






Stable Diffuison(以下简称SD)这款AI工具,潜力无限,之前介绍过能用来画插画、二维码、数字人、换脸、动画等,今天我又发现SD还能用来快速扩展图片,只需几步,1分钟就能上手,快随我去看看吧~
文章使用的AI绘画SD整合包、各种模型插件、提示词、AI人工智能学习资料都已经打包好放在网盘中了,无需自行查找,。有需要的小伙伴文末扫码自行获取。

准备工作
安装超级简单,跟着我的步骤一步步来就好:
第一步,确保已经在电脑上安装并运行SD的Webui界面。
①想要自己本地部署的朋友,可以翻看我之前分享的文章。
②推荐:我也准备了由其他大神整合的免部署解压即用的安装包(推荐B站秋叶aaaki的整合包),无需自行查找,文末扫码我直接发你。
第二步,下载必备模型文件control_v11p_sd15_inpaint.pth(这个文件没有在整合包中,文末附下载哦),并放置在extensions\sd-webui-controlnet\models中。
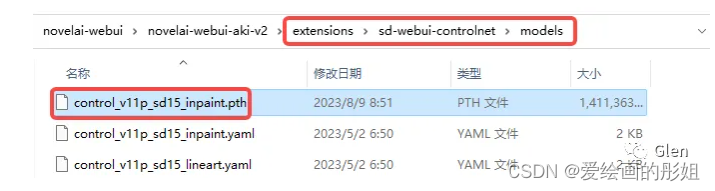
至此,准备工作已完成。
开始扩图
启动SD web ui,在文生图界面,选择一张你喜欢的图片,输入提示词和反向提示词,并配置采样方法、迭代步骤等。
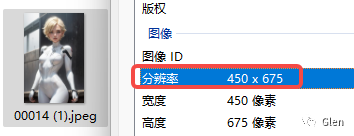
查询图片的宽度和高度(非常关键),右键查看属性即可查询,比如我上传的案例图是450*675。
固定一项,然后扩展另一项,比如我这里先固定了宽度是450,然后高度是1280,即把图片的高度从675扩展到了1280。
 接下来配置ControlNet:
接下来配置ControlNet:
-
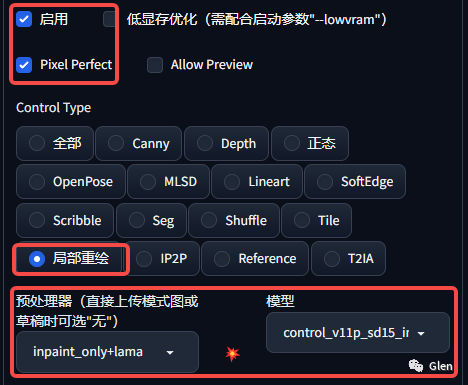
启用ControlNet单元0,勾选“启用”和“Pixel Perfect”
-
Control Type:局部重绘
-
预处理器:inpaint_only+lama
-
模型:control_v11p_sd15_inpaint
-
Control Mode:选择ControlNet is more important
-
画面缩放模式:选择Resize and Fill
之后点击“生成”按钮,等待片刻即可,下图为扩展了高度的效果。

之后再以高度扩展后的图为基础,进行宽度扩展,将生成的图片尺寸改为1280*1280,即可获得效果更好的扩展图片:

SD作为AI绘图的神器,还有很多潜力可以挖掘,我也会持续研究并分享给大家。感兴趣的朋友快去试试吧,记得关注并三连支持下哦!
文章使用的AI绘画SD整合包、各种模型插件、提示词、AI人工智能学习资料都已经打包好放在网盘中了,无需自行查找,。有需要的小伙伴文末扫码自行获取。
关于AI绘画技术储备
学好 AI绘画 不论是就业还是做副业赚钱都不错,但要学会 AI绘画 还是要有一个学习规划。最后大家分享一份全套的 AI绘画 学习资料,给那些想学习 AI绘画 的小伙伴们一点帮助!
对于0基础小白入门:
如果你是零基础小白,想快速入门AI绘画是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以找到适合自己的学习方案
包括:stable diffusion安装包、stable diffusion0基础入门全套PDF,视频学习教程。带你从零基础系统性的学好AI绘画!

零基础AI绘画学习资源介绍
👉stable diffusion新手0基础入门PDF👈
(全套教程文末领取哈)

👉AI绘画必备工具👈

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉AI绘画基础+速成+进阶使用教程👈
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉12000+AI关键词大合集👈

这份完整版的AI绘画全套学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

















 3357
3357

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









