






系列文章目录
前言
人形机器人的灵巧性主要来自超灵巧的全身运动,从而能够完成需要较大操作工作空间的任务--例如从地面拾取物体。然而,由于人形机器人的高自由度(DoF)和非线性动力学特性,要在真实人形机器人上实现这些功能仍具有挑战性。我们提出了自适应运动优化(AMO),这是一种将仿真强化学习(RL)与轨迹优化相结合的框架,可实现实时、自适应的全身控制。为了减轻运动模仿 RL 中的分布偏差,我们构建了一个混合 AMO 数据集,并训练了一个能够对潜在 O.O.D. 命令进行稳健、按需适应的网络。我们在模拟和 29-DoF Unitree G1 人形机器人上验证了 AMO,与强大的基线相比,AMO 表现出卓越的稳定性和更广阔的工作空间。最后,我们展示了 AMO 稳定的性能,支持通过模仿学习自主执行任务,凸显了系统的多功能性和鲁棒性。
@article{li2025amo, title={AMO: Adaptive Motion Optimization for Hyper-Dexterous Humanoid Whole-Body Control}, author={Li, Jialong and Cheng, Xuxin and Huang, Tianshu and Yang, Shiqi and Qiu, Rizhao and Wang, Xiaolong}, journal={Robotics: Science and Systems 2025}, year={2025} }
一、导言
人类可以通过全身运动来扩展双手的工作空间。人形机器人的关节构造在模仿人类的功能和自由度的同时,也面临着如何通过实时控制实现类似动作的挑战。这是由于动态人形机器人全身控制具有高维、高度非线性和接触丰富的特点。传统的基于模型的最优控制方法需要对机器人和环境进行精确建模、高计算能力以及可实现计算结果的降阶模型,这对于在现实世界中利用过动人形机器人的所有 DoFs(29)的问题来说是不可行的。
强化学习(RL)与模拟到现实(sim-to-real)相结合的最新进展表明,在现实世界环境中实现人形机器人运动操作任务具有巨大潜力[42]。虽然这些方法可以实现对高自由度(DoF)人形机器人的稳健实时控制,但它们往往依赖于大量的人类专业知识和对奖励函数的手动调整,以确保稳定性和性能。为了解决这一局限性,研究人员将运动模仿框架与 RL 相结合,利用重新定位的人类运动捕捉(MoCap)轨迹来定义奖励目标,从而指导策略学习 [28,10]。然而,这些轨迹通常在运动学上是可行的,但却无法考虑目标人形机器人平台的动态约束,从而在模拟运动和硬件可执行行为之间引入了体现差距。另一种方法是将轨迹最优化(TO)与 RL 相结合,以弥补这一差距 [38, 41]。
| Metrics | AMO(Ours) | HOVER[30] | Opt2Skill[41] |
|---|---|---|---|
| Ref. Type | Hybrid | MoCap | Traj. Opt. |
| SO(3) + Height Dex. Torso | ✓ | ✗ | ✗ |
| SE(3) Task Space | ✓ | ✗ | ✗ |
| No Ref. Deploy | ✓ | ✓ | ✗ |
| O.O.D. | ✓ | ✗ | ✗ |
虽然这些方法提高了人形机器人的机械臂操作能力,但目前的方法仍然局限于简化的运动操作模式,而无法实现真正的全身灵巧性。运动捕捉驱动的方法存在固有的运动学偏差:其参考数据集主要以双足运动序列(如行走、转弯)为特征,而缺乏超灵巧操作所必需的协调臂躯干运动。与此相反,基于 TO 的轨迹优化技术也面临着互补的局限性--它们依赖于有限的运动基元库,而且在实时应用中计算效率低下,因此无法实现策略通用化。这严重阻碍了在需要快速适应非结构化输入(如反应式远程操作或环境扰动)的动态场景中的部署。
为了弥合这一差距,我们提出了自适应运动最优化(AMO)--一种通过以下两项协同创新实现人形机器人实时全身控制的分层框架:(i)混合运动合成: 我们通过将运动捕捉数据中的手臂轨迹与概率采样的躯干方向融合,制定了混合上半身指令集,系统地消除了训练分布中的运动偏差。这些指令驱动一个动态感知轨迹优化器,生成同时满足运动学可行性和动力学约束的全身参考运动,从而构建了 AMO 数据集--第一个明确设计用于灵巧机械臂操作的人形机器人运动操作库。(ii) 通用策略训练: 虽然直接的解决方案是通过离散查找表将指令映射到动作,但这种方法从根本上来说仍然局限于离散的、在分布中的场景。而我们的 AMO 网络可以学习连续映射,从而在连续输入空间和分布外(O.O.D.)远程操作命令之间实现稳健的插值,同时保持实时响应能力。
在部署过程中,我们首先从 VR 远程操纵系统中提取稀疏姿势,并输出具有多目标逆运动学的上半身目标。经过训练的 AMO 网络和 RL 策略共同输出机器人的控制信号。我们在表 I 中列出了简要的比较,以显示我们的主要优势。表 I 列出了我们的方法与最近两部代表性作品的简要比较,以显示我们的方法的主要优势。总而言之,我们的贡献如下:
- 一种新型自适应控制方法 AMO 可大幅扩展人形机器人的工作空间。AMO 可在任务空间目标稀疏的情况下实时工作,并显示出以往方法无法达到的 O.O.D. 性能。
- 人形机器人超灵巧 WBC 控制器的新里程碑,其工作空间更大,可使人形机器人从地面拾取物体。
- 在模拟和现实世界中进行的远程操作和自主结果的综合实验,显示了我们方法的有效性和核心组件的消减。
二、相关工作
人形机器人的全身控制。由于人形机器人的高 DoFs 和非线性,其全身控制仍然是一个具有挑战性的问题。以前主要通过动态建模和基于模型的控制来实现 [51, 75, 32, 52, 18, 34, 72, 35, 31, 14, 16, 19, 56]。最近,深度强化学习方法在实现腿部机器人的稳健运动性能方面显示出前景[22, 47, 37, 23, 21, 38, 67, 3, 74, 46, 20, 79, 8, 26, 73, 39, 40, 61, 7]。研究人员对四足动物 [22, 8, 7, 27] 和人形机器人 [24, 9, 29, 33] 从高维输入进行全身控制进行了研究。 [24] 训练一个变压器进行控制,另一个变压器进行模仿学习。 [9] 只鼓励上半身模仿动作,而下半身的控制则是解耦的。 [29] 为下游任务训练目标条件策略。所有文献[24、9、29]都只展示了有限的全身控制能力,即强制人形机器人的躯干和骨盆保持不动。 文献[33]展示了人形机器人富有表现力的全身运动操作,但并未强调利用全身控制来扩展机器人的运动操作任务空间。
人形机器人的远程操作。人形机器人的远程操作对于实时控制和机器人数据收集至关重要。之前在人形机器人远程操作方面的研究包括 [64, 29, 28, 24, 11, 42]。例如,[29, 24]使用第三人称 RGB 摄像头来获取人类遥控操作者的关键点。一些作品利用虚拟现实技术为远距操作者提供以自我为中心的观察。 文献[11]使用苹果公司的 VisionPro,用灵巧的双手控制活动的头部和上半身。 [42]使用 Vision Pro 控制头部和上半身,同时使用踏板进行运动控制。人形机器人的全身控制需要远程操作员为机器人提供物理上可实现的全身坐标。
运动操作模仿学习。已对模仿学习进行了研究,以帮助机器人自主完成任务。从现有工作的示范来源来看,可分为从真实机器人专家数据中学习 [4, 25, 78, 65, 5, 36, 13, 12, 55, 54, 66, 76]、从游戏数据中学习 [15, 70, 50],以及从人类示范中学习 [21, 57, 26, 73, 59, 58, 69, 71, 9, 29, 24]。这些模仿学习研究仅限于操作技能,而对机械臂操作的模仿学习研究则很少。 [25]使用基于轮子的机器人研究了运动操作的模仿学习。本文利用模仿学习使人形机器人能够自主完成运动操作任务。
三、自适应运动最优化
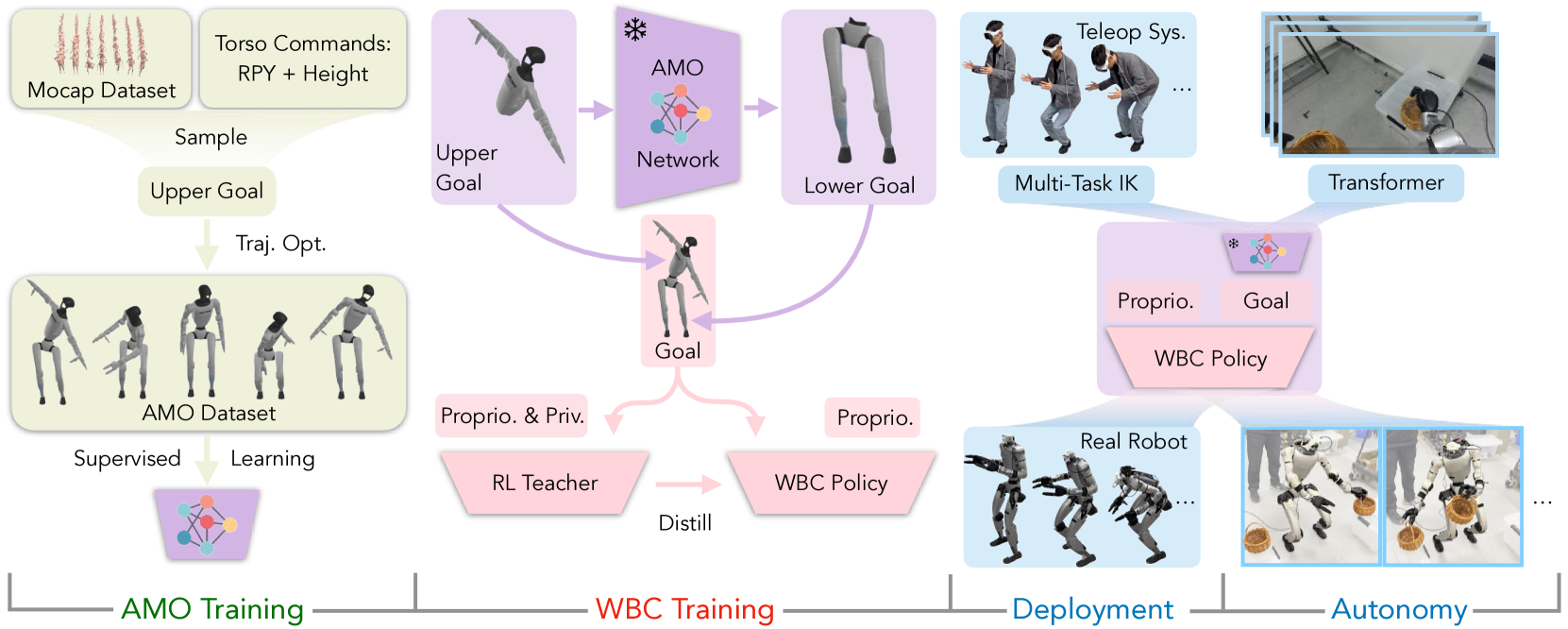
我们介绍 AMO: 如图 2 所示,自适应运动优化是一个实现无缝全身控制的框架。我们的系统分为四个不同的部分。我们首先介绍术语和整体框架,然后在下面的章节中分别阐述这些组件的学习和实现。
3.1 问题表述和符号
我们解决的是人形机器人全身控制问题,重点关注两种不同的设置:远程操作和自主控制。
在远程操作环境中,全身控制问题被表述为学习目标条件策略π′:𝒢×𝒮→𝒜,其中𝒢代表目标空间,𝒮代表观测空间,𝒜代表行动空间。在自主设置中,学习到的策略π:𝒮→𝒜仅根据观察结果生成行动,无需人工输入。
目标条件远程操作策略接收来自远程操作员的控制信号𝐠∈𝒢,其中𝐠=[𝐩head,𝐩left,𝐩right,𝐯]。𝐩head,𝐩left,𝐩right分别代表操作员头部和手部的关键点姿势,而𝐯=[vx,vy,vyaw]则指定基本速度。观测数据𝐬∈𝒮包括视觉和本体感觉数据: 𝐬=[imgleft,imgright,𝐬proprio]。动作𝐚∈𝒜包括上半身和下半身的关节角度指令:𝐚=[𝐪upper, 𝐪lower]。
a) 目标条件远程运行策略: 目标条件策略采用分层设计:π′=[πupper′,πlower′]。上层策略 πupper′(𝐩head,𝐩left,𝐩right)=[𝐪upper,𝐠′] 输出上半身的动作和中间控制信号 𝐠′=[𝐫𝐩𝐲、 h],其中𝐫𝐩𝐲指令躯干方向,h指令基座高度。下部策略 πlower′(𝐯,𝐠′,𝐬proprio)=𝐪lower 利用中间控制信号、速度指令和本体感觉观测结果为下半身生成动作。
b) 自主政策: 自主策略 π=[πupper,πlower] 与远程操作策略采用相同的分层设计。下层策略完全相同:πlower=πlower′,而上层策略则独立于人类输入生成行动和中间控制:πupper(imgleft,imgright,𝐬proprio)=[𝐪upper,𝐯,𝐠′]。
3.2 适应模块预训练
在我们的系统规范中,下层策略遵循[vx,vy,vyaw,𝐫𝐩𝐲,h]形式的指令。遵循速度指令 [vx,vy,vyaw] 的运动能力可以很容易地通过在模拟环境中随机采样有向矢量来学习,其策略与 [8, 9] 相同。然而,学习躯干和高度跟踪技能并非易事,因为它们需要全身协调。在运动任务中,我们可以根据 Raibert 启发式[62]设计脚步跟踪奖励来促进技能学习,而在全身控制任务中,我们却缺乏这样的启发式来引导机器人完成全身控制。一些研究 [33, 28] 通过跟踪人类参照物来训练此类策略。然而,他们的策略并没有在人类姿势和全身控制指令之间建立联系。
为解决这一问题,我们提出了自适应运动优化(AMO)模块。AMO 模块表示为:j(𝐪upper,𝐫𝐩𝐲,h)=𝐪lowerref。在接收到上位机的全身控制指令𝐫𝐩𝐲,h后,它会将这些指令转换为所有下位机执行器的关节角度参考,以便下位机策略进行明确跟踪。为了训练这个自适应模块,首先,我们通过随机抽样上层命令来收集 AMO 数据集,并执行基于模型的轨迹优化来获取下层身体的关节角度。轨迹优化可表述为多关节最优控制问题(MCOP),其代价函数如下:
其中包括状态𝐱和控制𝐮的正则化、目标跟踪项ℒ𝐫𝐩𝐲和ℒh,以及确保全身控制时平衡的质量中心(CoM)正则化项。在收集数据集时,我们首先从 AMASS 数据集[43]中随机选择上半身运动,并随机采样躯干指令。然后,我们进行轨迹最优化,以跟踪躯干目标,同时保持稳定的 CoM 并遵守扳手锥约束,以生成动态可行的参考关节角度。由于我们不考虑行走情况,因此认为机器人的双脚都与地面接触。我们通过 Crocoddyl [48, 49],使用控制限制可行性驱动的微分动态编程(BoxFDDP)生成参考关节角度。收集到的这些数据用于训练 AMO 模块,该模块可将躯干指令转换为参考低姿势。AMO 模块是一个三层多层感知器(MLP),在下部策略训练的后期阶段被冻结。
3.3 下层策略训练
我们使用大规模并行仿真,利用 IsaacGym[44] 训练低级策略。低级策略旨在跟踪𝐠′和𝐯,同时利用本体感知观测数据 𝐬proprio,其定义为:
上述公式包含基本方向 𝜽t、基本角速度 𝝎t、当前位置、速度和最后位置目标。值得注意的是,下部策略的观测包括上半身致动器的状态,以便更好地协调上半身和下半身。ϕt 是步态循环信号,其定义方法与文献[45, 77]类似。𝐪lowerref 是 AMO 模块生成的参考下半身关节角度。下半身动作空间𝐪lower∈ℝ15 是维数为 15 的向量,由 2∗6 个双腿目标关节位置和 3 个腰部电机目标关节位置组成。
我们选择使用师生框架来训练低级策略。我们首先使用现成的 PPO[63],训练一个能在模拟中观察特权信息的教师策略。然后,我们利用监督学习将教师策略提炼为学生策略。学生策略只观察真实信息,可用于远程操作和自主任务。
教师策略可表述为 πteacher (𝐯,𝐠′,𝐬proprio,𝐬priv)=𝐪lower. 附加特权观测值𝐬priv 的定义为:
其中包括地面真实值:基础速度 𝐯tgt、躯干方向 𝐫𝐩𝐲tgt、基础高度 htgt,这些值在现实世界中追踪相应目标时不易获得。教师 RL 培训过程详见附录 B。
学生策略可以写成πstudent(𝐯,𝐠′,𝐬proprio,𝐬hist)=𝐪lower。为了利用现实世界中的观测数据对𝐬proprio进行补偿,学生策略使用了25步的本体感觉观测历史作为额外的输入信号:𝐬hist,t=𝐬proprio,t-1∼t-25。
3.4 远程操作上部策略的实施
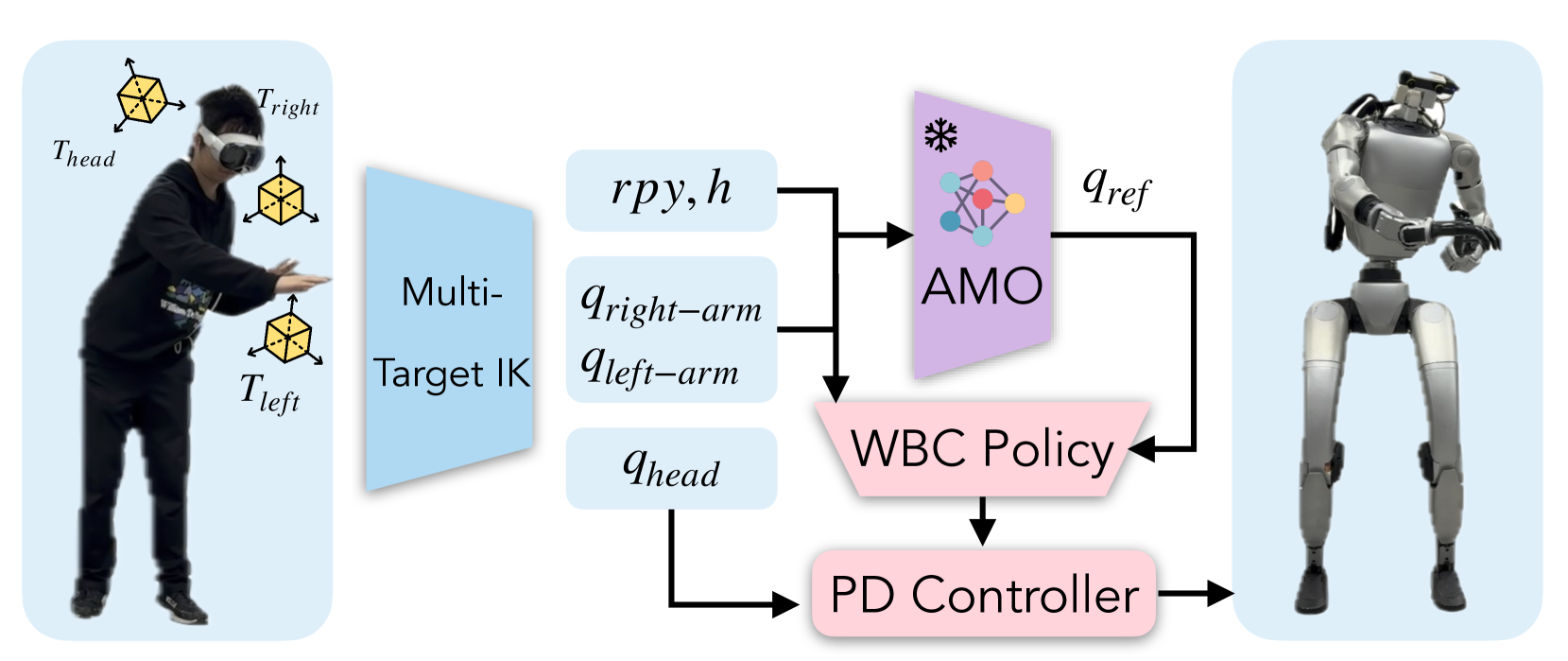
远程操作上部策略可生成一系列用于全身控制的指令,包括手臂和手部动作、躯干方向和基座高度。我们选择使用基于优化的技术来实现这一策略,以达到机械臂操作任务所需的精度。具体来说,手部动作通过重定向生成,而其他控制信号则通过逆运动学(IK)计算。我们的手部重定向基于 dex-retargeting [60]。有关重定向公式的更多细节见附录 A。
在我们的全身控制框架中,我们将传统的 IK 扩展为多目标加权 IK,最小化到三个关键目标的 6D 距离:头部、左腕和右腕。机器人同时调动所有上半身致动器来匹配这三个目标。从形式上看,我们的目标是
如图 3 所示。最优化变量𝐪包括机器人上半身的所有驱动自由度(DoF):𝐪头部、𝐪左臂和𝐪右臂。除了运动指令外,它还会求解一个中间指令,以实现全身协调:𝐫𝐩𝐲和 h,用于躯干定向和高度控制。为确保平稳的上半身控制,姿势成本在最优化变量𝐪的不同组成部分中以不同方式加权:𝐖𝐪头部、𝐪左臂、𝐪右臂<𝐖𝐫𝐩𝐲,h。这就促使政策在执行较简单的任务时优先考虑上半身致动器。然而,对于需要全身运动的任务,例如弯腰拾取或够到远处的目标,则会生成额外的控制信号[𝐫𝐩𝐲,h]并发送给下级策略。下层策略协调电机角度以满足上层策略的要求,从而实现全身触及目标。我们的 IK 实现采用 Levenberg-Marquardt (LM) 算法 [68],并基于 Pink [6]。
3.5 自主上层策略训练
我们通过模仿学习来学习自主上层策略。首先,人类操作员使用我们的目标条件策略与机器人进行远程操作,记录观察结果和动作作为示范。然后,我们使用带有 DinoV2 [53, 17] 视觉编码器的 ACT [78] 作为策略骨干。视觉观察包括两幅立体图像 imgleft 和 imgright。DinoV2 将每幅图像分割成 16×22 个补丁,并为每个补丁生成一个 384 维的视觉标记,从而得到一个形状为 2×16×22×384 的组合视觉标记。这个视觉标记与通过投影𝐨t=[𝐬proprio,tupper,𝐯t-1,𝐫𝐩𝐲t-1,ht-1]得到的状态标记相连接。这里,𝐬proprio,tupper 是上半身本体感知观测值,[𝐯t-1,𝐫𝐩𝐲t-1,ht-1] 是发送给下半身策略的最后一条指令。由于我们的解耦系统设计,上层策略观察的是下层策略的命令,而不是直接的下半身本体感知。该策略的输出表示为
包括所有上半身关节角度和下半身政策的中间控制信号。
| Metrics (↓) | Ey | Ep | Er | Eh | E𝐯 |
|---|---|---|---|---|---|
| Stand | |||||
| Ours(AMO) | 0.1355 | 0.1259 | 0.0675 | 0.0151 | 0.0465 |
| w/o AMO | 0.3137 | 0.1875 | 0.0681 | 0.1168 | 0.0477 |
| w/o priv | 0.1178 | 0.1841 | 0.0757 | 0.0228 | 0.1771 |
| w rand arms | 0.1029 | 0.1662 | 0.0716 | 0.0200 | 0.1392 |
| Walk | |||||
| Ours(AMO) | 0.1540 | 0.1519 | 0.0735 | 0.0182 | 0.1779 |
| w/o AMO | 0.3200 | 0.1927 | 0.0797 | 0.1253 | 0.1539 |
| w/o priv | 0.1226 | 0.1879 | 0.0779 | 0.0276 | 0.2616 |
| w rand arms | 0.1200 | 0.1837 | 0.0790 | 0.0240 | 0.2596 |
四、评估
在本节中,我们将通过在模拟和真实世界中进行实验来解决以下问题:
- AMO 在追踪运动指令𝐯 和躯干指令𝐫𝐩𝐲,h 方面的表现如何?
- AMO 与其他 WBC 策略相比如何?
- AMO 系统在现实世界中的表现如何?
我们在 IsaacGym 模拟器 [44] 中进行模拟实验。我们的真实机器人设置如图 3 所示,它是在 Unitree G1 [1] 的基础上改进而成的,带有两只 Dex3-1 灵巧的手。该平台具有 29 个全身 DoFs 和每只手的 7 个 DoFs。我们定制了一个带有三个致动多自由度的主动头,用于映射人类操作员的头部运动,并安装了一个 ZED Mini [2] 摄像头,用于立体流媒体传输。
4.1 AMO在追踪运动指令𝐯和躯干指令𝐫𝐩𝐲,h方面的表现如何?
表 II 将 AMO 的性能与以下基线进行比较,以评估 AMO 的性能:
- w/o AMO:该基线采用与 Ours(AMO)相同的 RL 训练方法,但做了两处重要修改。首先,它将 AMO 输出ᵂlowerref 排除在观测空间之外。其次,它不是对偏离ᵂlowerref 的情况进行惩罚,而是根据偏离默认姿态的情况进行正则化惩罚。
- w/o priv:这一基线是在没有额外特权观测数据𝐬priv 的情况下进行训练的。
- w rand arms: 在此基线中,手臂关节角度的设置不使用从 MoCap 数据集中采样的人类参照物。相反,它们是通过在各自关节范围内均匀采样值来随机分配的。
| Metrics | Ry | Rp | Rr |
|---|---|---|---|
| Ours(AMO) | (-1.5512, 1.5868) | (-0.4546, 1.5745) | (-0.4723, 0.4714) |
| w/o AMO | (-0.9074, 0.8956) | (-0.4721, 1.0871) | (-0.3921, 0.3626) |
| Waist Tracking | (-1.5274, 1.5745) | (-0.4531, 0.5200) | (-0.3571, 0.3068) |
| ExBody2 | (-0.1005, 0.0056) | (-0.2123, 0.4637) | (-0.0673, 0.0623) |
使用以下指标对性能进行评估:
- 躯干方向跟踪精度: 躯干方向跟踪用 Ey、Ep、Er 来衡量。结果表明,AMO 在滚动和俯仰方向上的跟踪精度更高。在俯仰跟踪方面的改进最为显著,其他基准线很难保持精确度,而我们的模型则大大降低了跟踪误差。Wand手臂的偏航跟踪误差最小,这可能是因为随机手臂运动使机器人能够探索更广泛的姿势范围。然而,AMO 不一定会在偏航跟踪方面表现出色,因为与滚动和俯仰相比,躯干偏航旋转引起的 CoM 位移最小。因此,偏航跟踪的准确性可能无法完全体现 AMO 生成自适应稳定姿势的能力。尽管如此,值得注意的是,无 AMO 情况下的偏航跟踪也很困难,这表明 AMO 为实现稳定的偏航控制提供了关键的参考信息。
- 高度跟踪精度: 结果显示,AMO 的高度跟踪误差最小。值得注意的是,不含 AMO 的误差明显高于所有其他基线,这表明它几乎无法跟踪高度指令。躯干跟踪至少有一个腰部电机角度与指令成正比,而高度跟踪则不同,它需要多个下半身关节的协调调整。如果没有来自 AMO 的参考信息,该策略就无法学习高度指令与相应电机角度之间的转换关系,因此很难掌握这项技能。
- 线性速度跟踪精度: AMO 模块基于双支撑姿态下的全身控制生成参考姿态,这意味着它不会考虑运动过程中因脚部摆动而产生的姿态变化。尽管存在这一限制,AMO 仍能以较低的跟踪误差执行稳定的运动,这证明了它的鲁棒性。
4.2 AMO 与其他全身控制器相比如何?

为了解决这个问题,我们比较了以下基线的躯干控制范围:
- 无 AMO:该基线与上一节所述相同。
- 腰部跟踪: 该基线明确指令腰部电机的偏航、滚动和俯仰角度,而不是控制躯干方向。
- ExBody2:[33] 是在 RL 中利用人体参考运动指导机器人全身控制的代表作。它通过修改腰部的参考关节角度来实现躯干方向控制。
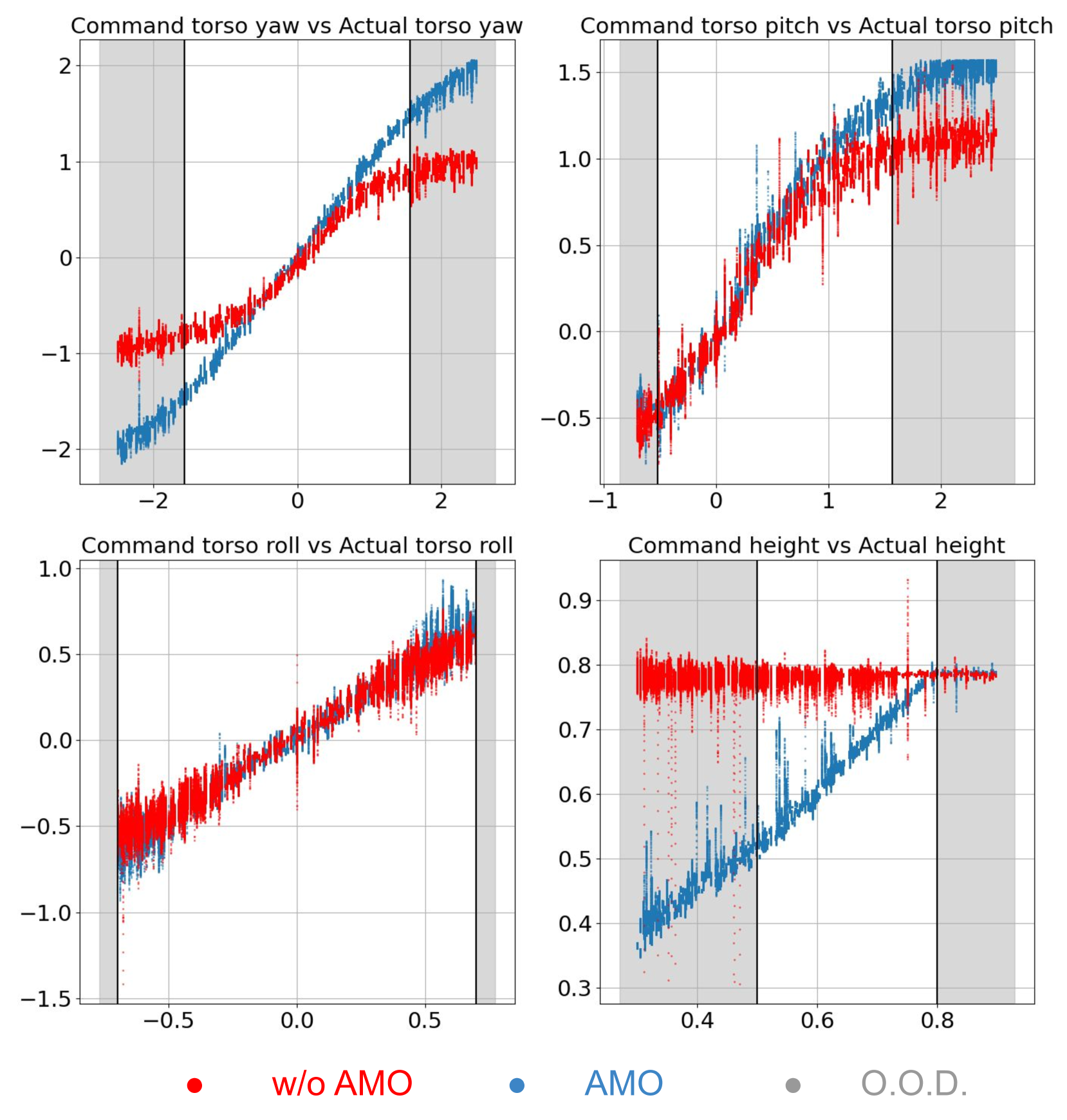
表 III 列出了躯干控制范围的定量测量结果,图 4 则说明了定性差异。对于 ExBody2 和其他依赖于人体运动跟踪的方法来说,躯干控制范围本质上受到用于训练的人体运动数据集多样性的限制。如果特定运动方向在数据集中的代表性不足,学习到的策略就很难超越这些稀少的示例。正如我们的结果所示,ExBody2 对躯干俯仰仅表现出轻微的控制能力,在很大程度上无法跟踪躯干偏航和滚动运动。
腰部跟踪从根本上受到机器人腰部关节的限制,因为它完全依赖腰部电机来控制躯干方向,而不是利用整个下半身。例如,Unitree G1 的腰部俯仰电机的位置限制仅为 ±0.52 弧度。相比之下,AMO 实现的躯干运动范围明显大于其他基线,尤其是在躯干俯仰方面,它允许机器人将上半身完全平躺弯曲。此外,该策略还通过利用腿部电机来调整下部姿势以保持稳定,从而展示了自适应行为。这在躯干滚动控制中很明显,机器人会稍微弯曲一条腿以倾斜骨盆。而在没有 AMO 的情况下,则观察不到这种自适应行为。总之,通过加入 AMO,该策略不仅扩大了躯干控制的操作范围,还通过动态适应指令方向提高了躯干的稳定性。


图 6:在真实世界环境中自主完成的任务。对于每项任务,我们使用远程操纵系统收集 50 个事件,并训练 ACT 自主完成。
AMO 的优势不仅在于准确跟踪分布内(I.D.)躯干指令,还在于能够有效适应分布外(O.O.D.)指令。在图 5 中,我们通过评估 AMO 和有/无 AMO 在 I.D. 和 O.O.D. 命令上的性能,对它们进行了比较。很明显,w/o AMO 在 O.O.D.指令上表现不佳:在躯干俯仰和偏航指令达到采样训练范围之前,AMO 无法跟踪这些指令,而且完全无法跟踪高度指令,这一点在上一节中已经讨论过。相比之下,AMO 在跟踪 O.O.D. 命令时表现出了出色的适应性。尽管 AMO 只在±1.57 的范围内接受过训练,但它成功地跟踪了高达 ±2 的躯干偏航指令。同样,在高度跟踪方面,虽然训练分布仅限于 0.5 米至 0.8 米的范围,但该策略具有良好的泛化能力,能准确跟踪低至 0.4 米的高度。这些结果表明,通过模仿训练的 AMO 模块和 RL 策略都表现出很强的泛化能力,表明 AMO 在适应训练分布以外的全身指令方面具有很强的鲁棒性。
4.3 AMO 系统在现实世界中的表现如何?
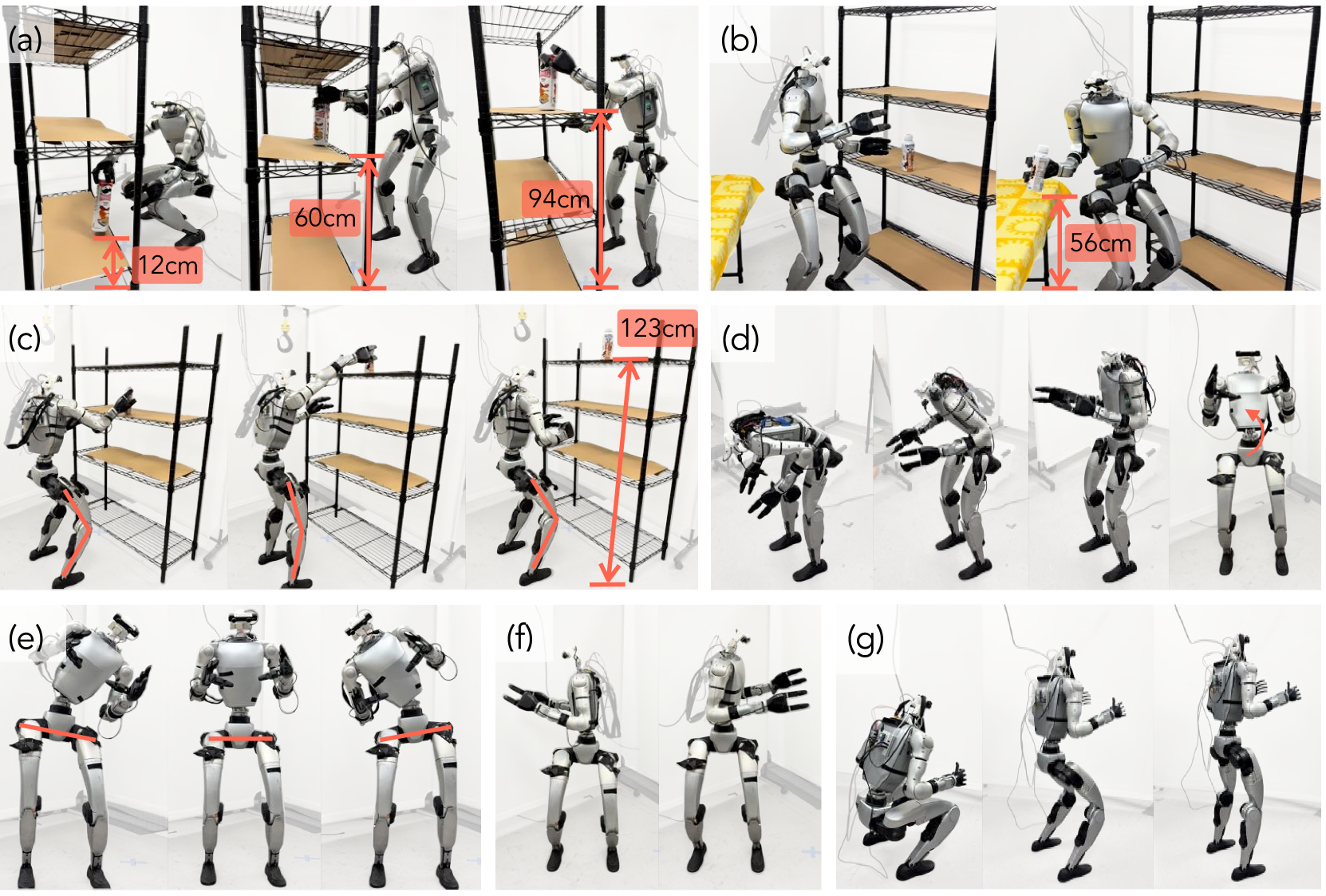
为了展示我们的策略在躯干方向和底座高度控制方面的能力,我们使用 AMO 远程操作框架执行了一系列超灵巧操作任务。图 1 和补充视频展示了这些远程操作实验。
为了进一步突出 AMO 系统的鲁棒性和超灵巧性,我们选择了几个需要自适应全身控制的挑战性任务,并通过收集示范来进行模仿学习,如图 6 所示。这些任务的性能和评估详见下文:
| Paper Bag Picking | |||
|---|---|---|---|
| Setting | Picking | Moving | Placing |
| Stereo Input; Chunk Size 120 | 8/10 | 8/10 | 9/10 |
| Mono Input; Chunk Size 120 | 9/10 | 7/10 | 10/10 |
| Stereo Input; Chunk Size 60 | 7/10 | 7/10 | 6/10 |
| Trash Bottle Throwing | ||
|---|---|---|
| Setting | Picking | Placing |
| Stereo Input; Chunk Size 120 | 7/10 | 10/10 |
| Mono Input; Chunk Size 120 | 4/10 | 10/10 |
| Stereo Input; Chunk Size 60 | 5/10 | 10/10 |
拣纸袋: 这项任务要求机器人在没有末端执行器的情况下执行运动操作任务,因此对精度的要求特别高。我们评估了各种训练设置对任务性能的影响,如表 IV 所示。在最完整的设置下,该策略达到了接近完美的成功率。虽然只使用单张图像会略微降低成功率,但这项任务特别容易受到较小块大小的影响。当机器人将手放在袋子把手下并试图调整方向时,较短的动作记忆往往会导致混乱。
投掷垃圾瓶: 这项任务不涉及运动;但是,为了成功抓住瓶子并将其扔进另一个角度的垃圾桶,机器人必须执行大量的躯干运动。如表 IV 所示,评估结果表明,我们的系统可以学会自主完成这项任务。立体视觉和较长的动作块都提高了任务性能。立体视觉的优势可能来自于更大的视场(FoV)和隐含的深度信息,这对于抓取是至关重要的。
为了证明我们系统的有效性及其在执行复杂机械臂运动操作任务方面的潜力,我们对一项需要超灵巧全身控制的长地平线任务进行了 IL 实验: 采摘篮子。在这项任务中,机器人必须蹲下到相当低的高度,并调整躯干方向以抓取两侧靠近地面的两个篮子。图 7 是一个自主滚动的案例研究,展示了所学策略在真实世界条件下的执行情况。
为了说明机器人如何协调全身致动器,我们将腰部电机和左膝电机的关节角度可视化。左膝电机被选为高度变化和行走的代表关节。如图 7 所示,任务开始时,机器人蹲下并向前弯腰,使双手与篮子的高度保持一致。这一动作反映在膝关节和腰部俯仰电机角度的增加上。接下来,机器人左右倾斜以抓住篮子,这可以从腰部滚动曲线的变化看出。成功抓取目标后,机器人站立起来,这表现为膝盖角度的减小。膝电机读数的周期性波动证实机器人正在行走。静止后,机器人向左右两侧伸手,将篮子放到架子上,腰部偏航电机前后旋转,以促进躯干横向运动。这个案例研究清楚地表明,我们的系统能够利用全身协调来有效地完成复杂的任务。
五、结论与局限
我们介绍了 AMO,这是一种将基于模型的轨迹最优化与无模型强化学习相结合以实现全身控制的框架。通过在模拟和真实机器人平台上进行大量实验,我们证明了我们方法的有效性。AMO 使现实世界中的人形机器人控制达到了前所未有的灵巧和精确水平。我们希望我们的框架能为实现人形机器人全身控制提供一条新的途径,超越传统的基于模型的全身控制方法和依赖于跟踪人类运动参考的 RL 策略。
虽然我们的解耦方法为全身控制引入了一种新的范式,但其分离的性质从本质上限制了它所能实现的全身协调水平。例如,在高动态场景中,人类自然不仅要利用下半身和腰部,还要利用手臂来保持平衡。然而,在我们目前的设置中,手臂控制与机器人的基本状态无关。通过将基础状态信息纳入上肢关节角度的获取,可以探索一种平衡感知的上半身控制机制,从而有可能增强整体稳定性和适应性。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









