







 参考链接论文链接:https://arxiv.org/pdf/1508.04025v5.pdf项目链接: https://github.com/pytorch/fairseq模型(model):【1】Neural Machine Translation(NMT):神经机器翻译(NMT)是直接用神经网络去模拟条件概率:p(x∣y)p(x|y)p(x∣y)NMT一般由两个部分组成:...
参考链接论文链接:https://arxiv.org/pdf/1508.04025v5.pdf项目链接: https://github.com/pytorch/fairseq模型(model):【1】Neural Machine Translation(NMT):神经机器翻译(NMT)是直接用神经网络去模拟条件概率:p(x∣y)p(x|y)p(x∣y)NMT一般由两个部分组成:...
参考链接
模型(model):
【1】Neural Machine Translation(NMT):
- 神经机器翻译(NMT)是直接用神经网络去模拟条件概率: p ( x ∣ y ) p(x|y) p(x∣y)
- NMT一般由两个部分组成: e n c o d e r + d e c o d e r encoder+decoder encoder+decoder, e n c o d e r encoder encoder部分读入源句子输出该句子的表示 (representation S S S), d e c o d e r decoder decoder部分接受 e n c o d e r encoder encoder部分的输出+ d e c o d e r decoder decoder已经输出的目标词作为输入并输出一个目标词。因此条件概率可以分解为: l o g p ( y ∣ x ) = ∑ x = 1 m l o g p ( y j ∣ y < j , s ) logp(y|x) = \sum_{x=1}^mlogp (y_j|y_{<j},s) logp(y∣x)=x=1∑mlogp(yj∣y<j,s)
- 用 d e c o d e r decoder decoder去模拟该条件概率,因此可以进一步写作: l o g p ( y ∣ x ) = s o f t m a x ( g ( h j ) ) logp(y|x)=softmax(g(h_j)) logp(y∣x)=softmax(g(hj)) g g g函数的输出向量的维数=词汇表的大小; h j h_j hj是RNN隐藏状态向量,其公式如下: h j = f ( h j − 1 , s ) h_j = f(h_{j−1}, s) hj=f(hj−1,s) f f f是RNN的单元可以是:标准的RNN单元、GRU单元和LSTM单元。
- 模型图:
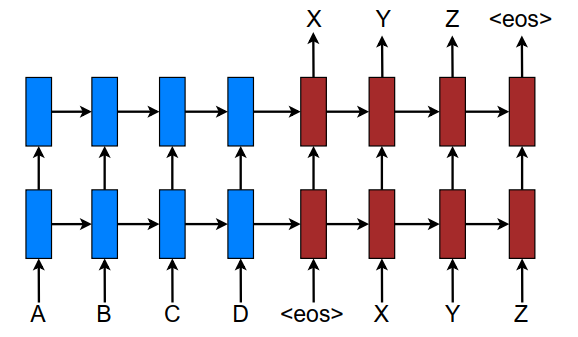
- 这篇论文使用的模型是多层的LSTM+Attention机制;损失函数(目标函数): J t = ∑ ( x , y ) ∈ D − l o g p ( y ∣ x ) J_t =\sum_{(x,y)∈D} − log p(y|x) Jt=(x,y)∈D∑−logp(y∣x) D D D是语料库
【2】Attention-based Models
-
论文中讲了两种模型: g l o b a l global global 和 l o c a l local local;两个模型图如下:

-
Global Attention:
- 模型图正如上图所示现在解释一下里面的变量:
- c t c_t ct:上下文向量;生成它是需要考虑 e n c o d e r encoder encoder的所有隐藏层状态向量 h t ‾ \overline{h_t} ht
- a t a_t a
- 模型图正如上图所示现在解释一下里面的变量:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









