






stable diffusion是一款非常强大的开源人工智能绘画软件,仅使用提示词就能做出很精美的图画。比如我让他画一辆清晨停在停车场的兰博基尼跑车,就得到了以下画面:

当然实际上并没有这么简单,想要让stable diffusion画出高质量的图片,需要设置的地方还有大模型,小模型,正面提示词,反面提示词,提示词强度,分辨率,迭代步数等等巨多的参数。
最近我在研究如何将人物照片转换成手办照片,在这里记录下制作流程和注意事项,以便日后参考。
这次实验的目的是将下面这张人物照片转换成相似的手办照片。

1、将照片导入标签提取器,获得提示词,并手工筛选和调整。
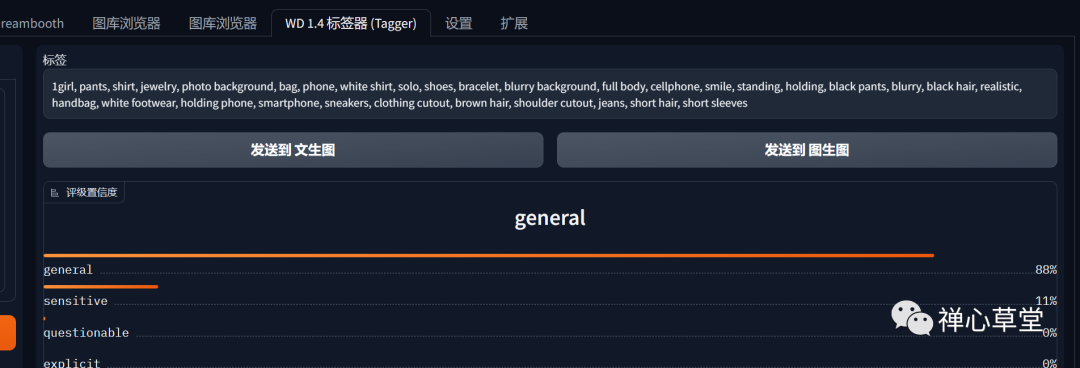
2、因为要做卡通手办图,这里选择“disneyPixarCartoon_v10(1)”大模型。在AI绘图中,正确的选择大模型是很重要的。将提示词加入到文生图的正向提示词内,并补充画质和风格相关词语。并随着出图效果不断调整提示词内容,最终固定。最终的正面提示词如下:
“1girl, realistic, smile,[realistic],[3d],(3dcg), ((octane render)), masterpiece, best quality, chibi,full body, pants, shirt, jewelry, photo background,1 bag,1 phone,white shirt,solo, shoes,bracelet, blurry background, full body,cellphone, smile, standing,holding, black pants,blurry, black hair, realistic, handbag,white footwear, smartphone, sneakers, brown hair,jeans,short hair,short sleeves, hold the phone in hand,in Exhibition Hall,gray background, Background blurring, light smile, Pretty Asian Girl, Both eyes open,”
负面提示词使用模版:
“ng_deepnegative_v1_75t,easynegative,bad_prompt_version2,deformed,missing limbs,amputated,pants,shorts,cat ears,bad anatomy,naked,no clothes,disfigured,poorly drawn face,mutation,mutated,ugly,disgusting,blurry,watermark,watermarked,oversaturated,obese,doubled face,b&w,black and white,sepia,nude,frekles,no masks, duplicate image,blur,paintings, sketches, (worst quality:2), (low quality:2), (normal quality:2), lowres, normal quality, monochrome, grayscale, bad anatomy,(fat:1.2), facing away, looking away,tilted head,lowres,bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worstquality, low quality,normal quality, jpegartifacts, signature, watermark, username,blurry,bad feet,cropped,worst quality, low quality, normal quality,jpeg artifacts,signature, watermark, bad eyes, red eyes, open mouth,(Cock-eye,:1.1), With closed eyes,”
此时生成的图片是这样的:

3、为了控制人物动作,将原图加入第一个controlnet,设置模型为openpose_full,选择向上设置分辨率,其他参数默认。看起来这样的动作就与原图很像了。

4、打开第二个controlnet并加入原图,设置模型为tile_resample,全部默认。这次就和原图更像了。

5、这里是关键一步,添加LORA模型:“blindbox_v1_mix”,权重选择1.25。现在生成的图片就比较像手办照片了。提示词里面也提前添加好了这个lora的唤醒咒语 “chibi,full body”。

6、开始放大图片分辨率,增加细节。将上图发送至图生图,选择面部修复(前面文生图时忘选了),放大4倍,重绘幅度为0.35,脚本选择终极SD放大,放大算法是R+A,接缝修复类型是H+i 。打开第一个controlnet并加入原图,设置模型为tile_resample,全部默认。打开第二个controlnet并加入原图,设置模型为reference_only,Style Fidelity设置为0.7,其他全部默认。最终效果见下图,脸的效果还可以,手还是有点崩了。后续再进一步完善吧。

本次绘图的过程中出现了几次报错,结尾部分的提示内容是“modules.devices.NansException: A tensor with all NaNs was produced in VAE. This could be because there’s not enough precision to represent the picture. Try adding --no-half-vae commandline argument to fix this. Use --disable-nan-check commandline argument to disable this check.” 这个问题的发生原因有待研究,通过在正向提示词中添加–no-half-vae可临时解决此问题。
本次绘图使用的外挂VAE模型是“Counterfeit-V2.5.vae”
文章使用的AI绘画SD整合包、各种模型插件、提示词、AI人工智能学习资料都已经打包好放在网盘中了,无需自行查找,有需要的小伙伴文末扫码自行获取。
写在最后
AIGC技术的未来发展前景广阔,随着人工智能技术的不断发展,AIGC技术也将不断提高。未来,AIGC技术将在游戏和计算领域得到更广泛的应用,使游戏和计算系统具有更高效、更智能、更灵活的特性。同时,AIGC技术也将与人工智能技术紧密结合,在更多的领域得到广泛应用,对程序员来说影响至关重要。未来,AIGC技术将继续得到提高,同时也将与人工智能技术紧密结合,在更多的领域得到广泛应用。
感兴趣的小伙伴,赠送全套AIGC学习资料和安装工具,包含AI绘画、AI人工智能等前沿科技教程,模型插件,具体看下方。

一、AIGC所有方向的学习路线
AIGC所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、AIGC必备工具
工具都帮大家整理好了,安装就可直接上手!

三、最新AIGC学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。


四、AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

若有侵权,请联系删除

















 4233
4233

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









