您的数据已经按照 LeRobot 格式进行了整理。
5.2 什么是模态配置?Embodiment Tag?
- 体现标签: 定义所使用的机器人化身,非预处理化身标签均视为新化身标签。
- 模态配置: 定义数据集中使用的模式(如视频、状态、动作等)
- 变换配置(Transform Config): 定义数据载入过程中应用于数据的数据变换。
- 更多详情,请参阅 getting_started/4_deeper_understanding.md
5.3 Gr00tPolicy 的推理速度如何?
以下是基于单个 L40 GPU 的基准测试结果。使用 RTX 4090 等消费级 GPU 进行推理(单样本处理)的性能大致相同:
| 模块 | 推理速度 |
|---|---|
| VLM Backbone | 22.92 ms |
| Action Head with 4 diffusion steps | 4 x 9.90ms = 39.61 ms |
| Full Model | 62.53 ms |
我们注意到,在推理过程中,4 个去噪步骤就足够了。

















 938
938

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









