







huffman编码是重要的编码方式之一。作为一名程序员,应该要做到融会贯通,因此我在网上搜些资料看,发现几乎没有适合我等菜鸟级的文章,不是没有图解,就是不说明为什么要引入huffman编码,稀里糊涂,于是自己整理了一下,欢迎诸君拍砖。
Huffman是一种无损压缩方法:所谓无损就是不会有信息丢失,可以100%恢复原信号,像奈奎斯特恢复就是有损了;所谓压缩,就是可以占有更少的存储空间。
比如要发送三个字符:S1,S2,S3。我们可以这样编码:00,01,10。当然这是小数据,如果要发送的图片或是视频呢?比如一副高清图片,10M,在局域网上即使可以达到理论的10Mbps,也要1s,没法满足视频的最低帧频24fps。因此压缩非常重要,当然采用的压缩很多,huffman只是早期的一种而已,这就是Huffman的背景。
现在来看看它的原理:先不联系最优二叉树那套东西。基本原理是根据字符出现的概率确定其码子。即高概率的少码字,低概率的多码字。 举个例子吧:
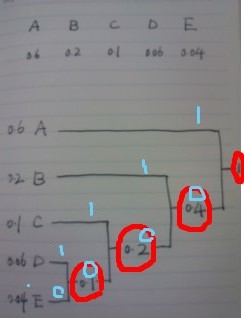
图 1
结合上图:
A B C D E 5个字符及其出现的概率。过程很简单:
First: 从上到下,根据概率由大到小排列;
Second: 俩俩合并,先合并概率低的,比如D E 概率最低,合并之,得到概率0.1,再寻找概率最低的俩部分,发现是C 和 DE,合并之,合并后,
标出新的 概率值 ,如图中红色圈起来的部分,直到合并完全;
Third: 标出0或1。如图中蓝色部分,低概率的给0(1也可以),概率相等的,就0和1随意了;
Last: 得到编码值:A:1,B:10;C:100; D:1000; E:0000。
整个编码过程完毕。以上就是Huffman编码的大体过程。好了,感受完其最基本的过程。我们再来完成最优二叉树(赫夫曼树)的代码编写,分为俩部分:第一部分为基本概念,第二部分为:代码的实现,并有测试结果。
huffman 树:带权路径最短的树。所谓带权路径,就是从该节点到树根的长度与节点上的权的乘积
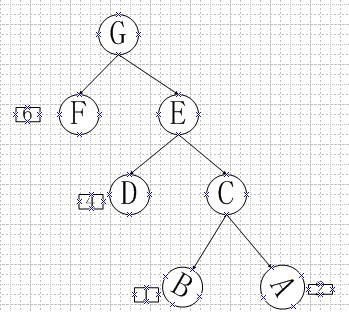
图 2
那么树的带权路径就是所有节点的带权路径之和,公式表示:
如上图:套公式:6*1+4*2+1*3+2*3
有了一开始部分的介绍,huffman二叉树的构造就很简单了,步骤:
1,找到权重最小的俩节点,合并最为一个新的节点,比如上面D,E合并,得到一个新的节点,暂且叫 做DE,则D,E作为子节点,DE作为父节点;
2,以DE代替D和E,DE的权重为D和E之和,重新第一步,直到所有节点都加入到二叉树中。
3,对于权重小的节点附0(或1),对于权重大的节点附1(或0)。
如把图1huffman的计算过程变成二叉树的 图形如下:
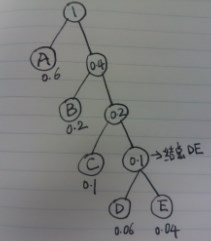
图 3
读者,把一开始的图1 ,旋转过来跟图 2 是一样的,因为原理一样。注意:huffman叶节点为n,需要2*n-1个节点来构成二叉树,树的节点的度为2(除去叶节点)。
第二部分:以一个例子开始: 权重W={5,29,7,8,14,23,3,11}.n=8.此例子为严蔚敏第159页的例子。
上代码:
/*
Coder Information
e_mail:shenganbeiyang@163.com
QQ:501968942
*/
#ifndef HUFF_H
#define HUFF_H
#include<string>
//定义一个结构体,包括节点的父节点和左右子节点
//字符的个数
const int maxnum=30;
typedef struct Tnode
{
char val;
int weight;
int parent;
int lchild;
int rchild;
}huffmanNode ,*huffmanTree;
class huffmanCoding
{
public:
//初始化最优二叉树(哈夫曼树)
huffmanCoding(huffmanNode * hn,int length);
//编码过程
void Selection(int);
void Encode(int);
//解码过程
// string deCode();
//deconstruction function
~huffmanCoding(){
for(int i=0;i<length;++i)
delete HC[i];
delete [] HC;
};
char** HC;//保存编码信息
private:
huffmanNode InitData[maxnum];
//char** HC;//保存编码信息
int length;
};
//constructor function.初始化二叉树
inline huffmanCoding::huffmanCoding(huffmanNode * hn,int length_)
{
HC=new char*[length_];//(sizeof(char*)*length);//new (char*)[length];
length=length_;
int i;
for( i=0;i<length;++i)
{
InitData[i]=hn[i];
InitData[i].parent=-1;
InitData[i].rchild=-1;
InitData[i].lchild=-1;
}
for(int j=i;j<2*length;++j)
{
InitData[j].lchild=-1;
InitData[j].rchild=-1;
InitData[j].weight=-1;
InitData[j].val='0';
InitData[j].parent=-1;
}
}
//编码huffman二叉树
inline void huffmanCoding::Selection(int codedlength)
{
int pos_1,pos_2;
pos_1=pos_2=-1;
int i;
for( i=0;i<codedlength;++i)
{
if(InitData[i].parent==-1)
{
pos_1=i;
break;
}
}
for(int k=pos_1+1;k<codedlength;++k)
{
if(InitData[k].weight<InitData[pos_1].weight&&InitData[k].parent==-1)
{
pos_1=k;
}
}
for(int j=0;j<codedlength;++j)
{
if(InitData[j].parent==-1&&j!=pos_1)
{
pos_2=j;
break;
}
}
for(int j=pos_2+1;j<codedlength;++j)
{
if(InitData[j].weight<InitData[pos_2].weight&&InitData[j].parent==-1&&j!=pos_1)
{
pos_2=j;
}
}
if(InitData[pos_1].weight<InitData[pos_2].weight)
{
InitData[codedlength].lchild=pos_1;
InitData[codedlength].rchild=pos_2;
InitData[pos_1].parent=codedlength;
InitData[pos_2].parent=codedlength;
InitData[codedlength].weight=InitData[pos_1].weight+InitData[pos_2].weight;
}
else
{
InitData[codedlength].lchild=pos_2;
InitData[codedlength].rchild=pos_1;
InitData[pos_1].parent=codedlength;
InitData[pos_2].parent=codedlength;
InitData[codedlength].weight=InitData[pos_1].weight+InitData[pos_2].weight;
}
}
inline void huffmanCoding::Encode(int len)
{
for(int i=len;i<2*len-1;++i)
{
Selection(i);
}
char*dc=new char[length];
for(int m=0;m<length;++m)
dc[m]='\0';
int start=0;
int tmp;
int p;
for(int m=0;m<length;++m)
{
for(tmp=m,p=InitData[m].parent;p!=-1;tmp=p,p=InitData[p].parent)
{
if(InitData[p].lchild==tmp)
dc[start++]='0';
else
dc[start++]='1';
}
dc[start]='\0';
HC[m]=new char[length];
start=0;
strcpy(HC[m],dc);
}
delete [] dc;
}
#endif
测试代码:
#include"huff.h"
#include<iostream>
using namespace std;
int main()
{
int i=0;
huffmanTree ht=new huffmanNode[8];
for(;i<8;++i)
{
ht[i].val='a'+i;
}
ht[0].weight=5;
ht[1].weight=29;
ht[2].weight=7;
ht[3].weight=8;
ht[4].weight=14;
ht[5].weight=23;
ht[6].weight=3;
ht[7].weight=11;
huffmanCoding hc(ht,8);
hc.Encode(8);
for(int i=0;i<8;++i)
cout<<hc.HC[i]<<endl;
return 0;
}
测试结果,即编码结果为:
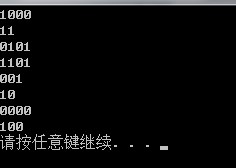
大家可能发现 与书上的结果不一样,严的书是 左节点必须为叶子节点,并且强制附0,我认为这不正确。huffman的定义不是这样的,如有异议可交流。















 3772
3772

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









