







简介
pandas遍历行和列效率最高的是apply方法,其次是使用迭代器遍历,apply方法在灵活性上不如使用迭代器遍历。使用迭代器有 for_ zip 、itertuples、iterrows、items四种方法,最慢的iterrow使用效率可以比 iloc等切片方法快300多倍。
结合资料和我自己的测试,5种方法效率中,apply>for_ zip>itertuples>items>iterrows。其中apply约为for_ zip的10倍,for_zip约为itertuples的15倍,itertuples约为iterrows的30倍。
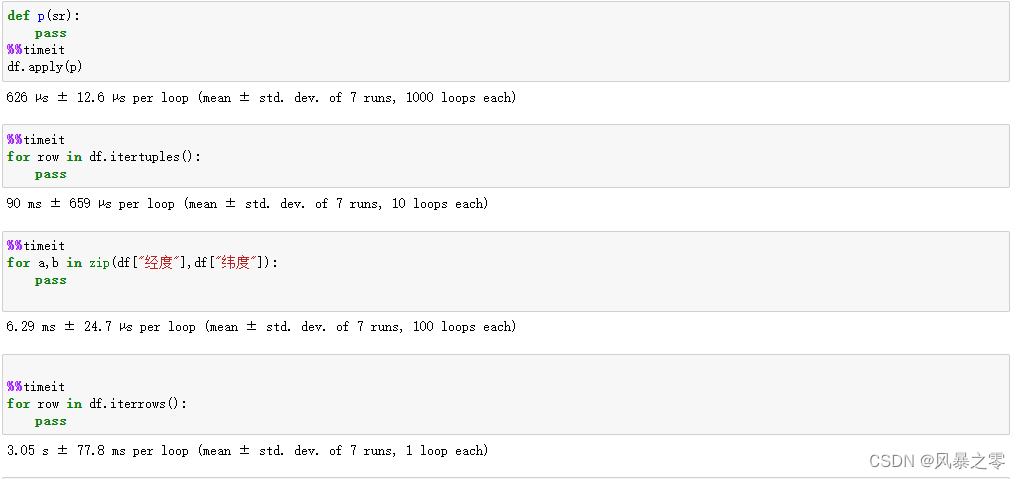
1、for_zip
可以按行或者列迭代。效率最高但是无法获取索引。
示例:
for a,b in zip(df["经度"],df["纬度"]):
pass
其中
zip(df[“经度”],df[“纬度”])
是一个元组(a,b)组成的迭代器,可以用list方法查看或者用next放法逐一输出。
2、itertuples
是按照行进行迭代,但是出来的结果保存为tuple;
for row in df.itertuples( 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1304
1304











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











