







GPU中有两种类型的内存:
- 板载内存
- 片上内存
全局内存是较大的板载内存,延迟相对较高;共享内存是较小的片上内存,具有相对较低的延迟。共享内存的常用用途:
- 块内线程的通信通道
- 全局内存数据的可编程管理缓存
- 高速暂存存储器,用于转换数据以优化全局内存访问模式
共享内存
每个SM都有一个小的低延迟内存池,这个内存池被该SM执行的线程块中的所有线程共享。
每个线程块开始时,会分配给它一定数量的共享内存。这个共享内存的地址空间被线程块中所有的线程共享。它的内容和创建时所在的线程块具有相同的生命周期。
如果多个线程访问共享内存中的同一个字,一个线程读取该字后,通过多播把它发送给其他线程。
共享内存分配
可以静态或者动态的分配共享内存变量。
共享内存变量用以下修饰符声明:
__shared__如果在核函数内部声明,那么这个变量的作用域就局限在该内核中。如果在文件的任何核函数外进行声明,那么这个变量的作用域对所有核函数来说都是全局的。
如果一个共享内存的大小在编译时是未知的,可以用extern关键字声明一个未知大小的数组。例如,
extern __shared__ int a[];这个数组大小是未知的,所以在每个核函数被调用时,需要动态分配共享内存,将所需的大小按字节数作为三个尖括号内的第三个参数
kernal<<<grid,block,n*sizeof(int)>>>(...)只能动态声明一维数组。
共享内存存储体和访问模式
优化内存性能时,要度量的两个关键属性是:延迟和带宽。共享内存可以用来隐藏全局内存延迟和带宽对性能的影响。
内存存储体
为了获得高内存带宽,共享内存被分为32个同样大小的内存模型,它们被称为存储体,可以被同事访问(因为一个线程束内有32个线程)。
根据GPU的计算能力,共享内存的地址在不同模式下会映射到不同的存储体中。
存储体冲突
在共享内存中,当多个地址请求落在相同的内存存储体上时,就会发生存储体冲突。存储体冲突会将并行内存事务,变成顺序执行,降低性能。
在线程数发出共享内存请求时,有三种典型的模式:
- 并行访问:多个地址访问多个存储体
- 串行访问:多个地址访问同一个存储体
- 广播访问:单一地址读取单一存储体
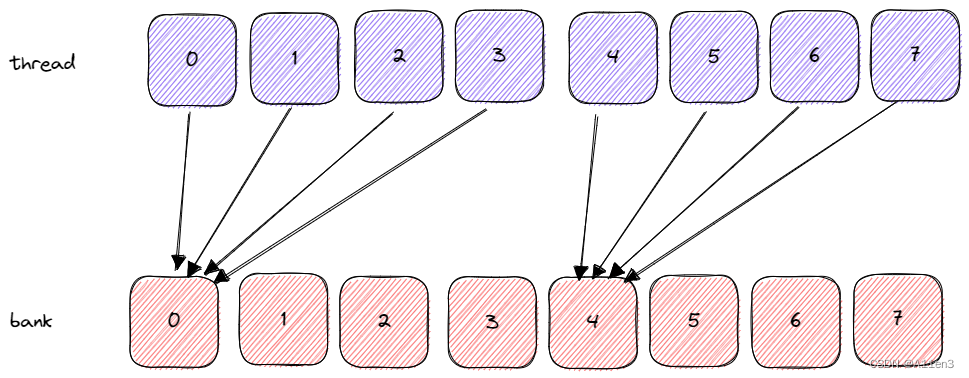
如图所示,不同的线程访问了同一个存储体。对于这样的请求,会产生两种可能得行为:
- 线程访问同一存储体中的相同地址,广播访问无冲突
- 线程访问同一存储体中的不同地址,会发生存储体冲突
访问模式
共享内存存储体的宽度规定了共享内存地址与共享内存存储体的对应关系。内存存储体的宽度随设备计算能力不同而变化:
- 计算能力2.x的设备中为4字节,32位
- 计算能力3.x的设备中为8字节,64位
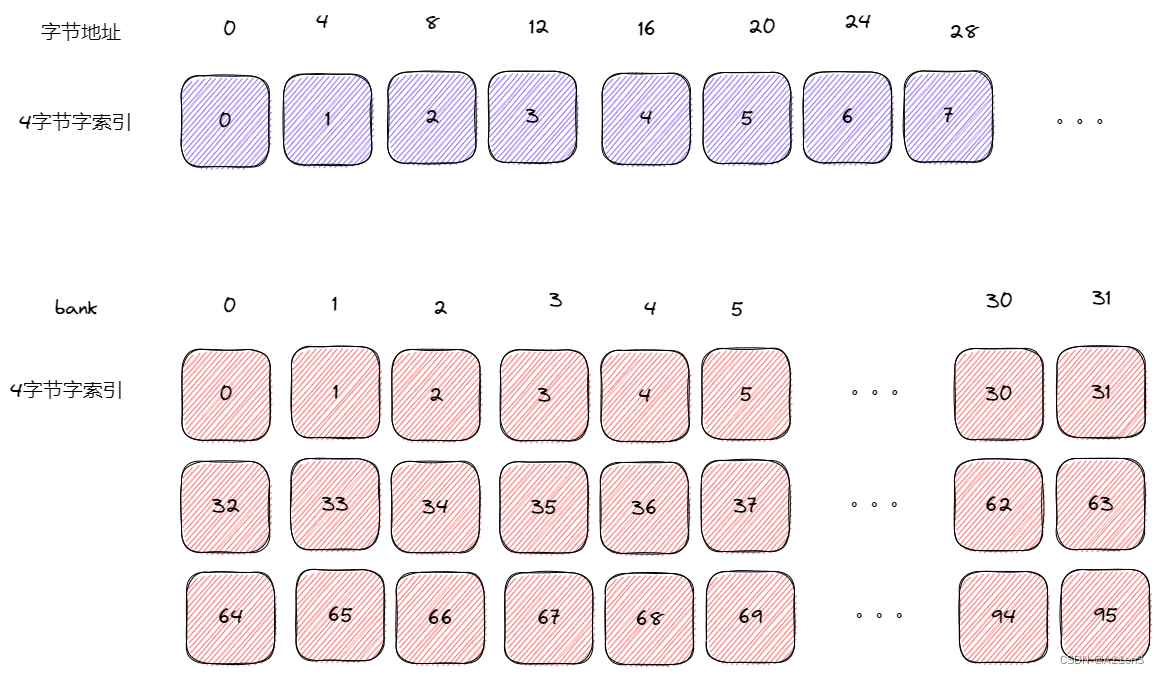
对费米设备,存储体宽度是32位,并且有32个存储体。从共享内存地址到存储体的映射可以按如下计算
存储体索引=(字节地址/4)%32
对于开普勒设备,共享内存有32个存储体,有两种地址模式
- 64位模式
- 32位模式
64位模式存储体冲突更少。
内存填充
内存填充是避免存储体冲突的一种方法。、
画个图说明如何通过内存填充来避免存储体冲突。
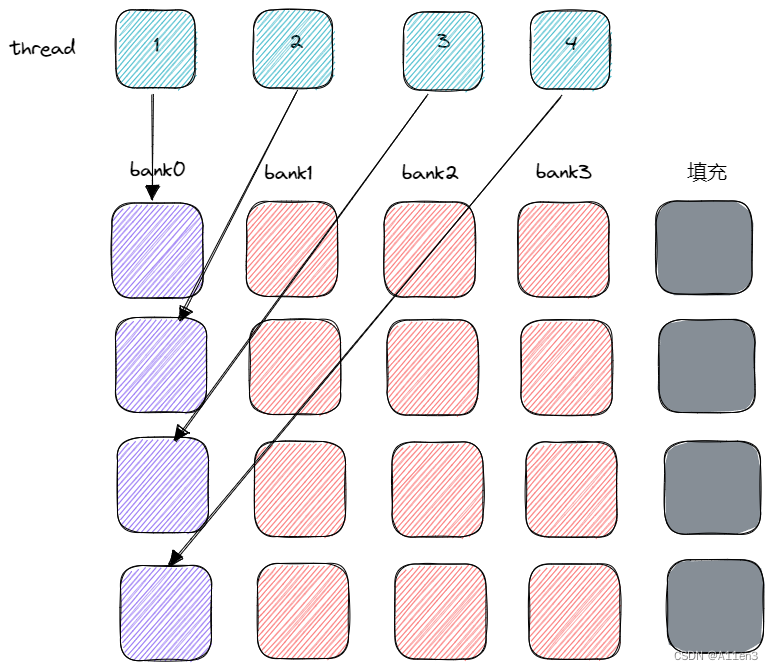
假设有4个存储体,所有线程都访问bank0的四个不同的地址,造成了四向的存储体冲突。解决这种冲突的一个方法是在每N个元素之后添加一个字,N是存储体数量。
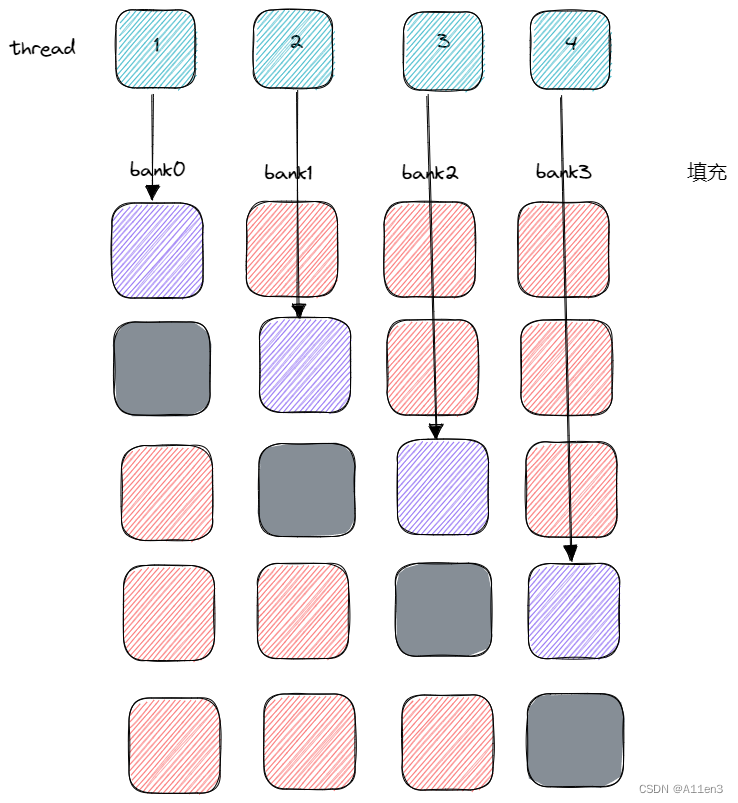
现在,之前所有属于bank0的字都移动到了其他bank中。填充的内存不能用于存储数据,只能用来移动数据。
注意,需要重新计算数组索引以访问正确的数据;并且在不同架构的设备中,填充可能造成的影响不同。
配置共享内存量
每个SM都有64KB的片上内存,共享内存和一级缓存共享该硬件资源。CUDA为配置一级缓存和共享内存的大小提供了两种方法:
- 按设备配置
- 按核函数配置
典型的情况如下
- 核函数使用较多的共享内存时,倾向于分配更多的共享内存
- 核函数使用较多的寄存器时,倾向于分配更多的一级缓存
同步
弱排序内存模型
内存的访问不一定按照它们在程序中出现的顺序进行。
GPU线程在不同内存中写入数据的顺序不一定和这些数据在源代码中访问的顺序相同。
为了显式的强制程序以一个确切的顺序执行,必须在应用程序代码中插入内存栅栏和障碍。这是保证与其他线程共享资源的核函数行为正确的唯一途径。
显式障碍
在CUDA中,障碍只能在同一线程块的线程间执行。在核函数中,调用以下函数来指定一个障碍点
void __syncthreads();它要求块中的所有线程必须等待直到所有线程都到达该点。并且保证在障碍点前,被这些线程访问的所有全局和共享内存对同一块中的所有线程都可见。
内存栅栏
内存栅栏的功能可以确保栅栏前的任何内存写操作对栅栏后的其他线程都是可见的。根据所需范围,有三种内存栅栏:块,网格或系统。
void __threadfence_block();在线程块内创建内存栅栏。
void __threadfence();网格级内存栅栏,挂起调用的线程,直到全局内存中的所有写操作对相同网格内的所有线程都是可见的。也就是开始__threadfence()后面的操作必须等到所有线程都完成__threadfence()之前的操作。
void __threadfence_system();保证该线程在全局内存、锁页主机内存和其他设备内存中的所有写操作对全部设备中的线程和主机线程可见。
volatile修饰符
在全局或共享内存中使用volatile修饰符声明一个变量,可以防止编译器优化,编译器优化可能会将数据暂时存在寄存器或本地内存中。使用volatile修饰符时,编译器假定其他任何线程在任何时间都可以更改或使用该变量的值。也就是说,这个值的修改会立即在全局或共享内存中执行,忽略缓存。















 502
502

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









