






 本文详细介绍了如何在StableDiffusion中使用图生图技术实现真人漫改,包括图片上传、参数设置(如重绘强度)、提示词编写,以及选择合适的二次元大模型。作者强调了后期处理的重要性,并讨论了AIGC技术的前景。
本文详细介绍了如何在StableDiffusion中使用图生图技术实现真人漫改,包括图片上传、参数设置(如重绘强度)、提示词编写,以及选择合适的二次元大模型。作者强调了后期处理的重要性,并讨论了AIGC技术的前景。
大家好,我是小梁子。
所谓真人漫改,就是把一张真人的图片生成一张新的二次元的图片,在Stable Diffusion中,有很多方式实现,其中通过图生图的方式是最常用的方式,大概1-3分钟就可以完成。在Stable Diffusion:图生图基础,中曾详细讲解过具体实现,本文我们再系统的讲解一下。



下面我们来详细看一下图生图实现真人漫改的具体实现方式。
【第一步】:图生图图片上传以及相关参数设置
在图生图功能菜单界面,我们选择【图生图】上传一张我们需要漫改的真人照片。
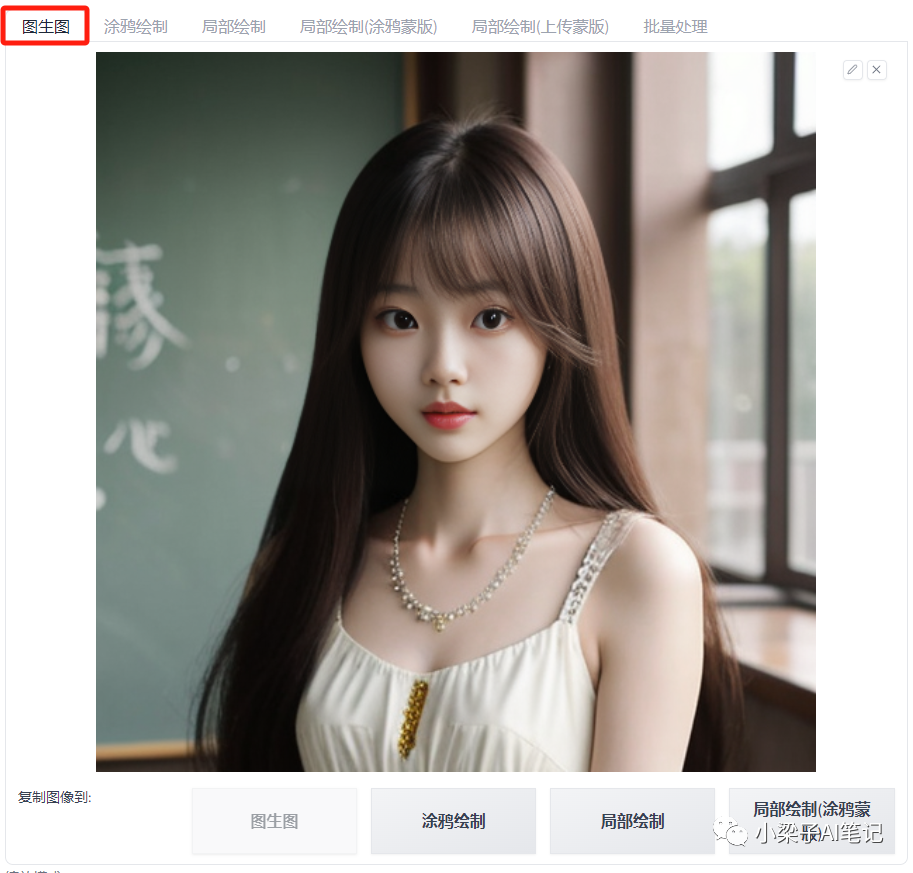
下面进行相关参数设置。
-
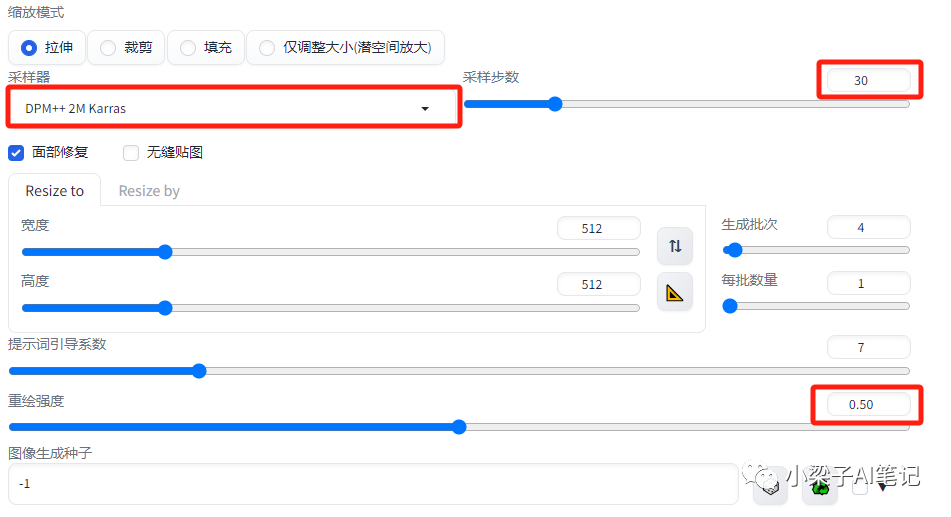
采样器:DPM++2M Karras
-
采样迭代步数:30
-
图片宽高:保持和上传的图片宽高一致或者定比例的放大或者缩小。
-
重绘强度:建议设置在0.45-0.65之间,这个参数值并不是固定的,在实际使用过程中可以多尝试不同的重绘强度值,这里可以使用脚本插件的方式一次生成不同重绘强度值的多张图片。(重绘强度是图生图最重要的一个参数设置,用于控制生成的图片和原来的图片的相似度有多大。它的取值范围为0-1,默认值0.75。值越小,和原来的图片相似度越高,AI自由发挥的空间也越小。值越大,和原来的图片相似度越低,AI自由发挥的空间也越大)。
【第二步】提示词的编写
如果我们知道上传图片的提示词,可以直接将图片的提示词复制过来。
如果我们不知道上传图片的提示词,可以看之前的文章【Stable Diffusion:图片信息获取】。这里推荐使用Tagger插件的方式获取,因为生成提示词效果较好。
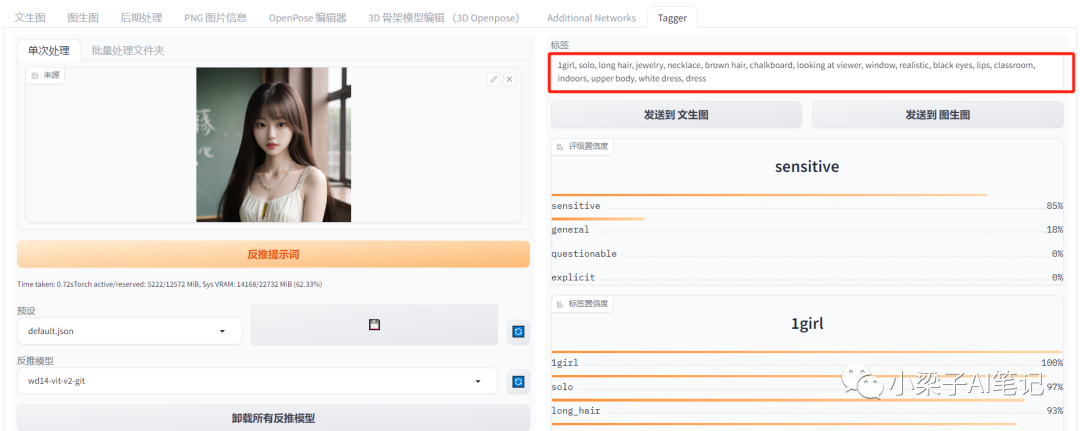
通过Tagger插件获取的提示词为:
1girl, solo, long hair, jewelry, necklace, brown hair, chalkboard, looking at viewer, window, realistic, black eyes, lips, classroom, indoors, upper body, white dress, dress
因为我们需要真人漫改生成对应的二次元图片,我们要检查一下提示词,建议使用翻译软件把提示词翻译出来详细检查一遍,把不符合要求的提示词去掉,比如这里提示词realistic(逼真)就需要拿掉。
最终的提示词:
1girl, solo, long hair, jewelry, necklace, brown hair, chalkboard, looking at viewer, window, black eyes, lips, classroom, indoors, upper body, white dress,dress(女孩,solo,长发,珠宝,项链,棕色头发,黑板,看着观众,窗户,黑眼睛,嘴唇,教室,室内,上身,白色连衣裙,连衣裙)
【第三步】大模型的选择以及图片的生成
真人漫改需要生成二次元的图片,所以大模型需要选择二次元的大模型。
这里我们选择不同的二次元大模型来看一下效果。
原图

大模型:Anything v5 Prt

大模型:Counterfeit V3.0

大模型:Cetus-Mix Coda2

大模型:MeinaUnreal V3

关于真人漫改的图生图实现方式大家按照上面的操作步骤实现即可。
相关说明:
(1)在上面的真人漫改中,如果美女带有首饰等,漫改图片中变化还是比较大。一般真人漫改主要的关注点还是人,我们可以在提示词中将首饰等关键词去掉,当然这个还是要根据实际情况而定。
(2)真人漫改,大模型一定要选择二次元的大模型,但是可供选择的还是比较多的,大家可以根据自己的需求选择,在之前的文章中给大家详细介绍过常用的10几种动漫大模型。
(3)漫改后的图片一般效果并不是很理想,大家需要后期进行处理,最直接的方式是借助SD Web UI的后期处理功能。其中缩放比例设置为4,缩放算法选择:R-ESRGAN_4x+ Anime6B。
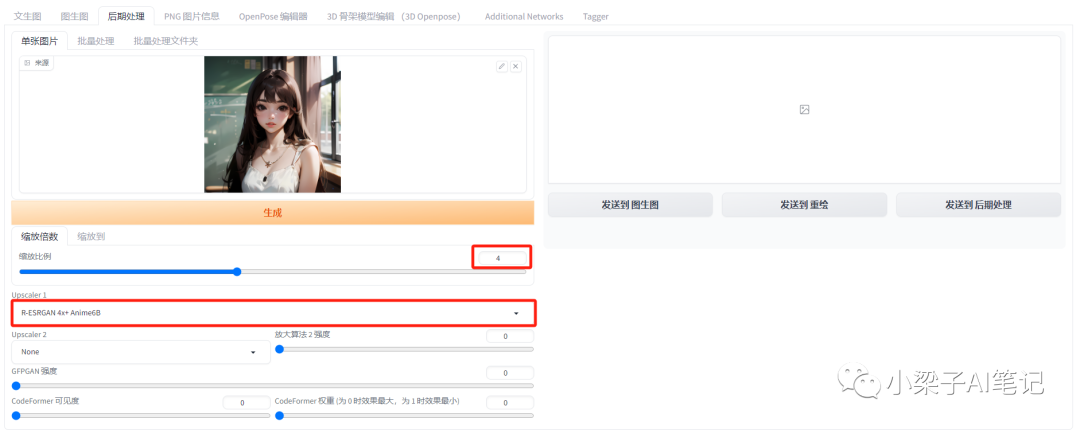
我们看一下未进行和进行过后期处理后图片的效果差异。(左边图片是未处理的,右边图片是经过后期处理的)


在本文中,最终生成的图片我都采用了后期处理。
好了,今天的分享就到这里了,关于真人漫改还有一些其他的实现方式,后面我们会继续分享,希望今天分享的内容对大家有所帮助。
文章使用的大模型、Lora模型、SD插件、示例图片等,都已经上传到我整理的 Stable Diffusion 绘画资源中。有需要的小伙伴文末扫码自行获取。
写在最后
全套AI实用插件已打包,有需要的小伙伴可以自取,无偿分享。


AIGC技术的未来发展前景广阔,随着人工智能技术的不断发展,AIGC技术也将不断提高。未来,AIGC技术将在游戏和计算领域得到更广泛的应用,使游戏和计算系统具有更高效、更智能、更灵活的特性。同时,AIGC技术也将与人工智能技术紧密结合,在更多的领域得到广泛应用,对程序员来说影响至关重要。未来,AIGC技术将继续得到提高,同时也将与人工智能技术紧密结合,在更多的领域得到广泛应用。
感兴趣的小伙伴,赠送全套AIGC学习资料和安装工具,包含AI绘画、AI人工智能等前沿科技教程,模型插件,具体看下方。

一、AIGC所有方向的学习路线
AIGC所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、AIGC必备工具
工具都帮大家整理好了,安装就可直接上手!

三、最新AIGC学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。


四、AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
若有侵权,请联系删除

















 1613
1613

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









