







怎么画出高质量的AI图像?
不管使用Stable Diffusion的文生图或图生图进行AI绘画,都可以用提示词描述相关图像效果,通过尝试不同提示词组合和参数,从而达成更好的AI绘图效果和创意。与其天天在网上找别人的提示词,不如自己学会写好提示词,读懂本篇攻略让你轻松驾驭SD提示词prompt。
目录
1 SD提示词语法格式
2 提示词技巧
3 SD提示词实战
一、SD提示词语法格式
提示词权重(prompt weight)
你在抄别人prompt作业的时候,里面是不是经常有一堆大小括号、冒号和数字,这其实就是在对某个提示词进行加权和降权的操作,从而改变提示词对图像的影响程度。另外提示词的先后顺序,越靠前的提示词影响程度也越大,通常先描述画风,再描述主题,最后是细节的描述。
加权
1 使用小括号“()”,可以对提示词权重提升1.1倍。
例如:“(1 girl)”代表“1 girl”权重提升1.1倍
2 小括号允许叠加多层。
例如:“((1 girl))”代表“1 girl”权重提升1.1*1.1=1.21倍
3 单层小括号加冒号,可以指定权重值。(推荐这种表达更为准确清晰)
例如:“(1 girl:1.5)”,指定“1 girl”权重提升1.5倍
4 使用大括号“{}”,提示词权重提升1.05倍,同时也允许叠加多层“{{}}”,但只有小括号才能指定权重值。
降权
1 使用中括号“[]”,可以对提示词权重除以1.1,降低0.9权重。
2 支持多层嵌套,但不支持指定权重中。
例如:“[[1 girl]]”,代表“1 girl”权重÷1.1÷1.1
快捷键操作
选中提示词,使用【ctrl】+↑ 或 ↓ ,能够给某个提示词快速加权和降权。
提示词混合语法格式
用“AND”或“|” 可以把两个提示词连接起来使用,表示的逻辑是这两个元素会交替出现,达成融合的效果。
例如:“yellow hair | green hair” 或 “yellow hair AND green hair” 画出黄色和绿色头发渐变效果,SD在处理的时候对黄色和绿色头发循环交替绘画。
渐变语法
1 “[from:to:when]”
例如:“[yellow:green:0.6]hair”,表示60%步骤先画黄色,后40%步骤画的绿色头发,黄渐变绿色。
2 “[to:when]”
例如:“[yellow:0.3]hair”,表示70%步骤不画,后30%步画黄色头发。
3 “[from::when]”
例如:“[yellow::0.3]hair”,表示70%步骤画黄色头发,后30%步骤不画。
*注意:当when<1时,表示迭代步骤的百分比,when>1时,表示具体迭代步数。
二、SD提示词技巧
正向提示词常用框架
很多提示词又臭又长,其实无非以下这个公式来写,你也可以轻松驾驭。
| 质量 | 起手通用提示词 | best quality,masterpiece, |
| 风格 | 绘画风格和构图 | style of Pixar, |
| 主体 | 人物、物体描述 | 1girl,full body |
| 场景 | 环境、点缀等 | park |
| 其他细节 | 视角、光线、lora插件等 | hair mercerizing |
*注意:触发某些lora需要加上必要的触发词。
关注公众号,私信“提示词”,获取提示词词库和风格库资源。
负向提示词
用来描述不需要出现的特征和元素的提示词,比如:“nsfw”成人内容。
通用负面起手提示词:
nsfw,lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry
提示词打包(Embedding)
有时候为避免AI出图质量和出现重影、多手多脚等问题,负面提示词会越写越多,而且针对不同的模型有针对的负面提示词还会不同,通常下载一些别人分享的embedding来对这些词打包,用少量的词替代一堆负面词。
常用的Embedding如下:
下载地址:https://civitai.com/models
安装目录:…\novelai-webui-aki-v3\embeddings
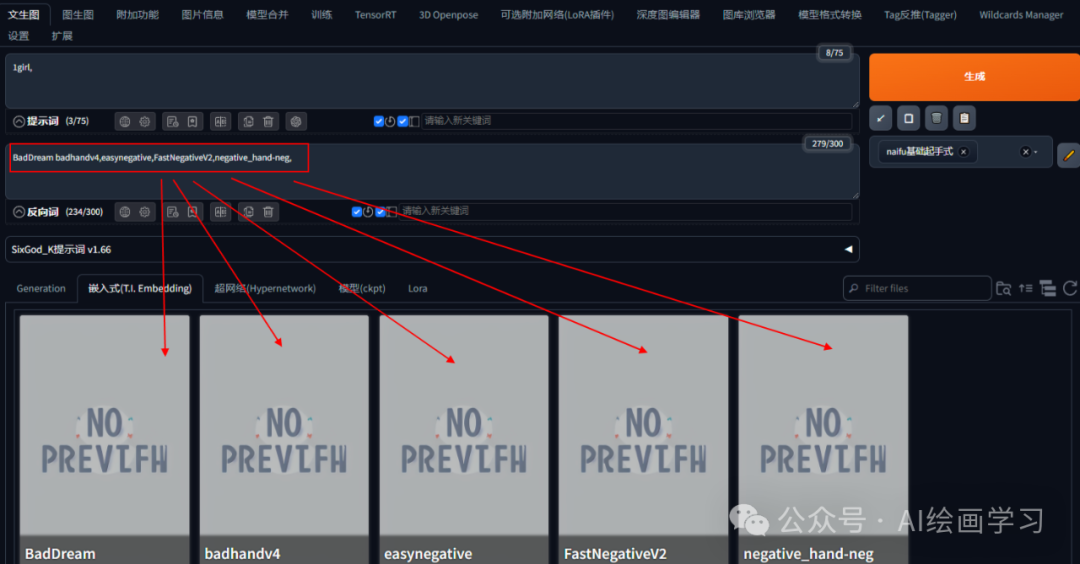
使用方法:提示词里用哪个点击哪个embeddings即可。
保存常用提示词
你还可以把常用的提示词保存在本地文件里,只需要下拉选择,就可以直接出图。
添加操作如下:
再次编辑内容:

提示词常用插件
帮助写提示词的插件有很多很多,常用插件推荐2个:(需要插件的小伙伴可到文末扫码找我拿!)
sd-webui-oldsix-prompt
地址:https://github.com/thisjam/sd-webui-oldsix-prompt.git
sd-webui-prompt-all-in-one
地址:https://gitcode.net/ranting8323/sd-webui-prompt-all-in-one
三、SD提示词实战
用今天学到的内容做几个练习吧!
1 画一个女孩黄绿色头发
提示词:“(highly detailed),1girl,yellow hair AND green hair”
参数设置:Steps: 20, Sampler: DDIM, CFG scale: 7, Size: 512x768, Model hash: 7f16bbcd80, Model: dreamshaper_4BakedVae, Clip skip: 2, Version: v1.8.0

2 黄色和绿色头发比例 2:1
提示词:“(highly detailed),1girl,2yellow hair AND 1green hair”
参数:Steps: 20, Sampler: DDIM, CFG scale: 7, Seed: 1523438208, Size: 512x768, Model hash: 7f16bbcd80, Model: dreamshaper_4BakedVae, Clip skip: 2, Version: v1.8.0

3 20%步骤先画黄色,再画绿色
提示词:“(highly detailed),1girl,[yellow:green:0.2] hair”
参数:Steps: 20, Sampler: DDIM, CFG scale: 7, Seed: 1523438208, Size: 512x768, Model hash: 7f16bbcd80, Model: dreamshaper_4BakedVae, Clip skip: 2, Version: v1.8.0

4 画一个星空女孩
提示词:
best quality,realistic,best quality,masterpiece,front view,cinematic,1girl,upper body,solo,stars in the eyes,messy floating hair,colored inner hair,Starry sky adorns hair,depth of field,
Negative prompt: nsfw,logo,text,BadDream,badhandv4 easynegative,FastNegativeV2,negative_hand-neg,ng_deepnegative_v1_75t,
参数:Steps: 30, Sampler: DPM++ 2M Karras, CFG scale: 7.5, Seed: 1174731701, Size: 512x768, Model hash: 7f16bbcd80, Model: dreamshaper_4BakedVae, Denoising strength: 0.2, Clip skip: 2, Hires upscale: 2, Hires upscaler: 4x-UltraSharp, Version: v1.8.0
****
AI绘画SD整合包、各种模型插件、提示词、AI人工智能学习资料都已经打包好放在网盘中了,有需要的小伙伴文末扫码自行获取。
关于AI绘画技术储备
学好 AI绘画 不论是就业还是做副业赚钱都不错,但要学会 AI绘画 还是要有一个学习规划。最后大家分享一份全套的 AI绘画 学习资料,给那些想学习 AI绘画 的小伙伴们一点帮助!
对于0基础小白入门:
如果你是零基础小白,想快速入门AI绘画是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以找到适合自己的学习方案
包括:stable diffusion安装包、stable diffusion0基础入门全套PDF,视频学习教程。带你从零基础系统性的学好AI绘画!

零基础AI绘画学习资源介绍
👉stable diffusion新手0基础入门PDF👈
(全套教程文末领取哈)

👉AI绘画必备工具👈

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉AI绘画基础+速成+进阶使用教程👈
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉12000+AI关键词大合集👈

这份完整版的AI绘画全套学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

















 610
610

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









