







词嵌入
维基百科上关于词嵌入的定义:Word embedding是一组语言模型和自然语言处理中特征学习技术的的总称,词汇中的单词(也可能是短语)被映射到相对于词汇量的大小(“连续空间”)而言低维空间的实数向量。
参考文章:《How to Generate a Good Word Embedding?》导读
- 语料对词向量的影响比模型的影响要重要得多,语料越纯越好。
参考文章:Deep Learning in NLP (一)词向量和语言模型
- NLP 中最直观,也是到目前为止最常用的词表示方法是 One-hot Representation,这种方法把每个词表示为一个很长的向量。这个向量的维度是词表大小,其中绝大多数元素为 0,只有一个维度的值为 1,这个维度就代表了当前的词。存在一个重要的问题“词汇鸿沟”现象:任意两个词之间都是孤立的。
- Deep Learning 中一般用到的词向量是Distributed Representation。最大的贡献就是让相关或者相似的词,在距离上更接近了。
- C&W的论文主要目的不是生成一份好的词向量,甚至不想训练语言模型,而是要用这份词向量去完成NLP里面的各种任务,比如词性标注、命名实体识别、短语识别、语义角色标注等等。词向量训练方法也有所不同,没有去近似地求
P(wt|w1,w2,…,wt−1)
,而是直接去尝试近似
P(w1,w2,…,wt)
。在实际操作中,并没有去求一个字符串的概率,而是求窗口连续
n
个词的打分
f(wt−n+1,…,wt−1,wt) 。打分 f 越高的说明这句话越是正常的话;打分低的说明这句话不是太合理。C&W 就直接使用 pair-wise 的方法训练词向量。具体的来说,就是最小化:∑x∈X∑w∈Dmax{0,1−f(x)+f(x(w))} 。 X 为训练集中的所有连续的 n 元短语,D 是整个字典。第一个求和枚举了训练语料中的所有的 n 元短语,作为正样本。第二个对字典的枚举是构建负样本。x(w) 是将短语 x 的最中间的那个词,替换成w 。 f(x) 是对正样本的打分, f(x(w)) 是对负样本的打分。最后希望正样本的打分要比负样本的打分至少高1分。C&W的输出层只有一个节点,表示得分。
参考文献:Deep Learning, NLP, and Representations
- 词嵌入 W: words→Rn 是一个参数化函数,映射某种语言的词到高维空间(可能是200或500维)。
- 通常的技巧——在任务A中学习一个好的表达,然后用于任务B——是深度学习工具箱的一个主要技巧。
- 替代学习表达一种数据的方法用于多种类型任务,可以学习映射多种数据到一个单一表达的方法。如双语词嵌入,用同样的方法训练词嵌入,用额外的属性:意思相近的词彼此靠近来优化。
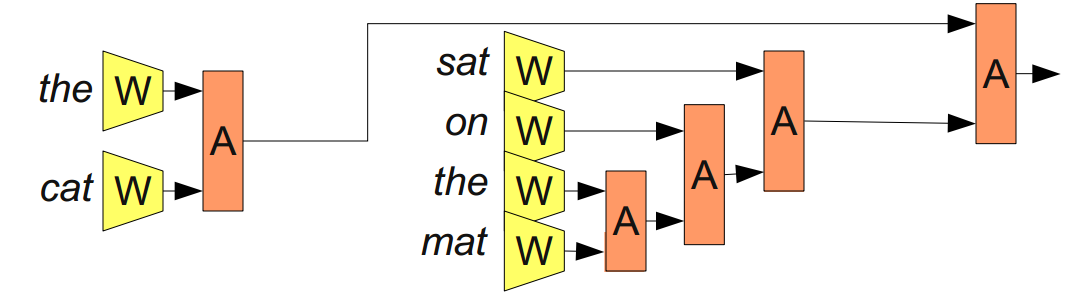
- 递归神经网络(Recursive Neural Networks):“the cat sat on the mat”,加括号划分成:”((the cat) (sat (on (the mat))”,对应的递归神经网络:
称为递归神经网络是因为:一个模块的输出,到另一个相同类型的模块。也称为树状神经网络。















 4228
4228

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









