







cuda—共享内存
1.sharedMemPerBlock 指示了block中最大可用的共享内存,所以可以使得 block 内的threads可以相互通信。sharedMemPerBlock 的应用例子如下面两张图所示:
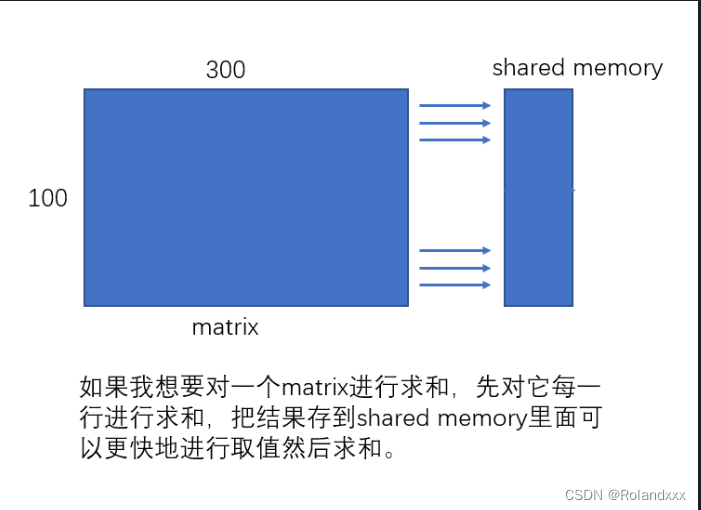
2.共享内存是片上内存,更靠近计算单元,因此比globalMem速度更快,通常可以充当缓存使用。
数据先读入到sharedMem,做各类计算时,使用sharedMem而非globalMem
3.demo_kernel<<<1, 1, 12, nullptr>>>();其中第三个参数12,是指定动态共享内存dynamic_shared_memory的大小
1)dynamic_shared_memory变量必须使用extern __shared__开头
2)并且定义为不确定大小的数组[]
3)12的单位是bytes,也就是可以安全存放3个float
4)变量放在函数外面和里面都一样
5)其指针由cuda调度器执行时赋值
4.static_shared_memory作为静态分配的共享内存
1)不加extern,以__shared__开头
2)定义时需要明确数组的大小
3)静态分配的地址比动态分配的地址低
5.动态共享变量,无论定义多少个,地址都一样
6.静态共享变量,定义几个地址随之叠加
7.如果配置的各类共享内存总和大于sharedMemPerBlock,则核函数执行出错,Invalid argument
1)不同类型的静态共享变量定义,其内存划分并不一定是连续的
2)中间会有内存对齐策略,使得第一个和第二个变量之间可能存在空隙
3)因此你的变量之间如果存在空隙,可能小于全部大小的共享内存就会报错















 1235
1235











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









