







索引对range查询 和 sort操作 到底有何影响?
最近在重构一个项目底层的mongodb存储,在设计索引的时候遇到了一些疑惑,在经过了多次试验和资料查阅后,总结出了下面的一个有代表性的试验和一些结论。
假设有一个collection中记录了公司员工的工龄,和他们相应的工资(我们的试验中有6个员工):
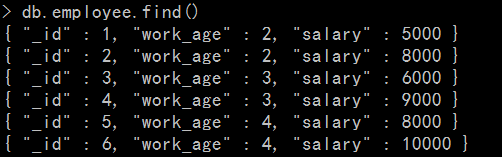
假设我们的日常管理中,需要找到工龄在3年以上(包括3年)的员工,并按照其工资由高到低排序输出:

对于这个query,应该如何建立索引,来实现查询速度的最优呢?
显然,我们需要建立work_age和salary两个字段的联合索引,但是两个字段谁先谁后呢?(注意在联合索引中,字段顺序起着至关重要的作用,详见:mongodb索引介绍)
第一种索引顺序:
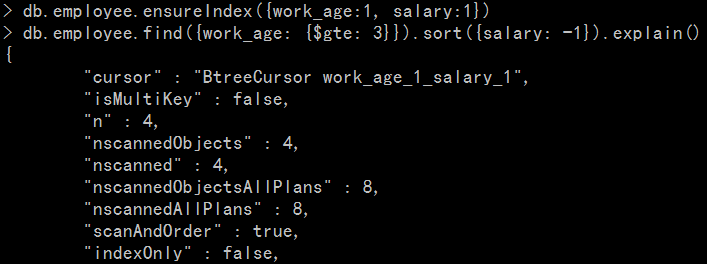
可以看到,这个索引对于range查询起到了非常好的优化作用(n = nscannedObjects = nscanned = 4, 可以算上是ideal index!详见这篇文章)
但是,explain()结果中的 scanAndOrder是"true"... 对于大量数据来讲,这是非常可怕的,意味着mongodb会将docs全部载入内存进行重新排序。
其实这是非常好理解的。因为我们建立的 索引节点的排序,是先按照work_age排序,相同的work_age再按照salary排。也就是说这四个索引节点的排序 如下:
{ "work_age" : 3, "salary" : 6000 } -> { "work_age" : 3, "salary" :9000 } -> { "work_age" : 4, "salary" :8000 } -> { "work_age" : 4, "salary" :10000 }
因此在索引中,salary并不是全局有序的,无法在输出结果的时候,直接利用。需要在输出前再重新做全局排序。
第二种索引顺序:
注意要先把第一个索引删掉。
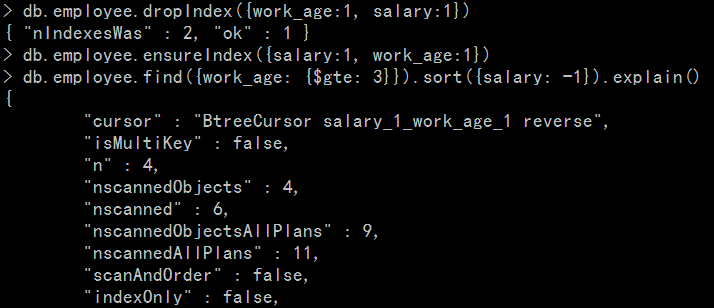
可以看到,这次的n变成了6,不如之前的ideal index.
可庆的是, scanAndOrder变成了false,无需再重新排序。
这是因为,这次索引中的节点顺序变成了:
{"work_age" : 2, "salary" : 5000 } (这条doc不满足查询条件)
{"work_age" : 3, "salary" : 6000 }
{"work_age" : 2, "salary" : 8000 } (这条doc不满足查询条件)
{"work_age" : 4, "salary" : 8000 }
{"work_age" : 3, "salary" : 9000 }
{"work_age" : 4, "salary" : 10000 }
mongodb 在做查询的时候,会依次遍历索引中的所有节点,这样可以保证结果 对于salary 依然 是全局有序的
遍历过程中,会利用索引中的work_age数值,对那两个不满足条件的doc进行过滤。
因此,这个联合索引并没有对range操作起优化作用(其实仅仅起到了一点点作用,那就是索引中保存了work_age的值,不用再到原doc中去 查work_age的值,因此nscannedObjects降低为4)
综上所述,两种字段顺序的索引,对查询起到的优化作用是大大不同的。
如何取舍,需要根据实际的情况判断:
在大多数情况下,建索引时应该选取第二种顺序,也就是sort字段在range字段之前。因为大量数据在内存中的sort操作可能会拖垮cpu和内存。
但如果range的范围可以将doc的”基数“过滤到足够小,则应当采取第一种索引顺序,将range字段提到sort字段之前。因为第二种索引顺序意味着对整个索引全部扫描一遍。

















 1222
1222

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









