







系列文章目录
目录
前言
一、加载推理数据集指南
LeRobot 格式
- 本教程将展示如何使用我们的数据加载器加载 LeRobot 格式的数据。
- 我们将以已经转换为 LeRobot 格式的 robot_sim.PickNPlace 数据集为例。
- 要了解如何转换自己的数据集,请参阅 Gr00t 的 LeRobot.md
from gr00t.utils.misc import any_describe
from gr00t.data.dataset import LeRobotSingleDataset
from gr00t.data.dataset import ModalityConfig
from gr00t.data.schema import EmbodimentTag1.1 加载数据集
要加载数据集,我们需要定义以下 3 项内容:
- 数据集的路径
- 模态配置
- ModalityConfigs 定义了下游使用的数据模式(如视频、状态、动作、语言),如模型训练或推理。
- 每个模态通过 delta_indices(例如,[0] 表示只加载当前帧,[-1,0] 表示加载上一帧和当前帧)指定要加载的帧。
- 体现标签(EmbodimentTag
- EmbodimentTag 用于指定数据集的具体体现。所有体现标签的列表可在 gr00t.data.embodiment_tags.EmbodimentTag 中找到。
- GR00T 的架构针对特定的机器人类型(实施方案)优化了不同的动作头。EmbodimentTag 可以告诉模型使用哪个动作头进行微调和/或推理。在我们的例子中,由于我们使用的是仿人手臂,因此我们指定 EmbodimentTag.GR1_UNIFIED,以获得仿人专用动作头的最佳性能。
import os
import gr00t
# REPO_PATH is the path of the pip install gr00t repo and one level up
REPO_PATH = os.path.dirname(os.path.dirname(gr00t.__file__))
DATA_PATH = os.path.join(REPO_PATH, "demo_data/robot_sim.PickNPlace")
print("Loading dataset... from", DATA_PATH)# 2. modality configs
modality_configs = {
"video": ModalityConfig(
delta_indices=[0],
modality_keys=["video.ego_view"],
),
"state": ModalityConfig(
delta_indices=[0],
modality_keys=[
"state.left_arm",
"state.left_hand",
"state.left_leg",
"state.neck",
"state.right_arm",
"state.right_hand",
"state.right_leg",
"state.waist",
],
),
"action": ModalityConfig(
delta_indices=[0],
modality_keys=[
"action.left_hand",
"action.right_hand",
],
),
"language": ModalityConfig(
delta_indices=[0],
modality_keys=["annotation.human.action.task_description", "annotation.human.validity"],
),
}# 3. gr00t embodiment tag
embodiment_tag = EmbodimentTag.GR1
# load the dataset
dataset = LeRobotSingleDataset(DATA_PATH, modality_configs, embodiment_tag=embodiment_tag)
print('\n'*2)
print("="*100)
print(f"{' Humanoid Dataset ':=^100}")
print("="*100)
# print the 7th data point
resp = dataset[7]
any_describe(resp)
print(resp.keys())Initialized dataset robot_sim.PickNPlace with EmbodimentTag.GR1
====================================================================================================
========================================= Humanoid Dataset =========================================
====================================================================================================
{'action.left_hand': 'np: [1, 6] float64',
'action.right_hand': 'np: [1, 6] float64',
'annotation.human.action.task_description': ['pick the squash from the '
'counter and place it in the '
'plate'],
'annotation.human.validity': ['valid'],
'state.left_arm': 'np: [1, 7] float64',
'state.left_hand': 'np: [1, 6] float64',
'state.left_leg': 'np: [1, 6] float64',
'state.neck': 'np: [1, 3] float64',
'state.right_arm': 'np: [1, 7] float64',
'state.right_hand': 'np: [1, 6] float64',
'state.right_leg': 'np: [1, 6] float64',
'state.waist': 'np: [1, 3] float64',
'video.ego_view': 'np: [1, 256, 256, 3] uint8'}
dict_keys(['video.ego_view', 'state.left_arm', 'state.left_hand', 'state.left_leg', 'state.neck', 'state.right_arm', 'state.right_hand', 'state.right_leg', 'state.waist', 'action.left_hand', 'action.right_hand', 'annotation.human.action.task_description', 'annotation.human.validity'])在数据中显示图像帧
# show img
import matplotlib.pyplot as plt
images_list = []
for i in range(100):
if i % 10 == 0:
resp = dataset[i]
img = resp["video.ego_view"][0]
images_list.append(img)
fig, axs = plt.subplots(2, 5, figsize=(20, 10))
for i, ax in enumerate(axs.flat):
ax.imshow(images_list[i])
ax.axis("off")
ax.set_title(f"Image {i}")
plt.tight_layout() # adjust the subplots to fit into the figure area.
plt.show()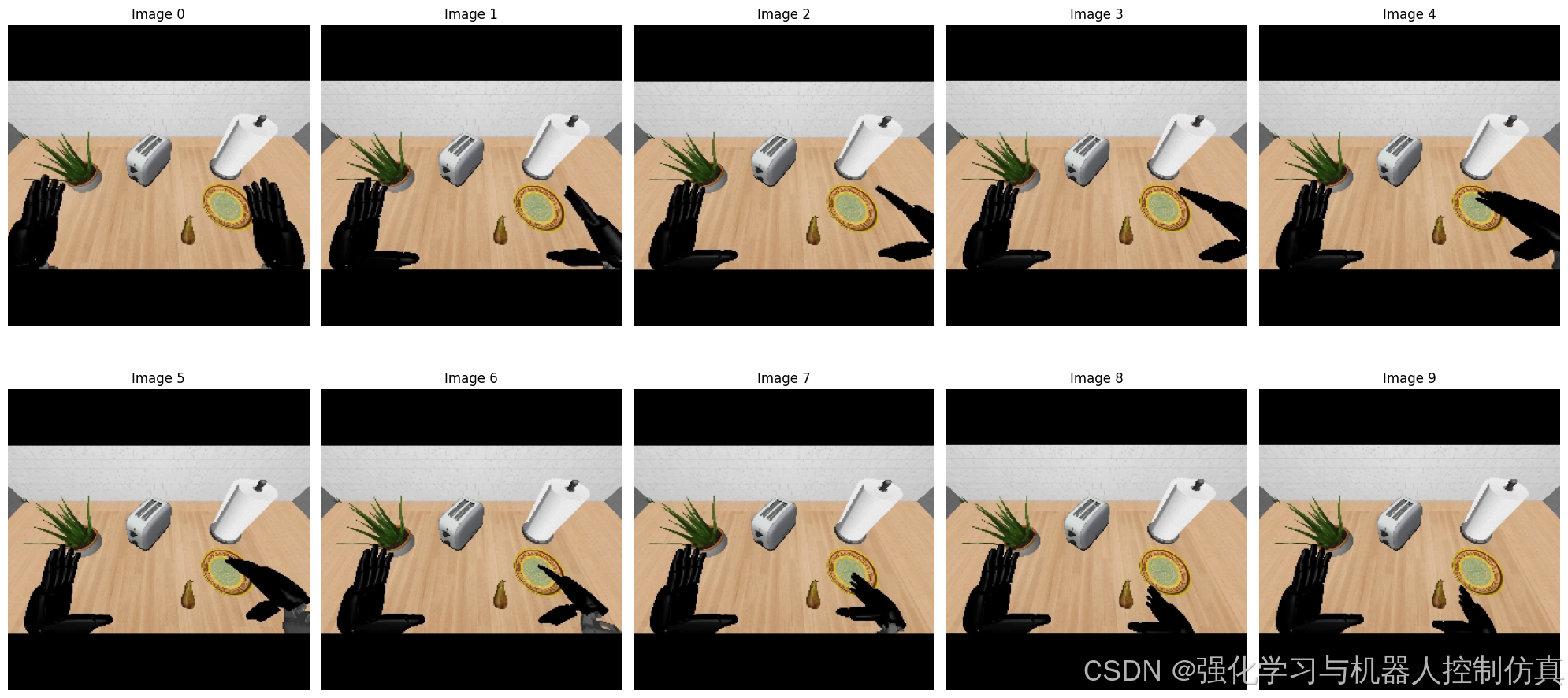
1.2 转换数据
我们还可以对 LeRobotSingleDataset 类中的数据进行一系列转换。下面展示了如何对数据进行转换。
from gr00t.data.transform.base import ComposedModalityTransform
from gr00t.data.transform import VideoToTensor, VideoCrop, VideoResize, VideoColorJitter, VideoToNumpy
from gr00t.data.transform.state_action import StateActionToTensor, StateActionTransform
from gr00t.data.transform.concat import ConcatTransform
video_modality = modality_configs["video"]
state_modality = modality_configs["state"]
action_modality = modality_configs["action"]
# select the transforms you want to apply to the data
to_apply_transforms = ComposedModalityTransform(
transforms=[
# video transforms
VideoToTensor(apply_to=video_modality.modality_keys),
VideoCrop(apply_to=video_modality.modality_keys, scale=0.95),
VideoResize(apply_to=video_modality.modality_keys, height=224, width=224, interpolation="linear"),
VideoColorJitter(apply_to=video_modality.modality_keys, brightness=0.3, contrast=0.4, saturation=0.5, hue=0.08),
VideoToNumpy(apply_to=video_modality.modality_keys),
# state transforms
StateActionToTensor(apply_to=state_modality.modality_keys),
StateActionTransform(apply_to=state_modality.modality_keys, normalization_modes={
key: "min_max" for key in state_modality.modality_keys
}),
# action transforms
StateActionToTensor(apply_to=action_modality.modality_keys),
StateActionTransform(apply_to=action_modality.modality_keys, normalization_modes={
key: "min_max" for key in action_modality.modality_keys
}),
# ConcatTransform
ConcatTransform(
video_concat_order=video_modality.modality_keys,
state_concat_order=state_modality.modality_keys,
action_concat_order=action_modality.modality_keys,
),
]
)现在看看应用转换后的数据有何不同。
例如,对状态和操作进行规范化和串联,对视频图像进行裁剪、调整大小和颜色抖动。
dataset = LeRobotSingleDataset(
DATA_PATH,
modality_configs,
transforms=to_apply_transforms,
embodiment_tag=embodiment_tag
)
# print the 7th data point
resp = dataset[7]
any_describe(resp)
print(resp.keys())
Initialized dataset robot_sim.PickNPlace with EmbodimentTag.GR1
{'action': 'torch: [1, 12] torch.float64 cpu',
'annotation.human.action.task_description': ['pick the squash from the '
'counter and place it in the '
'plate'],
'annotation.human.validity': ['valid'],
'state': 'torch: [1, 44] torch.float64 cpu',
'video': 'np: [1, 1, 224, 224, 3] uint8'}
dict_keys(['annotation.human.action.task_description', 'annotation.human.validity', 'video', 'state', 'action'])二、GR00T 推断
本教程介绍如何使用 GR00T 推理模型,根据测试数据集的观测结果预测行动。
import os
import torch
import gr00t
from gr00t.data.dataset import LeRobotSingleDataset
from gr00t.model.policy import Gr00tPolicy# change the following paths
MODEL_PATH = "nvidia/GR00T-N1-2B"
# REPO_PATH is the path of the pip install gr00t repo and one level up
REPO_PATH = os.path.dirname(os.path.dirname(gr00t.__file__))
DATASET_PATH = os.path.join(REPO_PATH, "demo_data/robot_sim.PickNPlace")
EMBODIMENT_TAG = "gr1"
device = "cuda" if torch.cuda.is_available() else "cpu"2.1 加载预训练策略
策略模型的加载与其他 huggingface 模型一样。
GR00T 模型中有两个新概念:
- 模式配置: 这定义了模型使用的字典中的键。(例如:动作、状态、注释、视频)
- 模态变换(modality_transform): 在数据载入过程中使用的转换序列
from gr00t.experiment.data_config import DATA_CONFIG_MAP
data_config = DATA_CONFIG_MAP["gr1_arms_only"]
modality_config = data_config.modality_config()
modality_transform = data_config.transform()
policy = Gr00tPolicy(
model_path=MODEL_PATH,
embodiment_tag=EMBODIMENT_TAG,
modality_config=modality_config,
modality_transform=modality_transform,
device=device,
)
# print out the policy model architecture
print(policy.model)2.2 加载数据集
首先,用户需要检查哪些体现标签用于预训练 Gr00tPolicy 预训练模型。
import numpy as np
modality_config = policy.modality_config
print(modality_config.keys())
for key, value in modality_config.items():
if isinstance(value, np.ndarray):
print(key, value.shape)
else:
print(key, value)dict_keys(['video', 'state', 'action', 'language'])
video delta_indices=[0] modality_keys=['video.ego_view']
state delta_indices=[0] modality_keys=['state.left_arm', 'state.right_arm', 'state.left_hand', 'state.right_hand']
action delta_indices=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15] modality_keys=['action.left_arm', 'action.right_arm', 'action.left_hand', 'action.right_hand']
language delta_indices=[0] modality_keys=['annotation.human.action.task_description']
# Create the dataset
dataset = LeRobotSingleDataset(
dataset_path=DATASET_PATH,
modality_configs=modality_config,
video_backend="decord",
video_backend_kwargs=None,
transforms=None, # We'll handle transforms separately through the policy
embodiment_tag=EMBODIMENT_TAG,
)Initialized dataset robot_sim.PickNPlace with gr1让我们打印出一个数据并将其可视化
import numpy as np
step_data = dataset[0]
print(step_data)
print("\n\n ====================================")
for key, value in step_data.items():
if isinstance(value, np.ndarray):
print(key, value.shape)
else:
print(key, value)
{'video.ego_view': array([[[[0, 0, 0],
[0, 0, 0],
[0, 0, 0],
...,
[0, 0, 0],
[0, 0, 0],
[0, 0, 0]],
[[0, 0, 0],
[0, 0, 0],
[0, 0, 0],
...,
[0, 0, 0],
[0, 0, 0],
[0, 0, 0]],
[[0, 0, 0],
[0, 0, 0],
[0, 0, 0],
...,
[0, 0, 0],
[0, 0, 0],
[0, 0, 0]],
...,
[[0, 0, 0],
[0, 0, 0],
[0, 0, 0],
...,
[0, 0, 0],
[0, 0, 0],
[0, 0, 0]],
[[0, 0, 0],
[0, 0, 0],
[0, 0, 0],
...,
[0, 0, 0],
[0, 0, 0],
[0, 0, 0]],
[[0, 0, 0],
[0, 0, 0],
[0, 0, 0],
...,
[0, 0, 0],
[0, 0, 0],
[0, 0, 0]]]], dtype=uint8), 'state.left_arm': array([[-0.01147083, 0.12207967, 0.04229397, -2.1 , -0.01441445,
-0.03013532, -0.00384387]]), 'state.right_arm': array([[ 6.74682520e-03, -9.05242648e-02, 8.14010333e-03,
-2.10000000e+00, -2.22802847e-02, 1.40373494e-02,
1.04679727e-03]]), 'state.left_hand': array([[0.00067388, 0.00076318, 0.00084776, 0.00069391, 0.00075118,
0.00485883]]), 'state.right_hand': array([[0.00187319, 0.00216486, 0.002383 , 0.00182536, 0.02100907,
0.01359221]]), 'action.left_arm': array([[-1.07706680e-02, 1.04934344e-01, 4.15936080e-02,
-2.09762367e+00, -1.78164827e-02, -3.33876667e-02,
-9.85330611e-03],
[-7.91579173e-03, 9.78180763e-02, 3.57741932e-02,
-2.09809624e+00, -1.47751639e-02, -2.78760650e-02,
-1.44522492e-02],
[-5.48170464e-03, 8.97774305e-02, 3.09967920e-02,
-2.09854670e+00, -1.20841815e-02, -2.37416655e-02,
-1.86673091e-02],
[-3.23207919e-03, 8.14548305e-02, 2.66160698e-02,
-2.09891412e+00, -9.46781410e-03, -2.01521622e-02,
-2.27768122e-02],
[-1.03295768e-03, 7.30429523e-02, 2.23631483e-02,
-2.09919641e+00, -6.85977069e-03, -1.68003940e-02,
-2.69124769e-02],
[ 1.18218133e-03, 6.45925486e-02, 1.81263910e-02,
-2.09939841e+00, -4.25067524e-03, -1.35736444e-02,
-3.11342315e-02],
[ 4.01225156e-03, 6.74696222e-02, 9.50461084e-03,
-2.08267710e+00, 1.30771244e-02, -2.74863628e-02,
-6.21405030e-03],
[ 5.70485217e-03, 6.30451006e-02, 5.21468384e-03,
-2.07986215e+00, 1.71772091e-02, -2.82865559e-02,
-4.63431140e-03],
[ 7.39730319e-03, 5.89018901e-02, 1.03944234e-03,
-2.07728093e+00, 2.08109612e-02, -2.90521862e-02,
-3.36559193e-03],
[ 9.12183520e-03, 5.53131414e-02, -2.71213219e-03,
-2.07524967e+00, 2.33213483e-02, -2.95806653e-02,
-2.84210159e-03],
[ 1.09992156e-02, 5.22728198e-02, -6.07222726e-03,
-2.07378112e+00, 2.45457848e-02, -2.98420447e-02,
-3.15860443e-03],
[ 1.30662712e-02, 4.97582401e-02, -9.05391049e-03,
-2.07285030e+00, 2.45056922e-02, -2.98503259e-02,
-4.26775116e-03],
[ 1.52062086e-02, 4.77021053e-02, -1.16503113e-02,
-2.07234023e+00, 2.35690492e-02, -2.96972474e-02,
-5.86959074e-03],
[ 1.73108239e-02, 4.59530903e-02, -1.39242263e-02,
-2.07209143e+00, 2.21695462e-02, -2.94920861e-02,
-7.65797543e-03],
[ 1.92511046e-02, 4.44102571e-02, -1.58636369e-02,
-2.07202558e+00, 2.06067592e-02, -2.93277413e-02,
-9.35161262e-03],
[ 2.07126401e-02, 4.32274177e-02, -1.72182433e-02,
-2.07203352e+00, 1.92976598e-02, -2.92817179e-02,
-1.06464981e-02]]), 'action.right_arm': array([[ 2.21627088e-03, -9.37728608e-02, -3.97849900e-02,
-2.06814219e+00, -8.56739215e-02, 5.79283621e-02,
-5.77253327e-02],
[ 4.30219780e-05, -1.04490613e-01, -7.72047014e-02,
-2.04360052e+00, -1.49008809e-01, 9.11731368e-02,
-1.09504733e-01],
[-3.20656176e-03, -1.13106628e-01, -1.10705757e-01,
-2.02076698e+00, -2.06495159e-01, 1.24586380e-01,
-1.55423898e-01],
[-7.43041223e-03, -1.21159332e-01, -1.41850206e-01,
-1.99755448e+00, -2.60498041e-01, 1.59194985e-01,
-1.97590390e-01],
[-1.24604636e-02, -1.29517659e-01, -1.71688775e-01,
-1.97291110e+00, -3.12480586e-01, 1.95620004e-01,
-2.37292811e-01],
[-1.81944020e-02, -1.38630148e-01, -2.00705537e-01,
-1.94634574e+00, -3.63152746e-01, 2.34135045e-01,
-2.75149288e-01],
[ 8.93425381e-02, -4.26527765e-01, -1.26975696e-01,
-1.93934416e+00, 9.87892979e-02, 2.32846570e-01,
-2.87245118e-02],
[ 9.94114267e-02, -4.84456898e-01, -1.19981059e-01,
-1.92916311e+00, 1.56401124e-01, 2.58826792e-01,
-5.84780584e-03],
[ 1.05915501e-01, -5.33586018e-01, -1.09268820e-01,
-1.92013251e+00, 2.07781017e-01, 2.81349765e-01,
1.95781464e-02],
[ 1.05701101e-01, -5.70159727e-01, -9.94966466e-02,
-1.91462445e+00, 2.47525017e-01, 2.97567721e-01,
4.42939261e-02],
[ 9.88279356e-02, -5.93690835e-01, -8.82906547e-02,
-1.91157439e+00, 2.70735239e-01, 3.12278013e-01,
7.16265080e-02],
[ 8.50292359e-02, -6.07675457e-01, -8.17918138e-02,
-1.91183875e+00, 2.81771715e-01, 3.23118613e-01,
1.02626036e-01],
[ 6.71502302e-02, -6.18867876e-01, -7.60968035e-02,
-1.91468068e+00, 2.81581396e-01, 3.40363262e-01,
1.35024227e-01],
[ 4.65002758e-02, -6.27704616e-01, -7.52606241e-02,
-1.91926019e+00, 2.75164718e-01, 3.59271051e-01,
1.67061231e-01],
[ 2.45882211e-02, -6.33134721e-01, -7.88275961e-02,
-1.92399113e+00, 2.61009603e-01, 3.81247479e-01,
1.98397058e-01],
[ 5.03588613e-03, -6.39530345e-01, -8.39274535e-02,
-1.92642545e+00, 2.47624030e-01, 4.06113278e-01,
2.24670301e-01]]), 'action.left_hand': array([[-1.5, -1.5, -1.5, -1.5, -3. , 3. ],
[-1.5, -1.5, -1.5, -1.5, -3. , 3. ],
[-1.5, -1.5, -1.5, -1.5, -3. , 3. ],
[-1.5, -1.5, -1.5, -1.5, -3. , 3. ],
[-1.5, -1.5, -1.5, -1.5, -3. , 3. ],
[-1.5, -1.5, -1.5, -1.5, -3. , 3. ],
[-1.5, -1.5, -1.5, -1.5, -3. , 3. ],
[-1.5, -1.5, -1.5, -1.5, -3. , 3. ],
[-1.5, -1.5, -1.5, -1.5, -3. , 3. ],
[-1.5, -1.5, -1.5, -1.5, -3. , 3. ],
[-1.5, -1.5, -1.5, -1.5, -3. , 3. ],
[-1.5, -1.5, -1.5, -1.5, -3. , 3. ],
[-1.5, -1.5, -1.5, -1.5, -3. , 3. ],
[-1.5, -1.5, -1.5, -1.5, -3. , 3. ],
[-1.5, -1.5, -1.5, -1.5, -3. , 3. ],
[-1.5, -1.5, -1.5, -1.5, -3. , 3. ]]), 'action.right_hand': array([[-1.5, -1.5, -1.5, -1.5, -3. , 3. ],
[-1.5, -1.5, -1.5, -1.5, -3. , 3. ],
[-1.5, -1.5, -1.5, -1.5, -3. , 3. ],
[-1.5, -1.5, -1.5, -1.5, -3. , 3. ],
[-1.5, -1.5, -1.5, -1.5, -3. , 3. ],
[-1.5, -1.5, -1.5, -1.5, -3. , 3. ],
[-1.5, -1.5, -1.5, -1.5, -3. , 3. ],
[-1.5, -1.5, -1.5, -1.5, -3. , 3. ],
[-1.5, -1.5, -1.5, -1.5, -3. , 3. ],
[-1.5, -1.5, -1.5, -1.5, -3. , 3. ],
[-1.5, -1.5, -1.5, -1.5, -3. , 3. ],
[-1.5, -1.5, -1.5, -1.5, -3. , 3. ],
[-1.5, -1.5, -1.5, -1.5, -3. , 3. ],
[-1.5, -1.5, -1.5, -1.5, -3. , 3. ],
[-1.5, -1.5, -1.5, -1.5, -3. , 3. ],
[-1.5, -1.5, -1.5, -1.5, -3. , 3. ]]), 'annotation.human.action.task_description': ['pick the squash from the counter and place it in the plate']}
====================================
video.ego_view (1, 256, 256, 3)
state.left_arm (1, 7)
state.right_arm (1, 7)
state.left_hand (1, 6)
state.right_hand (1, 6)
action.left_arm (16, 7)
action.right_arm (16, 7)
action.left_hand (16, 6)
action.right_hand (16, 6)
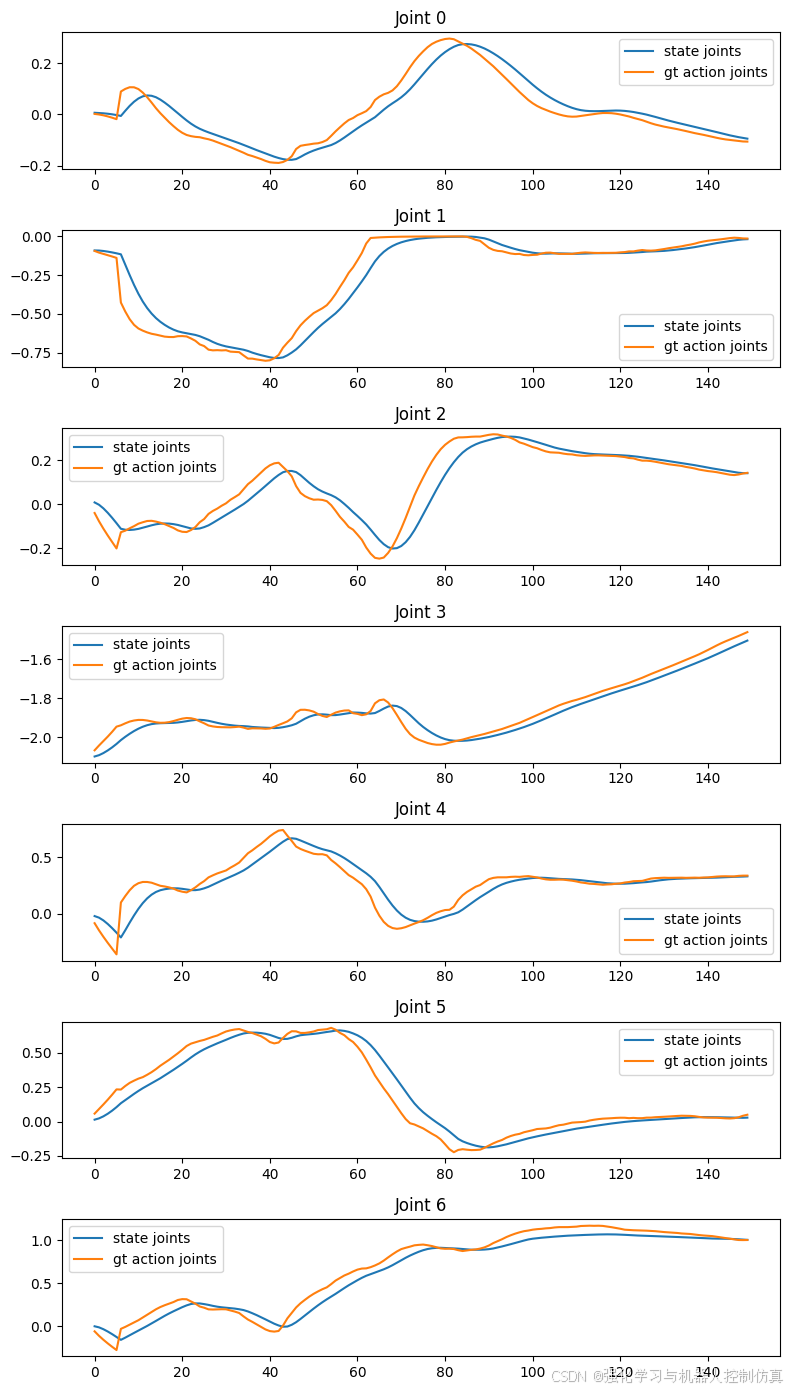
annotation.human.action.task_description ['pick the squash from the counter and place it in the plate']让我们只绘制 “右手 ”状态和动作数据,看看效果如何。同时显示右手状态的图像。
import matplotlib.pyplot as plt
traj_id = 0
max_steps = 150
state_joints_across_time = []
gt_action_joints_across_time = []
images = []
sample_images = 6
for step_count in range(max_steps):
data_point = dataset.get_step_data(traj_id, step_count)
state_joints = data_point["state.right_arm"][0]
gt_action_joints = data_point["action.right_arm"][0]
state_joints_across_time.append(state_joints)
gt_action_joints_across_time.append(gt_action_joints)
# We can also get the image data
if step_count % (max_steps // sample_images) == 0:
image = data_point["video.ego_view"][0]
images.append(image)
# Size is (max_steps, num_joints == 7)
state_joints_across_time = np.array(state_joints_across_time)
gt_action_joints_across_time = np.array(gt_action_joints_across_time)
# Plot the joint angles across time
fig, axes = plt.subplots(nrows=7, ncols=1, figsize=(8, 2*7))
for i, ax in enumerate(axes):
ax.plot(state_joints_across_time[:, i], label="state joints")
ax.plot(gt_action_joints_across_time[:, i], label="gt action joints")
ax.set_title(f"Joint {i}")
ax.legend()
plt.tight_layout()
plt.show()
# Plot the images in a row
fig, axes = plt.subplots(nrows=1, ncols=sample_images, figsize=(16, 4))
for i, ax in enumerate(axes):
ax.imshow(images[i])
ax.axis("off")

现在,我们可以从预训练的检查点运行策略了。
predicted_action = policy.get_action(step_data)
for key, value in predicted_action.items():
print(key, value.shape)The input hidden states seems to be silently casted in float32, this might be related to the fact you have upcasted embedding or layer norm layers in float32. We will cast back the input in torch.bfloat16.
Starting from v4.46, the `logits` model output will have the same type as the model (except at train time, where it will always be FP32)
action.left_arm (16, 7)
action.right_arm (16, 7)
action.left_hand (16, 6)
action.right_hand (16, 6)2.3 了解动作输出
动作输出中的每个关节都有一个 (16, N) 的形状,其中 N 是关节的自由度。
- 16 代表行动范围(时间步 t、t+1、t+2、...、t+15 的预测值)
每只手臂(左臂和右臂)
- 7 个手臂关节
- 肩关节俯仰
- 肩部滚动
- 肩偏航
- 肘关节俯仰
- 腕关节偏航
- 腕滚动
- 腕关节俯仰
每只手(左手和右手)
- 6 个手指关节
- 小指
- 无名指
- 中指
- 食指
- 拇指旋转
- 拇指弯曲
腰部
- 3 个关节
- 躯干腰部偏转
- 躯干腰部俯仰
- 躯干腰部滚动
三、微调
本教程说明了如何使用相同的实施方案,在训练后数据集上对 GR00T-N1 预训练检查点进行微调。这展示了后训练的好处,将通用模型转变为专业模型,并证明了性能的提高。
在本教程中,我们将使用 demo_data 文件夹中的演示数据集 robot_sim.PickNPlace。
我们将首先加载预训练模型,并在数据集上对其进行评估。然后,我们将在数据集上对模型进行微调,并评估其性能。
3.1 预训练模型
from gr00t.utils.eval import calc_mse_for_single_trajectory
import warnings
from gr00t.experiment.data_config import DATA_CONFIG_MAP
from gr00t.model.policy import Gr00tPolicy
from gr00t.data.schema import EmbodimentTag
from gr00t.data.dataset import LeRobotSingleDataset
import numpy as np
import torch
device = "cuda" if torch.cuda.is_available() else "cpu"
warnings.simplefilter("ignore", category=FutureWarning)/home/youliang/miniconda3/envs/groot-release/lib/python3.10/site-packages/albumentations/__init__.py:13: UserWarning: A new version of Albumentations is available: 2.0.5 (you have 1.4.18). Upgrade using: pip install -U albumentations. To disable automatic update checks, set the environment variable NO_ALBUMENTATIONS_UPDATE to 1.
check_for_updates()
2025-03-18 13:27:04.588611: I tensorflow/core/util/port.cc:113] oneDNN custom operations are on. You may see slightly different numerical results due to floating-point round-off errors from different computation orders. To turn them off, set the environment variable `TF_ENABLE_ONEDNN_OPTS=0`.
2025-03-18 13:27:04.610590: E external/local_xla/xla/stream_executor/cuda/cuda_dnn.cc:9261] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered
2025-03-18 13:27:04.610610: E external/local_xla/xla/stream_executor/cuda/cuda_fft.cc:607] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered
2025-03-18 13:27:04.611353: E external/local_xla/xla/stream_executor/cuda/cuda_blas.cc:1515] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered
2025-03-18 13:27:04.615698: I tensorflow/core/platform/cpu_feature_guard.cc:182] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations.
To enable the following instructions: AVX2 AVX_VNNI FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags.
2025-03-18 13:27:04.959771: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Could not find TensorRTPRE_TRAINED_MODEL_PATH = "nvidia/GR00T-N1-2B"
EMBODIMENT_TAG = EmbodimentTag.GR1
DATASET_PATH = "../demo_data/robot_sim.PickNPlace"
data_config = DATA_CONFIG_MAP["gr1_arms_only"]
modality_config = data_config.modality_config()
modality_transform = data_config.transform()
pre_trained_policy = Gr00tPolicy(
model_path=PRE_TRAINED_MODEL_PATH,
embodiment_tag=EMBODIMENT_TAG,
modality_config=modality_config,
modality_transform=modality_transform,
device=device,
)
dataset = LeRobotSingleDataset(
dataset_path=DATASET_PATH,
modality_configs=modality_config,
video_backend="decord",
video_backend_kwargs=None,
transforms=None, # We'll handle transforms separately through the policy
embodiment_tag=EMBODIMENT_TAG,
)
mse = calc_mse_for_single_trajectory(
pre_trained_policy,
dataset,
traj_id=0,
modality_keys=["right_arm", "right_hand"], # we will only evaluate the right arm and right hand
steps=150,
action_horizon=16,
plot=True
)
print("MSE loss for trajectory 0:", mse)Fetching 6 files: 0%| | 0/6 [00:00<?, ?it/s]
Loading pretrained dual brain from /home/youliang/.cache/huggingface/hub/models--nvidia--GR00T-N1-2B/snapshots/32e1fd2507f7739fad443e6b449c8188e0e02fcb
Tune backbone vision tower: True
Tune backbone LLM: False
Tune action head projector: True
Tune action head DiT: True
Model not found or avail in the huggingface hub. Loading from local path: /home/youliang/.cache/huggingface/hub/models--nvidia--GR00T-N1-2B/snapshots/32e1fd2507f7739fad443e6b449c8188e0e02fcb
Total number of DiT parameters: 537803776
Tune action head projector: True
Tune action head diffusion model: True
Some weights of the model checkpoint at /home/youliang/.cache/huggingface/hub/models--nvidia--GR00T-N1-2B/snapshots/32e1fd2507f7739fad443e6b449c8188e0e02fcb were not used when initializing GR00T_N1: ['action_head.decode_layer.bias', 'action_head.decode_layer.weight']
- This IS expected if you are initializing GR00T_N1 from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing GR00T_N1 from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
Tune action head projector: True
Tune action head diffusion model: True
Initialized dataset robot_sim.PickNPlace with EmbodimentTag.GR1
inferencing at step: 0
The input hidden states seems to be silently casted in float32, this might be related to the fact you have upcasted embedding or layer norm layers in float32. We will cast back the input in torch.bfloat16.
Starting from v4.46, the `logits` model output will have the same type as the model (except at train time, where it will always be FP32)
inferencing at step: 16
inferencing at step: 32
inferencing at step: 48
inferencing at step: 64
inferencing at step: 80
inferencing at step: 96
inferencing at step: 112
inferencing at step: 128
inferencing at step: 144
Unnormalized Action MSE across single traj: 3.6764835882576428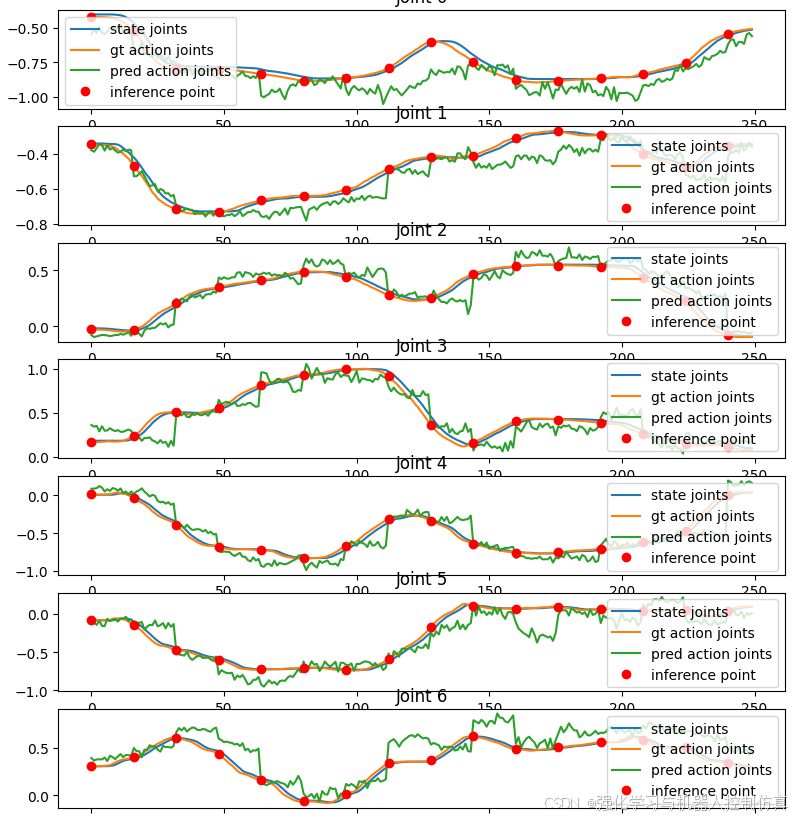
很好!我们可以看到预测行动和地面实况行动。预测的行动并不完美,但与地面实况行动很接近。这表明预训练的检查点运行良好。
现在,让我们对 10 个随机轨迹进行采样,计算平均 MSE,以获得更详细的结果。
total_trajectories = len(dataset.trajectory_lengths)
print("Total trajectories:", total_trajectories)
sampled_trajectories = np.random.choice(total_trajectories, 10)
print("Sampled trajectories:", sampled_trajectories)
all_mses = []
for traj_id in sampled_trajectories:
mse = calc_mse_for_single_trajectory(
pre_trained_policy,
dataset,
traj_id=traj_id,
modality_keys=["right_arm", "right_hand"], # we will only evaluate the right arm and right hand
steps=150,
action_horizon=16,
plot=False
)
print(f"Trajectory {traj_id} MSE: {mse:.4f}")
all_mses.append(mse)
print("====================================")
print("Mean MSE:", np.mean(all_mses))
print("Std MSE:", np.std(all_mses))
Total trajectories: 5
Sampled trajectories: [2 1 0 1 3 2 3 0 4 3]
inferencing at step: 0
inferencing at step: 16
inferencing at step: 32
inferencing at step: 48
inferencing at step: 64
inferencing at step: 80
inferencing at step: 96
inferencing at step: 112
inferencing at step: 128
inferencing at step: 144
Unnormalized Action MSE across single traj: 3.20396729700109
Trajectory 2 MSE: 3.2040
inferencing at step: 0
inferencing at step: 16
inferencing at step: 32
inferencing at step: 48
inferencing at step: 64
inferencing at step: 80
inferencing at step: 96
inferencing at step: 112
inferencing at step: 128
inferencing at step: 144
Unnormalized Action MSE across single traj: 2.2953596460669803
Trajectory 1 MSE: 2.2954
inferencing at step: 0
inferencing at step: 16
inferencing at step: 32
inferencing at step: 48
inferencing at step: 64
inferencing at step: 80
inferencing at step: 96
inferencing at step: 112
inferencing at step: 128
inferencing at step: 144
Unnormalized Action MSE across single traj: 4.289567449236214
Trajectory 0 MSE: 4.2896
inferencing at step: 0
inferencing at step: 16
inferencing at step: 32
inferencing at step: 48
inferencing at step: 64
inferencing at step: 80
inferencing at step: 96
inferencing at step: 112
inferencing at step: 128
inferencing at step: 144
Unnormalized Action MSE across single traj: 2.8355197990968897
Trajectory 1 MSE: 2.8355
inferencing at step: 0
inferencing at step: 16
inferencing at step: 32
inferencing at step: 48
inferencing at step: 64
inferencing at step: 80
inferencing at step: 96
inferencing at step: 112
inferencing at step: 128
inferencing at step: 144
Unnormalized Action MSE across single traj: 2.7388654553913465
Trajectory 3 MSE: 2.7389
inferencing at step: 0
inferencing at step: 16
inferencing at step: 32
inferencing at step: 48
inferencing at step: 64
inferencing at step: 80
inferencing at step: 96
inferencing at step: 112
inferencing at step: 128
inferencing at step: 144
Unnormalized Action MSE across single traj: 3.007079749042383
Trajectory 2 MSE: 3.0071
inferencing at step: 0
inferencing at step: 16
inferencing at step: 32
inferencing at step: 48
inferencing at step: 64
inferencing at step: 80
inferencing at step: 96
inferencing at step: 112
inferencing at step: 128
inferencing at step: 144
Unnormalized Action MSE across single traj: 2.374824835012358
Trajectory 3 MSE: 2.3748
inferencing at step: 0
inferencing at step: 16
inferencing at step: 32
inferencing at step: 48
inferencing at step: 64
inferencing at step: 80
inferencing at step: 96
inferencing at step: 112
inferencing at step: 128
inferencing at step: 144
Unnormalized Action MSE across single traj: 3.4457704221466785
Trajectory 0 MSE: 3.4458
inferencing at step: 0
inferencing at step: 16
inferencing at step: 32
inferencing at step: 48
inferencing at step: 64
inferencing at step: 80
inferencing at step: 96
inferencing at step: 112
inferencing at step: 128
inferencing at step: 144
Unnormalized Action MSE across single traj: 4.591438530501049
Trajectory 4 MSE: 4.5914
inferencing at step: 0
inferencing at step: 16
inferencing at step: 32
inferencing at step: 48
inferencing at step: 64
inferencing at step: 80
inferencing at step: 96
inferencing at step: 112
inferencing at step: 128
inferencing at step: 144
Unnormalized Action MSE across single traj: 3.7617346859045115
Trajectory 3 MSE: 3.7617
====================================
Mean MSE: 3.2544127869399504
Std MSE: 0.73154719090131093.2 微调模型
现在我们将在数据集上对模型进行微调。在不详细介绍微调过程的前提下,我们将使用 gr00t_finetune.py 脚本对模型进行微调。您可以运行以下命令对模型进行微调。
python scripts/gr00t_finetune.py --dataset-path ./demo_data/robot_sim.PickNPlace --num-gpus 1 --max-steps 500 --output-dir /tmp/gr00t-1/finetuned-model --data-config gr1_arms_only要获得可用参数的完整列表,可以运行 python scripts/gr00t_finetune.py --help 命令。
脚本会将微调后的模型保存在 /tmp/gr00t-1/finetuned-model 目录中。我们将加载包含 500 个检查点步骤的微调模型。
3.2.1 评估微调模型
现在,我们可以通过在数据集上运行策略来评估微调模型,看看它的性能如何。我们将使用效用函数来评估数据集上的策略。这与之前在 1_pretrained_model.ipynb 中的教程类似
from gr00t.utils.eval import calc_mse_for_single_trajectory
import warnings
finetuned_model_path = "/tmp/gr00t-1/finetuned-model/checkpoint-500"
finetuned_policy = Gr00tPolicy(
model_path=finetuned_model_path,
embodiment_tag="new_embodiment",
modality_config=modality_config,
modality_transform=modality_transform,
device=device,
)
warnings.simplefilter("ignore", category=FutureWarning)
mse = calc_mse_for_single_trajectory(
finetuned_policy,
dataset,
traj_id=0,
modality_keys=["right_arm", "right_hand"], # we will only evaluate the right arm and right hand
steps=150,
action_horizon=16,
plot=True
)
print("MSE loss for trajectory 0:", mse)Model not found or avail in the huggingface hub. Loading from local path: /tmp/gr00t-1/finetuned-model-1/checkpoint-500
Loading pretrained dual brain from /tmp/gr00t-1/finetuned-model-1/checkpoint-500
Tune backbone vision tower: True
Tune backbone LLM: False
Tune action head projector: True
Tune action head DiT: True
Model not found or avail in the huggingface hub. Loading from local path: /tmp/gr00t-1/finetuned-model-1/checkpoint-500
Total number of DiT parameters: 537803776
Tune action head projector: True
Tune action head diffusion model: True
Loading checkpoint shards: 100%|██████████| 2/2 [00:00<00:00, 3.07it/s]
Tune action head projector: True
Tune action head diffusion model: True
inferencing at step: 0
inferencing at step: 16
inferencing at step: 32
inferencing at step: 48
inferencing at step: 64
inferencing at step: 80
inferencing at step: 96
inferencing at step: 112
inferencing at step: 128
inferencing at step: 144
Unnormalized Action MSE across single traj: 0.005610098706850138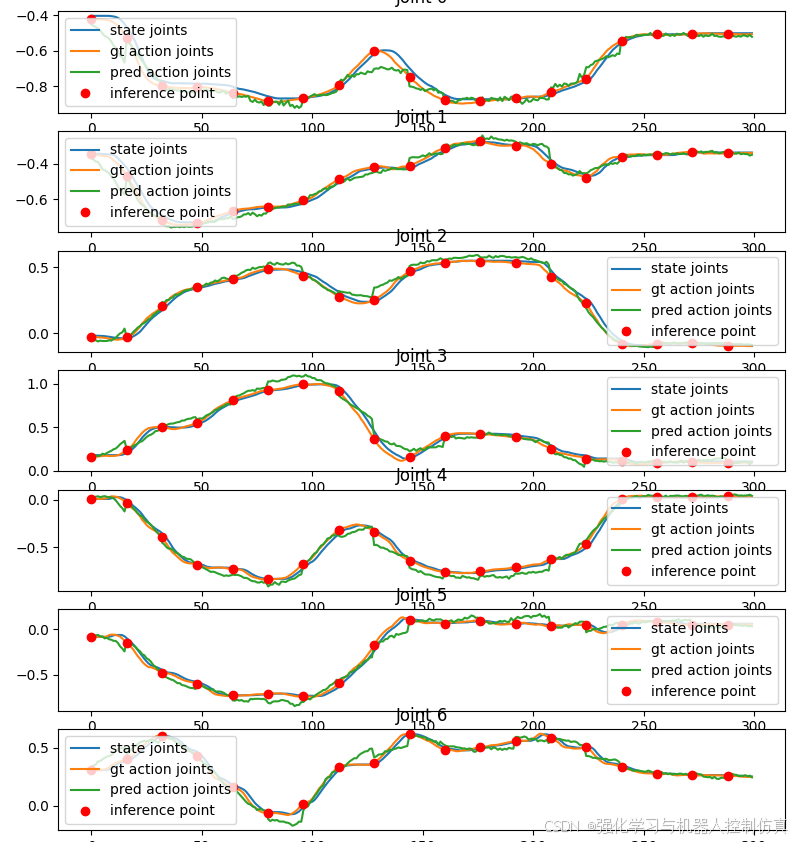
耶!我们对模型进行了微调,并在数据集上对其进行了评估。我们可以看到,模型已经学会了这项任务,并且比预先训练好的模型能更好地完成任务。

















 1481
1481

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









